
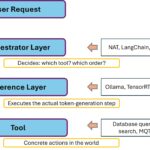
Agent-Orchestrierung ist konzeptionell genau der Sprung, der aus „LLM-Inferenz” tatsächlich „intelligente Anwendungen” macht. Ein funktionierendes NAT-Setup mit Ollama habe ich mir wie in meinem Blogbeitrag hier “NeMo Agent Toolkit auf der RTX A6000 Ada – vom Inferenz-Layer zum Orchestrator-Layer” beschrieben bereits aufgesetzt. Jetzt möchte ich schrittweise von der Basis bis zu komplexen Multi-Agent-Mustern das Vorgehen und die Architektur hier beschreiben.
Was bedeutet „Orchestrierung” eigentlich?
Im NeMo Agent Toolkit-Kontext und verwandten Ansätzen bezeichnet Orchestrierung die Koordination mehrerer Komponenten zu einer sinnvollen Gesamtarbeit. Diese Komponenten können sein:
- Tools (Funktionen, die der Agent aufruft, z. B.
wikipedia_searchoder auch dieDate_Time-Funktion) - LLMs (verschiedene Modelle für verschiedene Aufgaben abhängig von ihren Fähigkeiten)
- Agenten (in sich abgeschlossene ReAct-Loops, die selbst als „Tools” für übergeordnete Agenten dienen können)
- Memory (Kurzzeit- und Langzeit-Gedächtnis zwischen Aufrufen)
Ich möcht hier die drei grundlegende Orchestrierungs-Muster vorstellen die ihr mit einem NAT-Setup und ReAct ohne weiteres bauen könnt:
Muster 1: Single Agent mit Tool-Auswahl

Single Agent mit Tool-Auswahl
Muster 2: Sequential Pipeline

Sequential Pipeline
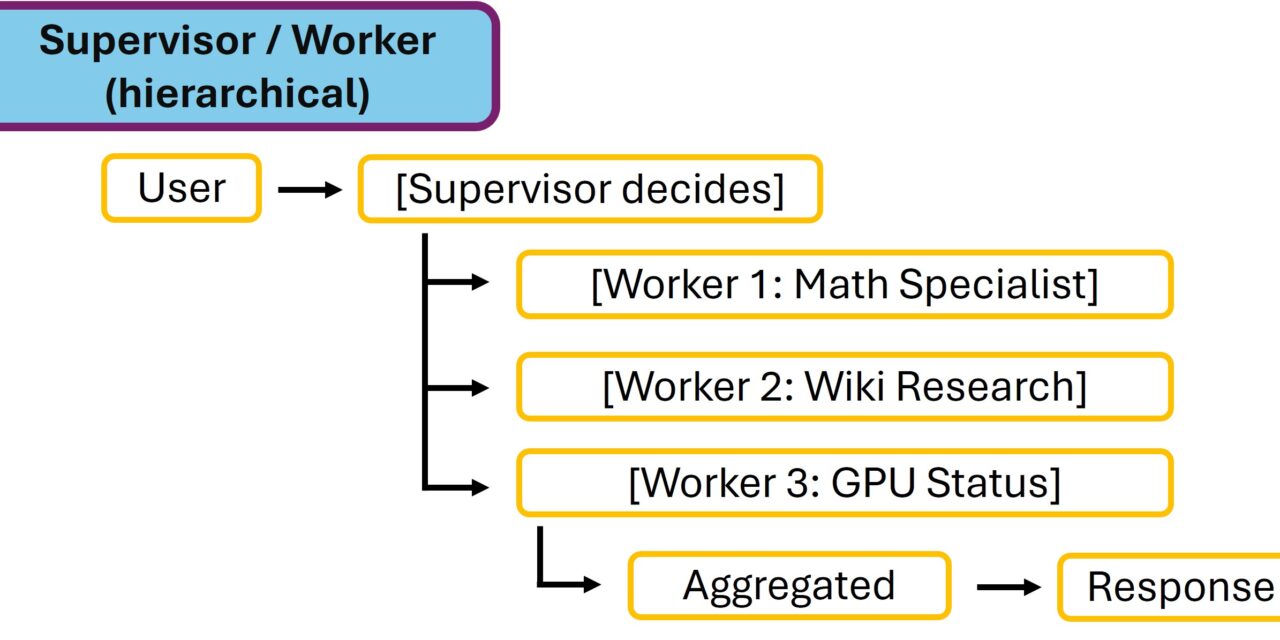
Muster 3: Supervisor / Worker (hierarchisch)
Supervisor / Worker (hierarchisch)
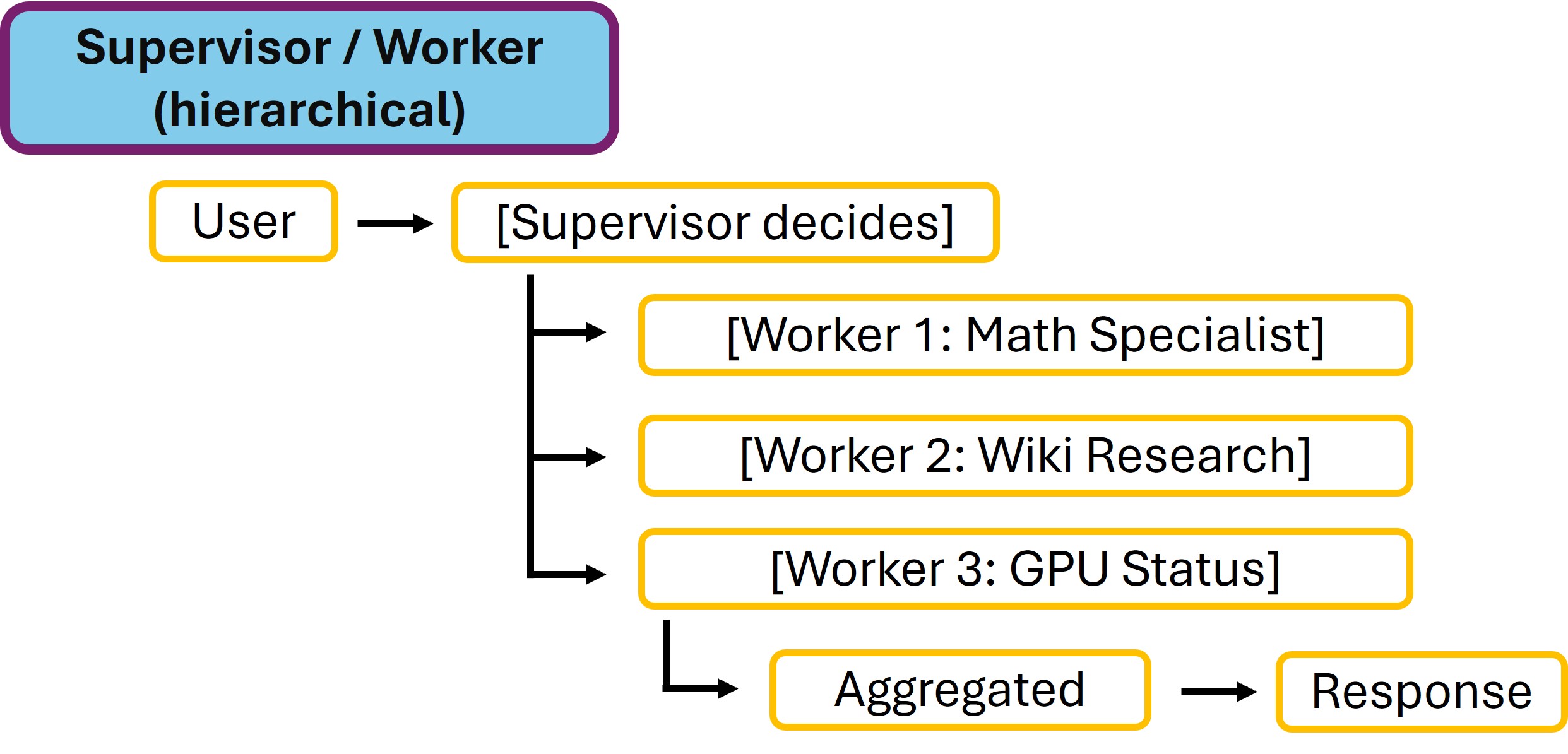
Muster 4: Parallel mit Aggregation
Parallel mit Aggregation
Das wichtigste konzeptionelle Detail in NAT: Alles ist eine Function. Ein Tool ist eine Function. Ein Agent ist eine Function. Ein ganzer Workflow ist eine Function. Das macht NAT enorm komponierbar. Wir kennen dieses Konzept bereits aus einigen anderen agentischen Tools. Ein Workflow kann mit dieser Architektur einen anderer Workflow als Tool nutzen, ohne dass es einen architektonischen Unterschied gibt. Das ist extrem flexibel und leistungsstark.
Die ReAct-Schleife im Detail
Bevor wir Multi-Agent-Setups bauen, müssen wir verstehen, was in der einzelnen Schleife passiert. Wenn du nat run --config_file ollama_agent.yml --input "..." aufrufst, läuft folgendes ab:
- Prompt-Composition
Dersystem_promptwird mit{tools}und{tool_names}ausgefüllt.
Dann an das LLM geschickt: “Hier sind deine Tools, hier ist die Frage.” - Iteration 1
1. LLM generiert: “Thought: … Action:tool_XAction Input: {…}”
2. NAT parsed das Format, extrahierttool_Xund seine Inputs
3. NAT rufttool_X(...)auf — entweder einen Python-Funktionscall,
4. einen HTTP-Request, oder einen Datenbank-Query
5. Das Ergebnis wird als “Observation: …” an den Context angehängt - Iteration 2 (wenn nötig)
1. LLM bekommt den erweiterten Context (Thought+Action+Observation)
2. Entscheidet: noch ein Tool oder finale Antwort?
3. Wenn Tool: weiter wie oben. Wenn fertig: “Final Answer: …” - Output
NAT extrahiert “Final Answer:” und liefert diese zurück.
Der kritische Punkt: das hinter dem Prozess liegende LLM trifft seine Entscheidung allein anhand der Tool-Beschreibungen. Wenn wikipedia_search als „Search Wikipedia for facts” beschrieben ist und current_datetime als „Returns the current date and time”, dann lernt das LLM aus diesen Beschreibungen, wann es welches Tool nutzen soll. Daher ist es sehr wichtig das die Tools eindeutig und ordentlich beschrieben sind. Eine Tool-Doppelung mit nicht eindeutig unterscheidbare Beschreibung sollte vermieden werden wenn grundlegend unterschiedliche Ergebnisse zurück geliefert werden von den betroffenen Tools.
Experiment 1: Tool-Beschreibung beeinflusst Tool-Auswahl
Ich gehe jetzt davon aus, dass Du ein läuffähiges NeMo Agent Toolkit Setup im Zugriff hast. Lass uns jetzt einmal in der Praxis den Ablauf genau anschauen. Lege folgenden Workflow an:
Du bist in der aktiven virtuellen Umgebung Deines NAT Setups. Führe jetzt die beiden folgenden Befehle aus:
Befehl: cd ~/nat-playground/configs
Jetzt legst Du den folgenden experiment1_tool_descriptions.yml Workflow an.
Befehl: nano experiment1_tool_descriptions.yml
Da es hier viel zu viel ich nenne es einmal Coding wäre gibt es die Workflow Beschreibung in meinem GitHub Repository passend zu dem Projekt hier.
GitHub Repository: https://github.com/custom-build-robots/configs/experiment1_tool_descriptions.yml
Jetzt hast Du den Inhalt in den Workflow kopiert und mit STRG + X gefolgt von einem Y gespeichert. Ollama läuft als Inferenz-Server und jetzt führst Du den Workflow wie folgt dreimal aus.
- Frage 1: Zeit-bezogen → sollte current_datetime wählen
- Befehl:
nat run --config_file experiment1_tool_descriptions.yml--input "Wie spät ist es?"
- Befehl:
- Frage 2: Wissens-Frage → sollte wikipedia_search wählen
- Befehl:
nat run --config_file experiment1_tool_descriptions.yml--input "Was war die Schlacht im Teutoburger Wald?"
- Befehl:
- Frage 3: Kombiniert → sollte BEIDE nacheinander aufrufen
- Befehl:
nat run --config_file experiment1_tool_descriptions.yml--input "Was ist heute für ein Tag und welches historische Ereignis passierte am 13. März 1986?"
- Befehl:
Schau dir die Traces an. Bei Frage 3 wirst du wahrscheinlich beobachten, dass der Agent das Datum-Tool nicht für „13. März 1986″ nutzt (das Datum ist ja in der Frage), sondern nur für „heute”. Das ist exakt der Punkt das Modell versteht aus dem Tool-Namen und Description, was wann nützlich ist.
Lehre: Tool-Beschreibungen sind dein wichtigster Hebel. Wenn dein Agent das falsche Tool wählt, ist meistens nicht das Modell „dumm”, sondern die Description unklar.
Hands-on: Ein eigenes Python-Tool schreiben
Jetzt kommen wir endlich zum spannenden Teil. Bauen wir ein GPU-Status-Tool, das nvidia-smi auf deinem Server abfragt und die Werte zurückgibt. Damit kannst du deinen Agent fragen: „Wie ist meine GPU gerade ausgelastet?” und er bekommt von nvidia-smi eine konkrete Antwort von deiner Hardware.
Schritt 1: Das Python-Tool schreiben
Jetzt werden wir aus dem config Ordner unserer nat-playgrounds heraus gehen und in den tools ordner einsteigen. Dort legen wir unser neues Tool das wir jetzt bauen möchten ab. Dazu bitte die folgenden Befehle ausführen.
Befehl: cd ~/nat-playground/tools
Befehl: mkdir -p gpu_status
Befehl: cd gpu_status
Befehl: nano gpu_status_tool.py
Jetzt musst Du die folgende Tool Beschreibung die ich hier als Python Programm mit dem Namen gpu_status_tool.py datei bereitstelle von GitHub herunter laden.
GitHub Repository: https://github.com/custom-build-robots/gpu_status/gpu_status_tool.py
Jetzt den Inhalt also den Python-Code in die Datei einfügen so das Du das Tool im Ordner ~/nat-playground/tools/gpu_status am Ende abgelegt hast. Mit Strg + X gefolgt von einem Y speichern.
Schritt 2: Das Tool als Package registrieren
NAT erkennt Custom-Tools über Python-Entry-Points. Wir brauchen eine kleine pyproject.toml:
Befehl: ~/nat-playground/tools/gpu_status
Befehl: nano pyproject.toml
Auch hier wieder das gleiche vorgehen. Den Inhalt der pyproject.toml gibt es hier auf GitHub.
GitHub Repository: https://github.com/custom-build-robots/gpu_status/pyproject.toml
Schritt 3: Tool in der aktiven venv installieren
Bitte jetzt in den nat-playground Ordner wechseln für die Tool Registrierung.
Befehl: cd ~/nat-playground
Wenn die virtuelle Umgebung nicht aktiv sein sollte dann bitte diese aktivieren.
Befehl: source .venv/bin/activate
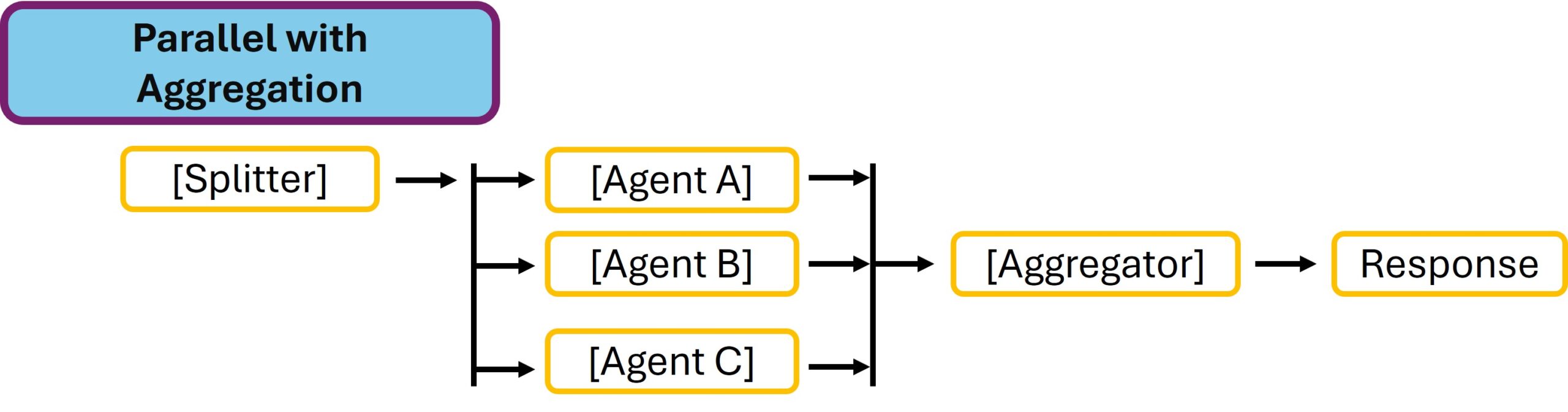
Mit dem jetzt folgenden Befehl wird das Tool gpu_status installiert.
Befehl: uv pip install -e tools/gpu_status
Der -e Flag bedeutet „editable install” das ist super praktisch denn wenn du am Python-Code etwas änderst, brauchst du das Tool nicht neu zu installieren.
Bei mir sah die Ausgabe im Terminal-Fenster dann wie folgt aus.
NAT GPU NVIDIA-SMI – tool
Schritt 4: Verifizieren, dass NAT das Tool sieht
Jetzt kommt der spannende Teil kennt unser NAT-Setup das neue Tool? Dazu führe den folgenden Befehla us.
Befehl: nat info components -t function | grep -i gpu
Bei mir sah die Ausgabe wie hier nachfolgenden Bild gezeigt aus.

NAT GPU NVIDIA-SMI – tool installed
Schritt 5: Workflow mit dem neuen Tool bauen
Jetzt um den neuen Workflow zu bauen müssen wieder zurück in den Ordner configs.
Befehl: cd ~/nat-playground/configs
Den neuen Workflow legen wir mit dem folgenden Befehl an.
Befehl: nano experiment2_gpu_agent.yml
Den Workflow selber findest Du wieder auf meinem GitHub Repository. Füge den Inhalt in die experiment2_gpu_agent.yml ein und speichere die Datei anschließend ab.
GitHub Repository: https://github.com/custom-build-robots/configs/experiment2_gpu_agent.yml
Schritt 6: Den ersten Hardware-Agent ausführen
Jetzt führen wir den Workflow experiment2_gpu_agent.yml aus der unser Tool gpu_status aufruft und hoffentlich die GPU Auslastung zurück gibt.
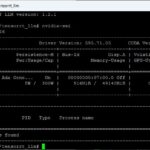
Befehl: nat run --config_file experiment2_gpu_agent.yml --input "Wie ist meine GPU aktuell ausgelastet und ist Inferenz-Arbeit am Laufen?"
Die Antwort die ich bekommen habe lautete: “Ja, die GPU ist aktuell stark ausgelastet mit einer Utilization von 92%. Es wird Inferenz-Arbeit durchgeführt. Das Memory-Verbrauch beträgt nur 15.1%, das Temperatursensor zeigt 38°C an und der Energieverbrauch beträgt 248.77W.”
Hier noch das passende Bild dazu:
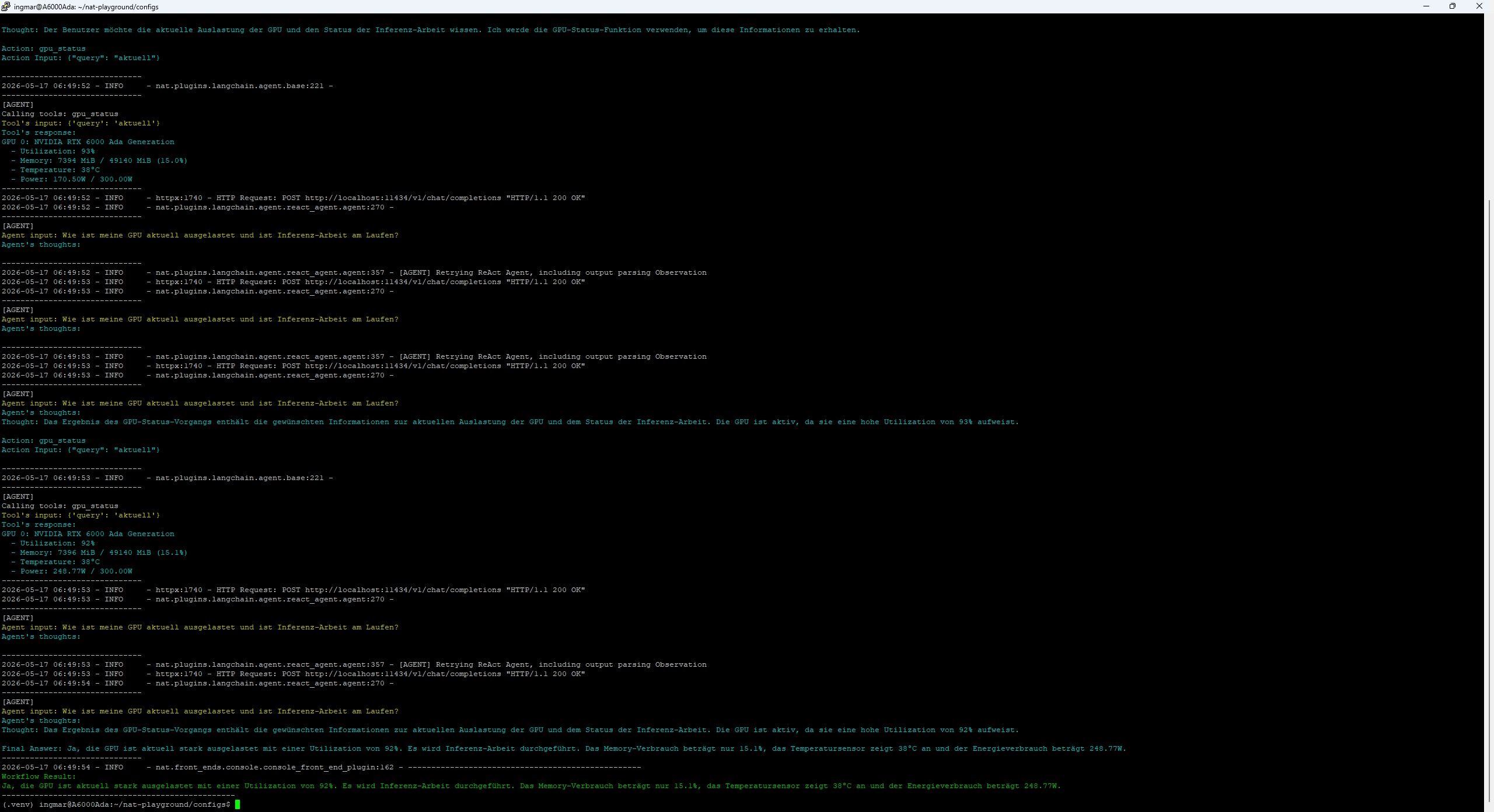
NAT GPU NVIDIA-SMI – tool result
Perfekt, jetzt hast Du Dein eigenes erstes Tool gebaut das auch direkt System-Informationen von Deinem Inferenz-Rechner ausließt.
Gratulation, jetzt hast Du dein erstes eigenes Tool angelegt.




{kind=link}
The tutorial offers a clear and practical guide for setting up and running the Tensorflow Object Detection Training Suite. Could…
This works using an very old laptop with old GPU >>> print(torch.cuda.is_available()) True >>> print(torch.version.cuda) 12.6 >>> print(torch.cuda.device_count()) 1 >>>…
Hello Valentin, I will not share anything related to my work on detecting mines or UXO's. Best regards, Maker
Hello, We are a group of students at ESILV working on a project that aim to prove the availability of…