

The BMW Tensorflow Object Detection Training GUI is already installed on your computer and you have successfully mastered the extensive instructions. Now follows the explanation of how to run the Training Suite for the first time. I will also go into a few optimizations so that the training data from the Labeltool Lite is directly available in the Training Suite for training the neural networks. The user only has to teach the pre-trained neural networks his technical requirements embodied by the previously created training data. Thus, it is possible to achieve excellent results without being an AI professional or having to invest a lot of resources in hardware, energy, training data and special AI knowledge.
Run Training Suite
After everything has been configured and the images have been built, it is time to run the Training Suite for the first time. Again, a distinction is made between the command for the GPU and CPU version. Therefore, the two different calls are shown below.
Start GPU version
Command: sudo docker-compose -f run_gpu.yml up
Start CPU version
Command: sudo docker-compose -f run_cpu.yml up
The output in the terminal window should now look like the following figure for the Training Suite in the GPU version
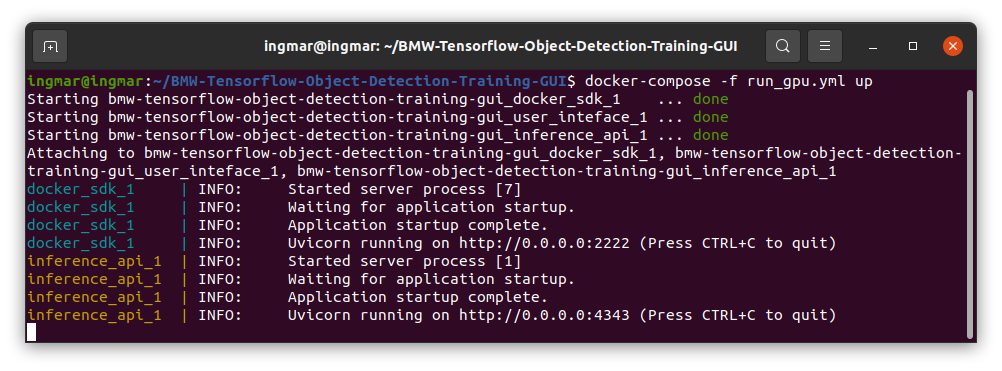
No Code AI Pipeline start training suite gpu
Now the Training Suite is started and can be opened via the IP address of the computer followed by the port <IP address>:<port>.
Example URL: 192.168.2.174:4200
In the browser (please always use the Chrome browser) the Training Suite is now visible and should look like this
Note: Port
The port via which the Training Suite frontend can be reached can also be adjusted in run_gpu.yml or run_cpu.yml. The change must then be made in line 21 in the ports section.
Not all parameters are set yet so that the AI pipeline as such works across Labeltool Lite and Training Suite. As a last point, the storage location of the training data must be manually adjusted in Labeltool Lite. Otherwise, no data will be available for training the neural networks in the Training Suite automatically after labeling.
Storage location of the training data in the Training Suite
In order for the images that are provided with labels in Labeltool Lite to be automatically available in the Training Suite for training the neural networks, these images and their labels must be located in the following target path. This is because it is precisely in this path that the Training Suite checks whether training images are available or not.
Target-path: /home/<username>/BMW-Tensorflow-Object-Detection-Training-GUI/datasets
Therefore, the images must now be copied from Labeltool Lite to the Training Suite. The images and their labels are currently still in Labeltool Lite in the following file path.
Source-path: /home/<username>/BMW-Labeltool-Lite/data/training-data
Now copy the folders with the images that are in the source path (Labeltool Lite) to the target path (Training Suite). You can use the Midnight Commander for this purpose, for example.
Training Data Management Labeltool Lite
So that in the future the copying of the training data from the Labteltool Lite into the Training Suite is no longer necessary and especially so that the training data does not have to be stored twice on the computer, the path to the training data in the Labeltool Lite should now be adapted. This creates a continuous AI pipeline with a single storage location for the training data within the Training Suite.
Note: Storage location of the images
My experience has shown that when about 435 users use Labeltool Lite, large amounts of training data are accumulated. Therefore, depending on the degree of use of the No-Code AI pipeline, a drive with large capacity and fast read access would be highly recommended for storing the images. This is because it is the only way to efficiently feed the training suite with the training data later on when training the neural networks. The configuration of the storage location for the images or training data will be discussed in more detail below.
The following figure shows exactly this management of the training data via a central storage location. The Labeltool Lite on the left side of the picture shares the same database with the Training Suite on the right side of the picture. The difference is that the Labeltool Lite also has write access to the folder in order to be able to store the labels of the images there. The Training Suite only accesses the folder with the images and labels for the training of the neural networks.
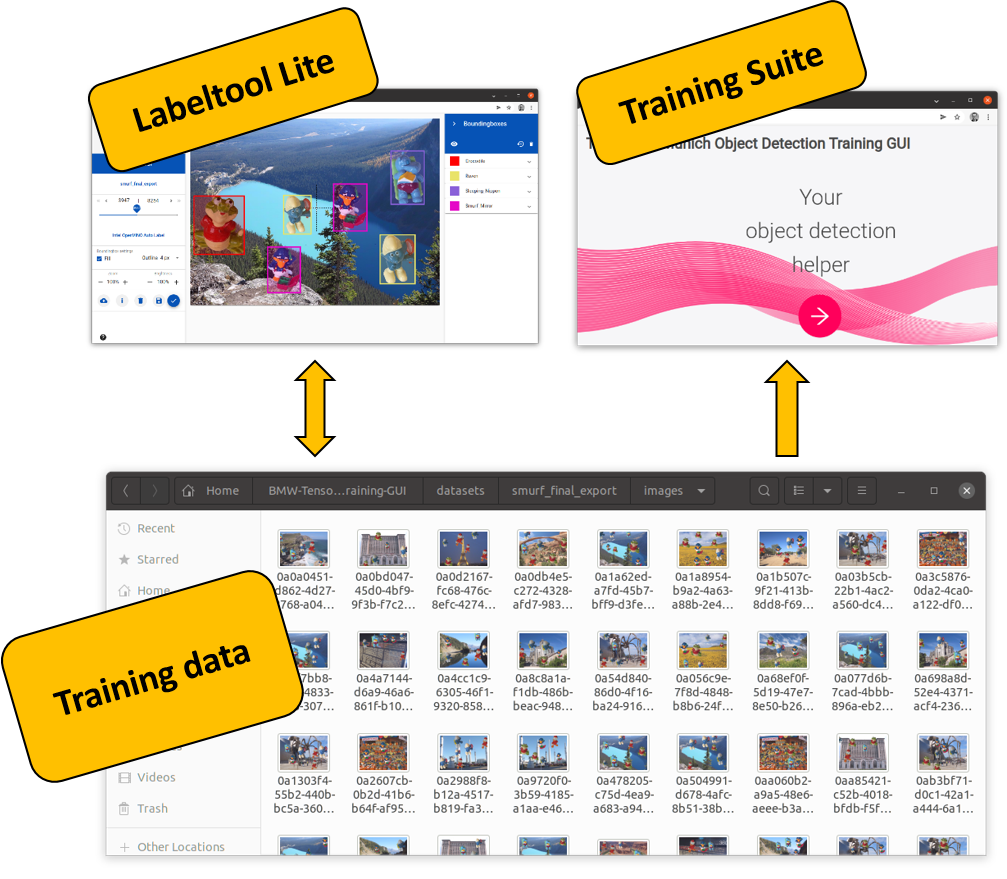
No Code AI Pipeline training data management
In order for Labeltool Lite to recognize the new storage location within the Training Suite, this path must be stored in Labeltool Lite. For this purpose, the configuration file docker-compose.yml of the Labeltool Lite must be adapted.
Now store the path for where the training data is located in the docker-compose.yml file. The configuration file is located in the following path and you can open it, for example, with the text editor Nano in the terminal window.
Path: /home/<username>/BMW-Labeltool-Lite/docker-compose.yml
The command to open the docker-compose.yml file in the terminal window with the text editor NANO is as follows.
Command: nano ~/BMW-Labeltool-Lite/docker-compose.yml
The Training Suite has been downloaded to the folder /home/<username>/BMW-BMW-Tensorflow-Object-Detection-Training-GUI/ as described in the previous section. In this path of the Training Suite there is a subfolder named datasets. In this folder are now and in the future the images, i.e. the training data that are needed for the training of the neural networks. Also, all images that are to be provided with labels from the Labeltool Lite will be stored here in the future.
Therefore, this path must be stored in the docker-compose.yml file of the Labeltool Lite so that the Labeltool Lite and the Training Suite share this folder.
Thus, the path to be adjusted in the docker-compose.yml to the training data is as follows.
Path: /home/<username>/BMW-Tensorflow-Object-Detection-Training-GUI/datasets
Now this path pointing to the training data is deposited as in the volumes section of the docker-compose.yml file. In the following figure in line 14 you can see exactly the adjustment you have to make. The placeholder <username> must be replaced by the username you use so that the path is really valid.
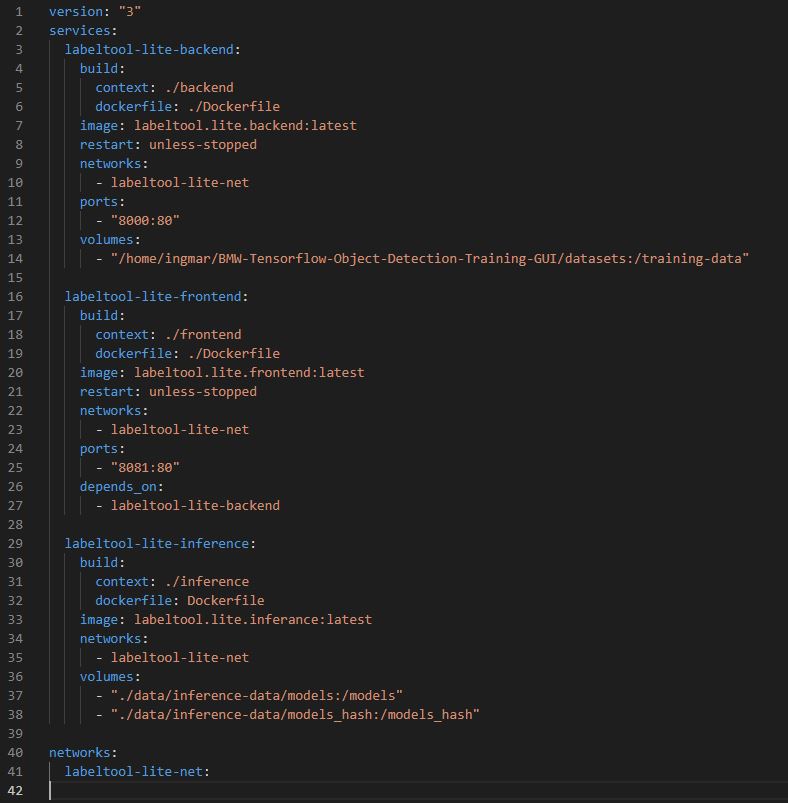
No Code AI Pipeline path training data
If the path to the images is stored in the docker-compose.yml file of the Labeltool Lite as described, the Labeltool Lite and the Training Suite share the same database for labeling the images and for training the neural networks.
It can happen that after adjusting a configuration like the path in the previous case, this adjustment is not taken over and the Labeltool Lite does not work properly anymore. If this happens then the Labeltool Lite must be rebuilt with the following build command.
The command that helps in such a case looks like this.
Command: sudo docker-compose build –no-cache
A machine-built and ready-labeled dataset of the small figures is available via the following link. This dataset contains 1750 images but still has the weakness that the figures were all photographed from only one perspective. However, the dataset shows how many thousands of datasets can be generated in a simple way using the tools of the TechOffice Munich of BMW AG which can be used for training a neural network.
Download URL: https://www.ai-box.eu/smurf_augment_export.zip
This means that a better neural network can now be trained with this larger data set, but it still functions in a very limited way.
Here again, it must be clear to them that it is not the tools that are valuable and the AI pipeline built from them, but that the data that can be used for the training of neural networks represent the actual value. This still requires a rethinking, especially in Germany.
In another article, a video is anonymized with these small figures and it can be seen that when changing the perspective, the neural network trained with this data still has weaknesses in recognition.
Summary and space requirements
With the completion of this tutorial, the Training Suite is configured and installed. You are now one step closer to being able to use the No-Code AI pipeline. In the following article you will learn how to use the Training Suite from the training of a neural network to the evaluation of information in a prediction image.
The space requirement on the system drive for the additionally installed software measured up to here amounts to approx. 1.5 GB.
| Initial free memory | Current free memory | Consumed memory |
| 20,3 GB | 21,8 GB | 1,5 GB |
Article Overview - How to set up the AI pipeline:
AI Pipeline - Introduction of the tutorialAI Pipeline - An Overview
AI Pipeline - The Three Components
AI Pipeline - Hardware Basics
AI Pipeline - Hardware Example Configurations
AI Pipeline - Software Installation of the No-Code AI Pipeline
AI Pipeline - Labeltool Lite - Installation
AI Pipeline - Labeltool Lite - Preparation
AI Pipeline - Labeltool Lite - Handling
AI Pipeline - Tensorflow Object Detection Training-GUI - Installation
AI Pipeline - Tensorflow Object Detection Training GUI - Run
AI Pipeline - Tensorflow Object Detection Training GUI - Usage
AI Pipeline - Tensorflow Object Detection Training GUI - SWAGGER API testing the neural network
AI Pipeline - AI Pipeline Image App Setup and Operation Part 1-2
AI Pipeline - AI Pipeline Image App Setup and Operation Part 2-2
AI Pipeline - Training Data Download
AI Pipeline - Anonymization-Api







{kind=link}
The tutorial offers a clear and practical guide for setting up and running the Tensorflow Object Detection Training Suite. Could you elaborate on how the system handles updates or changes to the training data after the initial setup?