

Echtzeit-Spracherkennung gehört zu den Bausteinen, die ich für souveräne Sprach-Agenten unbedingt selbst hosten möchte. Ich stelle mir das immer so vor das ich alles lokal laufen lasse ohne Cloud-API, ohne dass mein Audioaufnahme mein Netzwerk verlässt. Mit dem im März 2026 aktualisierten Modell NVIDIA Nemotron ASR Streaming (0.6B) gibt es dafür inzwischen eine sehr attraktive Option: ein kompaktes 600-Millionen-Parameter-Modell, das englische Sprache mit Punktuation und Großschreibung transkribiert und dabei sowohl für Low-Latency-Streaming als auch für Batch-Verarbeitung ausgelegt ist.
In diesem Beitrag zeige ich dir Schritt für Schritt, wie ich das Modell auf meinem lokalen Inferenz-Server (Dual RTX A6000, Ubuntu) ans Laufen gebracht habe. Praktischerweise listet NVIDIA die A6000 sogar offiziell als getestete Hardware. Das ASR Modell ist damit also wie gemacht für mein Homelab-Setup bzw. eure Workstation wenn diese über ähnliche Hardware verfügt.
Was ist Nemotron ASR Streaming?
Nemotron-ASR-Streaming basiert auf der Cache-Aware FastConformer-RNNT-Architektur mit 24 Encoder-Layern und einem RNN-Transducer-Decoder. Der entscheidende Unterschied zu klassischem „buffered“ Streaming: Statt überlappende Audiofenster immer wieder neu zu berechnen, hält das Modell Caches für alle Self-Attention- und Convolution-Layer vor. Jeder neue Audio-Chunk wird damit genau einmal verarbeitet. Dieses Vorgehen spart Rechenzeit und drückt die Latenz, ohne die Genauigkeit zu opfern.
Für mich ist vor allem die Laufzeit-Flexibilität spannend: Die Chunk-Größe lässt sich zur Inferenzzeit wählen, ganz ohne erneutes Training. Du bewegst dich also frei auf der Pareto-Kurve zwischen Latenz und Genauigkeit. So ist es wohl möglich von 80 ms für besonders reaktive Voice-Agents bis 1120 ms für maximale Transkriptionsqualität das Modell bzw. sein eigenes Setup auszureizen.
Eckdaten auf einen Blick
- Architektur: FastConformer-CacheAware-RNNT (24 Encoder-Layer, RNNT-Decoder)
- Parameter: 600M
- Sprache: Englisch (en-US), trainiert auf rund 530k Stunden Audio
- Chunk-Größen: 80 ms, 160 ms, 560 ms, 1120 ms
- Features: Punktuation & Großschreibung nativ, optional ITN und Übersetzung über die Pipeline
- Lizenz: NVIDIA Open Model License (kommerziell und nicht-kommerziell nutzbar)
Voraussetzungen
Bevor wir loslegen, ein kurzer Blick auf die Anforderungen. Viel Hardware brauchst du nicht denn das Modell ist klein:
- Betriebssystem: Linux (ich nutze Ubuntu Server)
- GPU: NVIDIA-GPU der Architektur Volta, Ampere, Hopper oder Blackwell. Getestet u. a. auf V100, A100, A6000 und DGX Spark. Bei 600M Parametern reichen wenige GB VRAM locker aus.
- Treiber & CUDA: aktueller NVIDIA-Treiber, passend zur installierten PyTorch-CUDA-Version
- Python: 3.10 oder 3.11 (ich empfehle eine saubere venv-Umgebung)
- Runtime: NeMo 25.11 oder neuer
Schritt 1: Systempakete installieren
NeMo benötigt für die Audio-Verarbeitung libsndfile und ffmpeg. Diese installieren wir zuerst auf Systemebene. Außerdem brauchen wir das venv-Modul für unsere virtuelle Python-Umgebung. Sehr warscheinlich ist es bereits vorhanden aber auf vielen Distributionen liegt das im Paket python3-venv:
Befehl: sudo apt-get update && sudo apt-get install -y libsndfile1 ffmpeg python3-venv python3-pip
Schritt 2: Python-venv anlegen
Damit die NeMo-Abhängigkeiten nicht mit anderen Projekten oder dem System-Python kollidieren, arbeite ich grundsätzlich in einer isolierten virtuellen Umgebung (venv). Das hält das Setup sauber und lässt sich jederzeit rückstandsfrei wieder löschen – einfach den Ordner entfernen.
Lege zunächst die venv mit Python 3.11 an (passe den Pfad nach Belieben an) und aktiviere sie anschließend:
Als nächstes legen wir eine virtuelle Umgebung mit dem Namen nemotron-asr im ~/venv/ Ordner im Home-Verzeichnis mit Python 3.11 an.
Befehl: python3.11 -m venv ~/venvs/nemotron-asr
Jetzt muss die eingerichtete Umgebung noch mit dem folgenden Befehl aktiviert werden.
Befehl: source ~/venvs/nemotron-asr/bin/activate
Sobald die venv aktiv ist, siehst du den Namen in deinem Prompt, z. B. (nemotron-asr). Als Erstes bringen wir pip und die Build-Tools auf den aktuellen Stand – das erspart später so manchen Build-Fehler:
Befehl: pip install --upgrade pip setuptools wheel
Tipp: Für jede neue Terminal-Sitzung musst du die Umgebung erneut mit source ~/venvs/nemotron-asr/bin/activate aktivieren. Verlassen kannst du sie jederzeit mit deactivate.
Schritt 3: PyTorch und NeMo installieren
NVIDIA empfiehlt ausdrücklich diese Reihenfolge: zuerst Cython und ein aktuelles PyTorch, danach das NeMo-Toolkit. Installiere PyTorch mit der CUDA-Version, die zu deinem Treiber passt (Beispiel hier: CUDA 130).
Alle folgenden Befehle laufen innerhalb der aktivierten venv:
Jetzt wird das Cython und packaging zuerst einmal installiert.
Befehl: pip install Cython packaging
Aktuelles PyTorch mit CUDA-Support in der virtuellen Umgebung isntallieren. Wichtig bitte auf die CUDA-Version aufpassen und diese gegebenenfalls anpassen!
Befehl: pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130
NeMo Toolkit mit ASR-Extras direkt vom main-Branch
Befehl: pip install "nemo_toolkit[asr] @ git+https://github.com/NVIDIA/NeMo.git@main"
Wichtiger Hinweis:
Das aktualisierte Checkpoint vom März 2026 setzt den main-Branch von NeMo voraus. Ein über pip installiertes Release-Paket ist hier oft noch nicht aktuell genug. Deshalb bevorzuge ich die Installation direkt von GitHub.
Schritt 4: Erster Test – Modell laden und transkribieren
Jetzt der spannende Moment. Mit wenigen Zeilen Python lädt sich das Modell direkt von Hugging Face und transkribiert eine Audiodatei im Offline-Modus (ganze Datei auf einmal). Das ist der schnellste Weg, um zu prüfen, ob alles korrekt installiert ist.
Dazu hier das kleine Python-Programm herunter laden und entpacken. Ich habe es in einem order ~/asr/ bei mir lokal gespeichert.
Download: https://github.com/custom-build-robots/nemotron-asr-local-streaming-demo
Damit HF keinen Fehler bringt hier das HF Token einmalig in der Shell setzen.
Befehl: export HF_TOKEN="hf_xxxxxxxxxxxxxxxxxxxxx"
Jetzt das zuvor erstellte Script ausführen und im Befehl auch gleich die Audio-Datei mit angeben.
Befehl: python transcribe.py audio.wav
Wenn hier eine korrekt transkribierte Textausgabe mit Satzzeichen erscheint, läuft dein Setup. Damit ist die eigentliche Hürde die Installation bereits genommen.
Ich hatte den kleinen Fehler gemacht und eine Stereo-WAV datei verwendet und folgenden Fehler bekommen.
Input shape expected = (batch, time)
Input shape found : torch.Size([1, 2, 631520])
Mehr dazu hier im jetzt folgenden Schritt 5 denn meine Stereo-Datei die diesen Fehler verusacht hat kann ich nicht verarbeiten.
Schritt 5: Audio richtig vorbereiten
Das Modell erwartet Mono-Audio im WAV-Format. Stereo-Aufnahmen oder andere Sampleraten konvertierst du am einfachsten mit ffmpeg. Bewährt haben sich 16 kHz, Mono, 16-Bit PCM:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le audio.wavEine feste maximale Länge gibt es nicht – die Obergrenze hängt allein vom verfügbaren GPU-Speicher ab. Auf meinen A6000 mit 48 GB ist das in der Praxis kein Thema.
Schritt 6: Streaming-Inferenz mit dem Cache-Aware-Skript
Für echtes Streaming, also die kontinuierliche Verarbeitung in Chunks, bringt NeMo ein fertiges Beispielskript mit. Wichtig vorweg: Dieses Skript braucht weder einen Bildschirm noch ein Mikrofon und kann via SSH verwendet werden. Es liest Audiodateien von der Platte und schreibt die Transkripte in eine Datei. Also genau richtig für meinen headless A6000-Ada-Server, auf dem ich alles per SSH einrichte. Das Skript simuliert dabei Streaming auf bereits vorhandenen Dateien es füttert sie chunk-weise ein, um das Streaming-Verhalten zu testen und ist kein Live-Mikrofon-Capture.
Zuerst klonen wir das NeMo-Repository:
Befehl: cd ~
Befehl: git clone https://github.com/NVIDIA/NeMo.git
Befehl: cd NeMo
Anschließend startest du die Cache-Aware-Streaming-Inferenz. Der zentrale Parameter ist att_context_size, über den du die Latenz steuerst:
python examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py \
model_path=<model_path> \
dataset_manifest=<dataset_manifest> \
batch_size=<batch_size> \
att_context_size="[70,13]" \
output_path=<output_folder>Dieser Befehl sieht auf den ersten Blick kryptischer aus als er ist. Die <...> sind reine Platzhalter, die du durch echte Werte ersetzen musst:
- model_path – Pfad zur lokalen
.nemo-Modelldatei (genau die Datei, die beimfrom_pretrainedin Schritt 4 heruntergeladen wurde). - dataset_manifest – eine JSONL-Datei, die auflistet, welche Audiodateien transkribiert werden sollen (NeMo-Manifest-Format).
- batch_size – einfach eine Zahl, z. B.
16. Auf der A6000 Ada (48 GB) kannst du ruhig höher gehen. - att_context_size – dein Latenz-Regler (mehr dazu in Schritt 7), hier
[70,13]= 1,12 s Chunk-Größe. - output_path – ein Ordner, in den die Ergebnisse geschrieben werden.
Damit das Ganze konkret wird, gehe ich es Schritt für Schritt durch.
1. Die .nemo-Datei lokal ablegen. Falls du den Pfad nicht im HF-Cache suchen willst, lädst du die Modelldatei einfach gezielt herunter:
hf download nvidia/nemotron-speech-streaming-en-0.6b \
nemotron-speech-streaming-en-0.6b.nemo \
--local-dir ~/asr/modelsBei mir lag die Datei aber recht einfach in meinem Home-Verzeichnis im Order ~.cache/huggingface/... zu finden wie nachfolgend als Pfad gezeigt:
Pfad: ~/.cache/huggingface/hub/models--nvidia--nemotron-speech-streaming-en-0.6b/snapshots/<commit-hash>/
2. Ein Manifest bauen.
Das Manifest ist eine einfache Textdatei, in der pro Zeile ein JSON-Objekt mit dem Audiopfad steht:
Befehl: nano ~/asr/manifest.jsonl
In die Datei wird dann folgendes eingefügt hier am Beispiel meines Homeverzeichnisses.
{"audio_filepath": "/home/ingmar/asr/audio.wav", "duration": 25.0, "text": ""}
Mit Strg + x gefolgt von einem y die Datei speichern.
Der Wert bei duration darf grob sein, text bleibt für die reine Inferenz leer. Für mehrere Dateien hängst du einfach weitere Zeilen an.
3. Der fertige Befehl mit echten Werten.
Jetzt setzt du die Platzhalter durch deine tatsächlichen Pfade. Bei mir sah das dann wie folgt aus.
Befehl: python ~/NeMo/examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py \
model_path=/home/ingmar/.cache/huggingface/hub/models--nvidia--nemotron-speech-streaming-en-0.6b/snapshots/7a9b763e6c5fb103da690219c049fac917aa50b1/nemotron-speech-streaming-en-0.6b.nemo\
dataset_manifest=/home/ingmar/asr/manifest.jsonl \
batch_size=16 att_context_size="[70,13]"\
output_path=/home/ingmar/asr/results \
Schreib den Befehl am besten in einer Zeile ohne Backslashes dann kann beim Einfügen nichts schiefgehen:
Befehl: python ~/NeMo/examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py model_path=/home/ingmar/.cache/huggingface/hub/models--nvidia--nemotron-speech-streaming-en-0.6b/snapshots/7a9b763e6c5fb103da690219c049fac917aa50b1/nemotron-speech-streaming-en-0.6b.nemo dataset_manifest=/home/ingmar/asr/manifest.jsonl batch_size=16 att_context_size="[70,13]" output_path=/home/ingmar/asr/results
Die fertigen Transkripte findest du anschließend im Ordner ~/asr/results.
Hinweis zur NeMo-Version: Welche Hydra-Schlüssel das Skript exakt erwartet (model_path= gegenüber eventuell pretrained_name=) und ob duration im Manifest Pflicht ist, hängt vom aktuellen Stand des main-Branch ab. Bevor du rätst, lohnt sich ein kurzer Blick in die eingebaute Hilfe des Skripts:
Befehl: python examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py --help
Der zweite Wert in att_context_size ist der Right Context und darf einen der Werte {0, 1, 6, 13} annehmen. Das ist genau dein Latenz-Regler.
Schritt 7: Chunk-Größen verstehen und der Latenz-Regler
Die Latenz wird über att_context_size = {left_context, right_context} definiert, gemessen in 80-ms-Frames. Die Chunk-Größe ergibt sich aus dem aktuellen Frame plus dem Right Context:
| att_context_size | Chunk-Größe | Latenz | Einsatzempfehlung |
|---|---|---|---|
| [70, 0] | 1 Frame | 0,08 s | Maximale Reaktivität (Voice-Agent) |
| [70, 1] | 2 Frames | 0,16 s | Sehr reaktive Live-Anwendungen |
| [70, 6] | 7 Frames | 0,56 s | Guter Kompromiss |
| [70, 13] | 14 Frames | 1,12 s | Beste Genauigkeit / Live-Captioning |
Jeder Chunk wird dabei strikt nicht-überlappend verarbeitet das ist der Effizienzgewinn der Cache-Aware-Architektur gegenüber dem klassischen Buffering.
Schritt 8: End-to-End-Pipeline mit Punktuation, ITN und Übersetzung
Wer mehr als nur reine Transkription möchte, nutzt die Pipeline-Methode. Sie baut auf der Konfigurationsdatei cache_aware_rnnt.yaml auf und liefert komplette Workflows inklusive Punktuation & Großschreibung (PnC), Inverse Text Normalization (ITN) und optionaler Übersetzung.
Die Konfigurationsdatei findest du im NeMo-Repository unter examples/asr/conf/asr_streaming_inference/cache_aware_rnnt.yaml. Danach genügt folgender Code:
from nemo.collections.asr.inference.factory.pipeline_builder import PipelineBuilder
from omegaconf import OmegaConf
# Pfad zur cache_aware_rnnt.yaml
cfg_path = 'cache_aware_rnnt.yaml'
cfg = OmegaConf.load(cfg_path)
# Pfade aller zu transkribierenden Audiodateien
audios = ['/path/to/your/audio.wav']
# Pipeline erstellen und Inferenz ausführen
pipeline = PipelineBuilder.build_pipeline(cfg)
output = pipeline.run(audios)
# Ausgabe
for entry in output:
print(entry['text'])Performance: Was kannst du erwarten?
NVIDIA misst die Genauigkeit über die Word Error Rate (WER) auf den Datensätzen der HuggingFace OpenASR-Leaderboard. Schön sichtbar wird hier der Latenz-Genauigkeits-Trade-off: Je größer der Chunk, desto niedriger die Fehlerrate.
| Chunk-Größe | Ø WER | LS test-clean | LS test-other | AMI |
|---|---|---|---|---|
| 1,12 s | 6,93 % | 2,32 % | 4,84 % | 11,73 % |
| 0,56 s | 7,07 % | 2,46 % | 5,07 % | 11,88 % |
| 0,16 s | 7,67 % | 2,56 % | 5,57 % | 14,71 % |
| 0,08 s | 8,43 % | 2,80 % | 6,01 % | 18,29 % |
Bemerkenswert: Selbst bei der aggressivsten Latenz von 80 ms liegt die durchschnittliche WER noch unter 9 % – und bei sauberem Audio (LibriSpeech test-clean) sogar unter 3 %. Für Live-Anwendungen ist das ein hervorragender Wert.
Tipps für den produktiven Betrieb
- Parallele Streams: Dank der effizienten Cache-Architektur passen bei gleichem VRAM deutlich mehr gleichzeitige Streams auf die GPU als bei buffered Ansätzen. Das gute dabei ist, das senkt die Kosten pro Transkription.
- Richtige Chunk-Größe wählen: Für einen interaktiven Voice-Agent würde ich mit [70, 1] oder [70, 6] starten; für Untertitelung oder Protokolle lieber [70, 13] nehmen.
- Audioformat prüfen: Mono ist Pflicht. Falsche Sampleraten sind die häufigste Fehlerquelle. Wenn ein Zweifel besteht unbedingt die Audiodatei vorher mit ffmpeg konvertieren.
- Hosted-Variante zum Testen: Wer erst ohne lokale GPU experimentieren will, kann das Modell über die NVIDIA-NIM-API auf build.nvidia.com per
nvidia-riva-clientansprechen. Für den souveränen Betrieb bleibt aber die lokale Installation mein Favorit.
Live Demo Web-App
Jetzt haben wir alles eingerichtet und im Grund fehtl jetzt noch eine kleine Web-Anwendung die zeigt zu was NVIDIA Nemotron ASR fähig ist. Das Python Programm muss in der virtuellen Umgebung wie gewohnt gestartet werden.
Befehl: source ~/venvs/nemotron-asr/bin/activate
Das Python Programm asr_gradio_app.py gibt es hier zum download.
Download: https://github.com/custom-build-robots/nemotron-asr-local-streaming-demo
Jetzt speichere das Python Programm in einem Ordner auf Deinem Rechner.
Option 1 – SSH Tunnel:
Anschließen musste ich einen SSH-Tunnel aufbauen auf meinen Server da sonst das Mikrophon nicht unterstützt wird da ich keine HTTPs Verschlüsselung habe. Dazu habe ich in der PowerShell meines Windows-Rechners folgenden Befehl ausgeführt der einen SSH-Tunnel zu meinem Server herstellt.
Befehl: ssh -L 3000:localhost:7860 ingmar@192.168.2.119
Jetzt konnte ich im Browser einfach die folgende URL eigneben und die Gradio-Web App öffnen. Auch war es dann möglich das Microphon zu verwenden für die Aufnahme.
URL: http://localhost:3000/
Option 2 – Gradio public share URL:
Ich habe in der letzten Zeile im Skript share=True eingestellt. So erzeugt die Gradio App einen https Link der von überall aus dem Internet heraus aufgerufen werden kann wenn man die URL kennt. Dann muss man nicht mit dem SSH Tunnel arbeiten und kann auch das Mikrophon direkt verwenden.
Web-App starten
Jetzt das Python Programm wie folgt starten.
Befehl: python asr_gradio_app.py
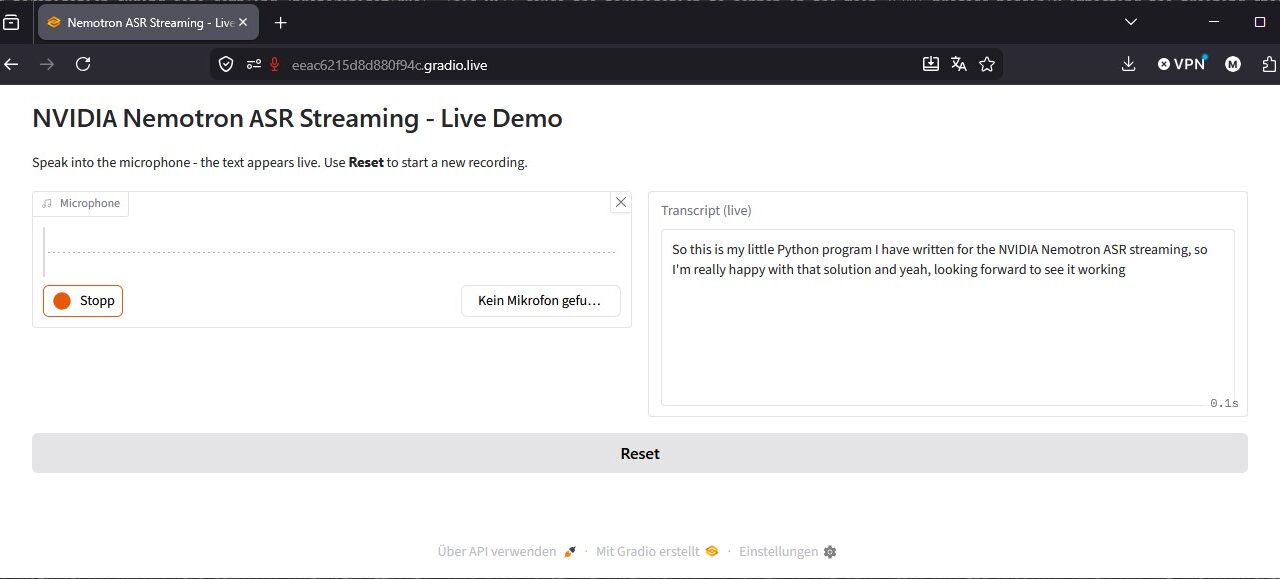
Bei mir sieht die Web-Oberfläche wie folgt aus.
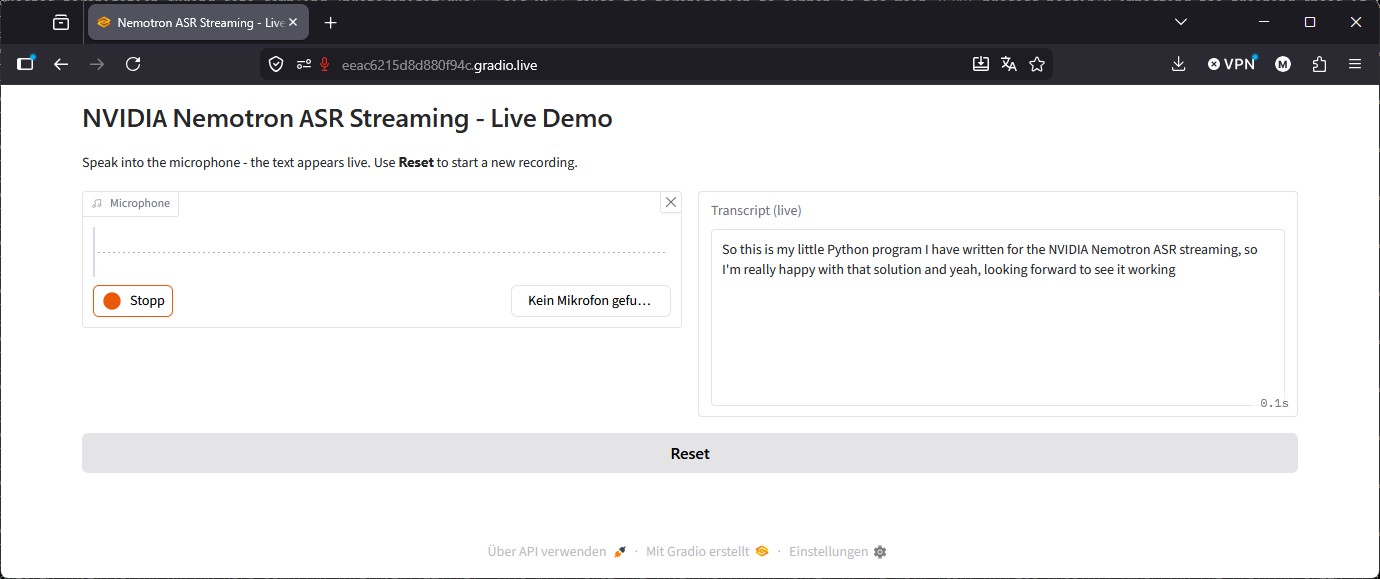
NVIDIA Nemotron ASR Streaming
Fazit
Mit Nemotron ASR Streaming bekommt man ein erstaunlich leistungsfähiges, kompaktes Spracherkennungsmodell, das sich in unter einer Stunde lokal aufsetzen lässt. Die Cache-Aware FastConformer-RNNT-Architektur liefert genau das, was ich für einen souveränen Voice-Agenten brauche: niedrige Latenz, gute Genauigkeit und die Freiheit, den Trade-off zur Laufzeit selbst zu bestimmen. Das alles auf der eigenen Hardware, ohne dass Sprachdaten in eine fremde Cloud wandern.
Für mich ist das ein weiterer Baustein im Aufbau eines vollständig selbst gehosteten KI-Stacks. Im nächsten Schritt möchte ich das Modell in Open WebUI als STT-Backend einbinden und mit einem lokalen TTS zu einem durchgängigen Sprach-Loop kombinieren. Aber das ist Stoff für einen eigenen Beitrag wenn ich dazu kommen sollte.
Wenn du das Setup nachbaust: Schreib mir gern in die Kommentare, mit welcher Chunk-Größe du für deinen Anwendungsfall die besten Ergebnisse erzielst.
Artikelübersicht – Souveräner lokaler Voice-Agent:
Teil 1: NVIDIA Nemotron ASR Streaming lokal mit NeMoTeil 2: NVIDIA NIM lokal – deutsche Spracherkennung (Parakeet)
Teil 3: NVIDIA Canary lokal – mehrsprachige Spracherkennung & Übersetzung
Teil 4: NVIDIA Magpie TTS lokal – deutsche Sprachausgabe
Teil 5: NeMo Agent Toolkit (NAT) – Orchestrator lokal aufsetzen
Teil 6: Lokaler Voice-Agent – ASR, LLM & TTS mit Pipecat zum Loop
Teil 7: Voice-Agent mit Tool-Calling – NAT als Gehirn
Teil 8: Souveräner Voice-Agent – lokales Wake-Word als Türsteher







{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…