


Nach dem ihr AUTOMATIC1111 auf eurem System um die Erweiterung Dreambooth ergänzt habt möchte ich euch kurz erklären wie ihr ein Training aufsetzt und startet. Da ich hier selber noch lerne und ausprobieren muss sollte diese Anleitung als eine erste Idee verstanden werden wie die Abläufe sind und auf was geachtet werden muss. Sicher werde ich diese Anleitung immer mal wieder ergänzen oder auch korrigieren wenn ich mehr Wissen und Erfahrung gesammelt habe. Aber für einen ersten Start und um ein Gefühl zu bekommen wie komplex das Ganze ist hoffe ich das die Beschreibung euch hilft ein erstes eigenes Netz zu trainieren das auch etwas zeigt also generieren kann über einen Prompt was ihr on top auf das bestehende Netz trainiert habt.
Wichtig ist hier auch wieder damit das Training bzw. dieses kleine Projekt Spaß macht auch eine gute NVIDIA GPU im Rechner zu haben. Ich empfehle hier immer die 30XX Serie oder eben Leitungsstärker. Ich selbe setzte eine NVIDIA A6000 in meinem Rechner ein und bin mit der Geschwindigkeit ganz zufrieden. Vermutlich wäre eine RTX 4090 bereits schon wieder schneller. Aber einen Vergleich habe ich nicht.
Hinweis: Dieser Artikel ist für mich aktuell eine Dokumentation wie ich das Modell feingetunt habe. Ich werde den Artikel bei neuen Erkenntnissen immer wieder aktualisieren.
Das erste Training aufsetzen
Ihr startet wie gewohnt AUTOMATIC1111 auf eurem Rechner, ruft die Web-Oberfläche auf und öffnet den Reiter Dreambooth auf der Web-Oberfläche von Stable-Diffusion. Jetzt legt ihr über den Reiter Create ein Model an. Dazu gebt ihr diesem einen sprechenden Namen so das ihr später noch wisst was sich hinter diesem Modell verbirgt also dessen Eigenschaft die ihr diesem beigebracht habt.
Ich starte das Training vom Source Checkpoint v1-5-pruned.ckpt da dieses Netz so der Beschreibung nach gut geeignet ist für Feintuning was ich ja mit meinen PFM-1 Minenbildern vorhabe. Die Beschreibung zu dem Netz und den Download Link für dieses findet ihr hier.
URL: https://huggingface.co/runwayml/stable-diffusion-v1-5
Wo das Netz abgelegt werden muss etc. findet ihr in meiner Beschreibung hier.
URL: Stable Diffusion – AUTOMATIC1111 Ubuntu Installation Teil 2/2
Das folgende Bild zeigt die Ansicht für das Anlagen bzw. erzeugen eures eigenen Netzes auf das wir jetzt on top trainieren also dieses feintunen werden. Wenn ihr alle Einstellungen also den Namen und die Auswahl des Netzes vorgenommen habt dann klickt auf „Create Model“. Das Anlegen des Netzes dauert ein paar Sekunden.
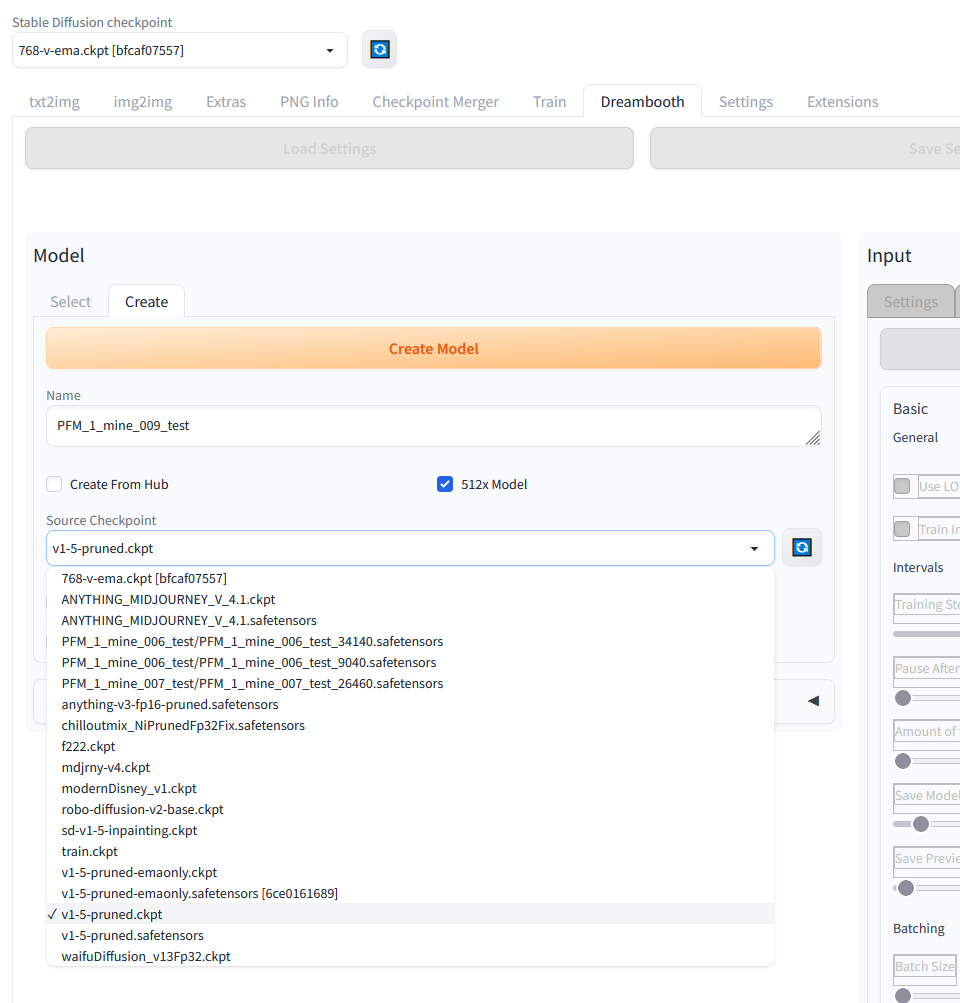
Automatic1111 Stable Diffusion Training – Create your model
Ich selber bin noch am Ausprobieren welche Einstellungen gute Ergebnisse liefern und habe hier mehr oder weniger noch experimentiert mit einem Ergebnis das ich persönlich ganz gut fand. Natürlich sind keine PFM-1 Antipersonen Minen generiert wurden die 1:1 dem Original gleichen aber die Mehrheit der genierten Bilder sah schon sehr nach dem Modell in seiner Geometrie aus.
Daher jetzt einmal als Screenshots die von mir gewählten Einstellungen.
Settings 1/3
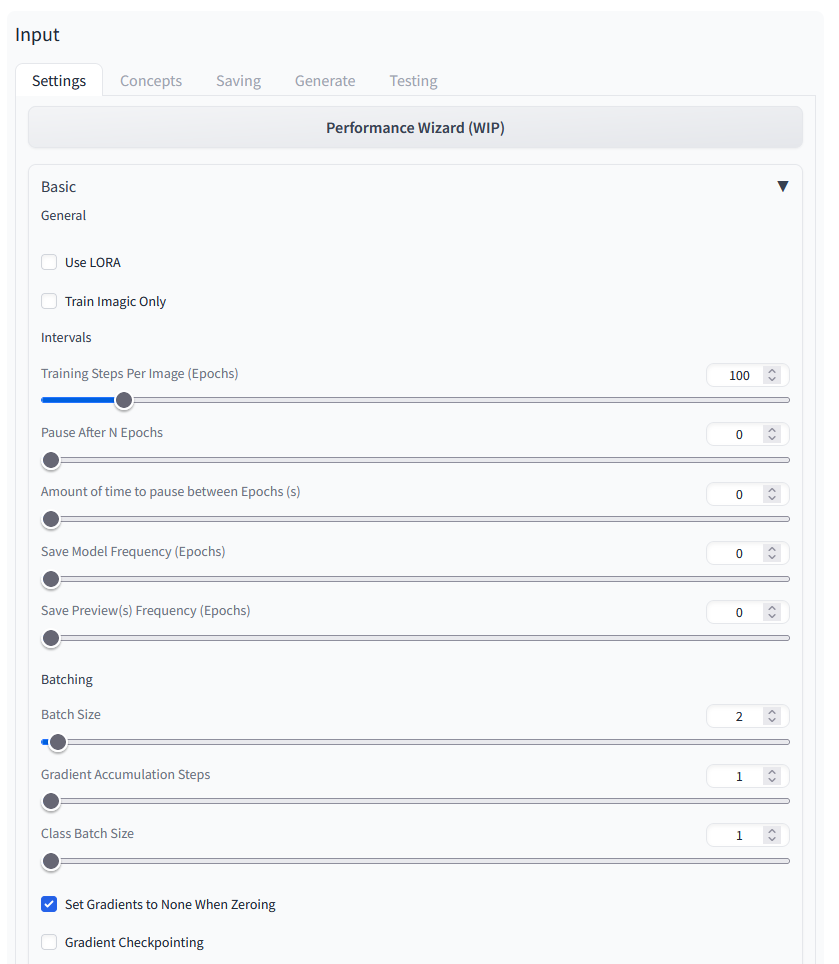
Stable Diffusion Training Dreambooth Settings 01
Settings 2/3
Hier habe ich lediglich die Learning Rate auf 0,000001 gesetzt sowie beim Optimizer 8bit AdamW gewählt. Bei der Mixt Precision bin ich auf bf16 gegangen.
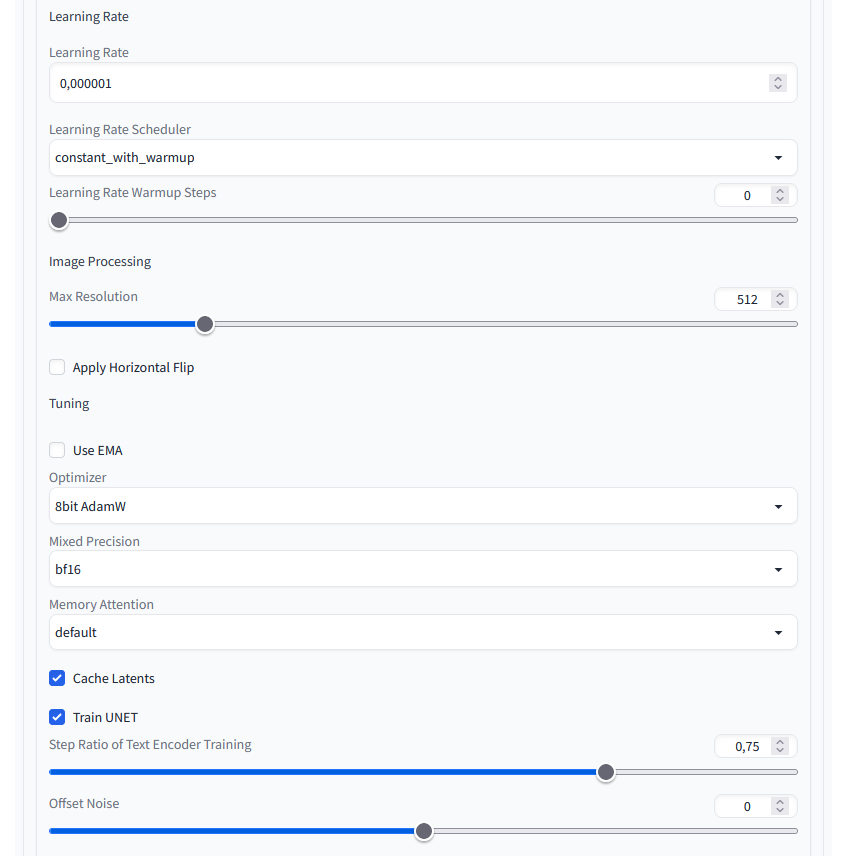
Stable Diffusion Training Dreambooth Settings 02
Settings 3/3
In diesem Abschnitt habe ich im oberen Bereich nichts verändert und die vorgeschlagenen Werte für das Finetuning von Objekten gelassen. Lediglich im Advanced Abschnitt habe ich einen Sanity Sample Prompt hinterlegt.
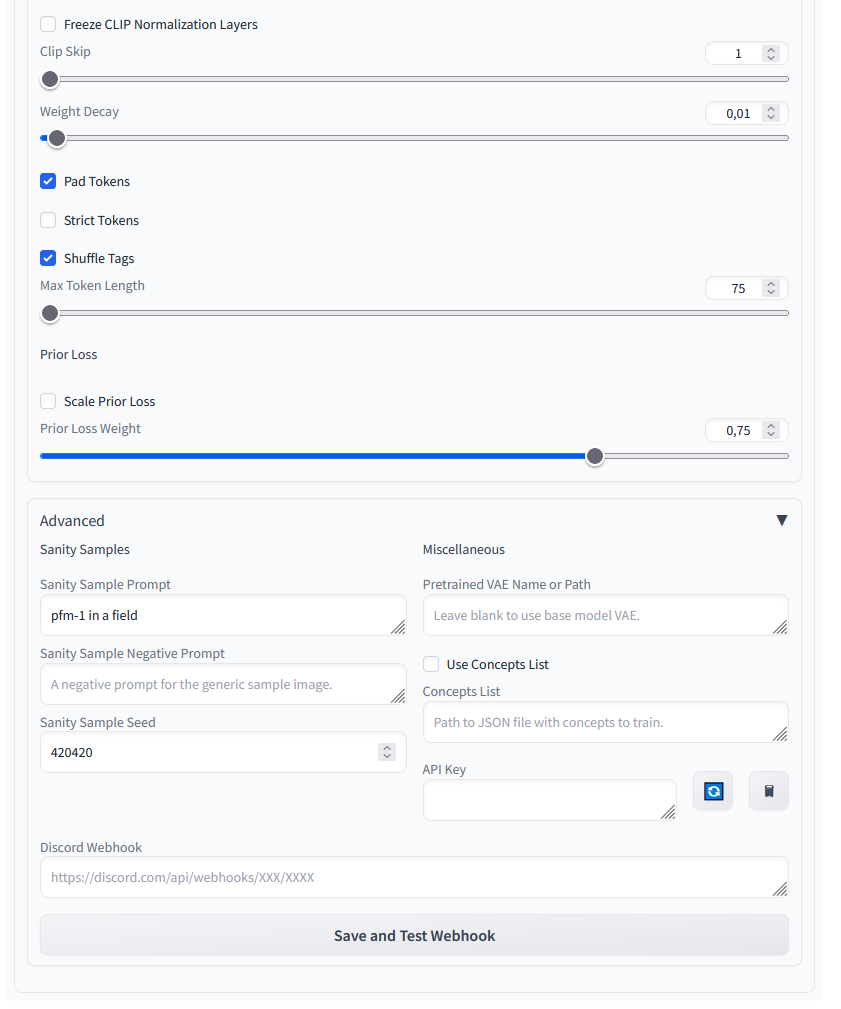
Stable Diffusion Training Dreambooth Settings 03
Concepts 1/2
Hier bei Concepts ist es wichtig die Pfade zu den Bildern anzugeben. Ich einmal ca. 280 Bilder der PFM-1 Mine in einem „train_data“ Ordner abgelegt. Weitere Bilder ca. 20 sind im Ordner „classification“ abgelegt damit das Netz prüfen kann ob das Ergebnis dem Wunsch entspricht was ich gerne als Ergebnis hätte.
Dazu sind dann noch weitere Prompts gekommen die für das Training wichtig sind und wenn möglich neu sein sollten also sehr selten. So ist die Chance größer das auch etwas generiert wird was meinen ca. 280 Bildern mit denen ich das Finetuning vornehme entspricht.
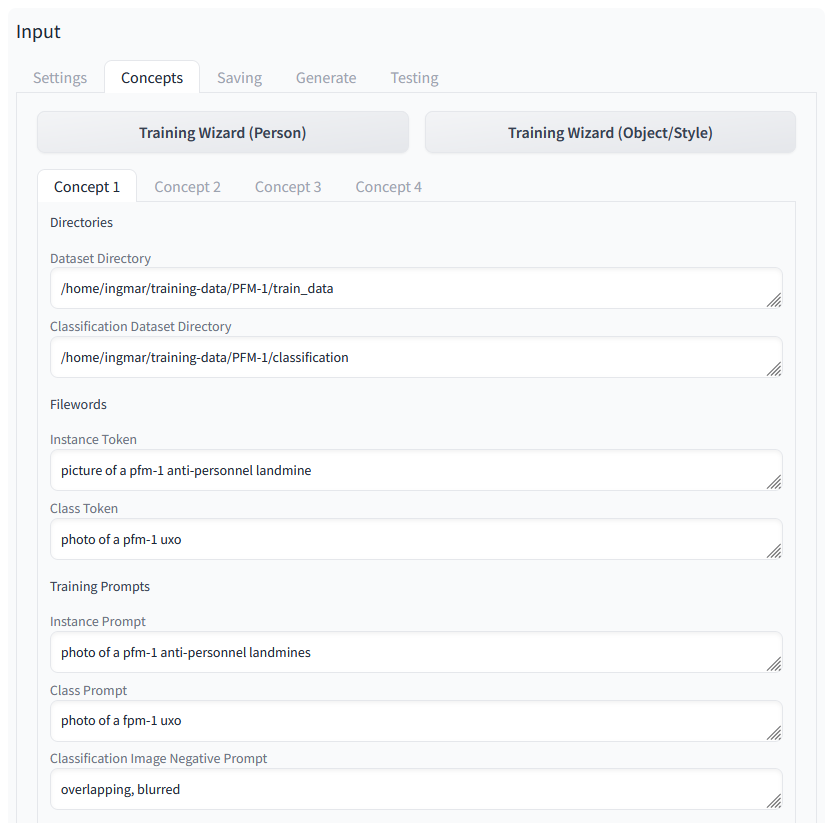
Stable Diffusion Training Dreambooth Concepts 01
Die Daten, die ich für die Feinabstimmung der PFM-1 Antipersonenminen verwendet habe, sehen wie im folgenden Bild dargestellt aus. Ein Teil wurde mit Blender gerendert und der andere Teil wurde über das Internet und soziale Medienplattformen gesammelt. Ich habe 251 Bilder gesammelt und erstellt.
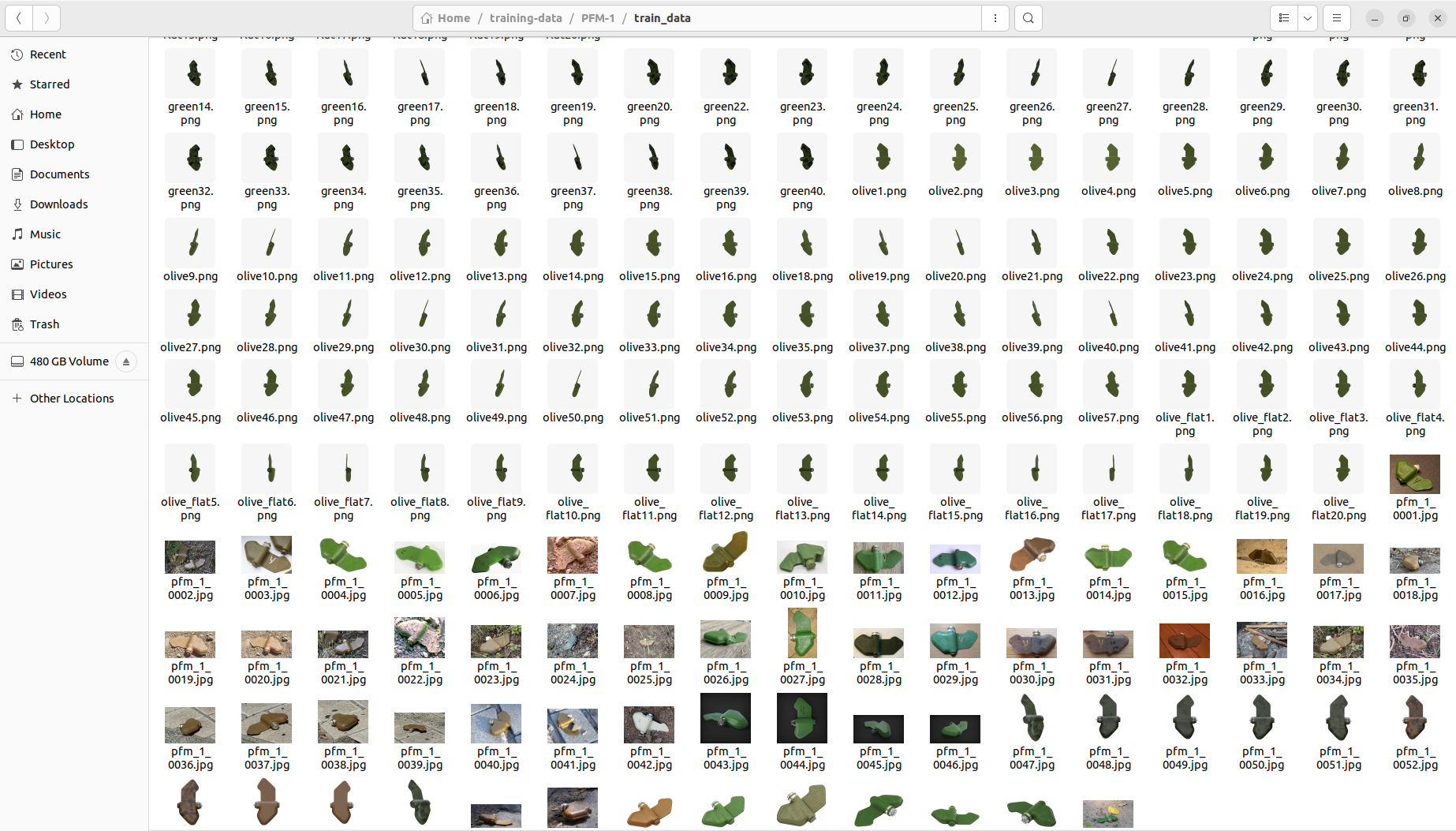
Stable Diffusion Training data PFM-1 antiperson mine
Concepts 2/2
Hier sind mehr oder weniger die Vorgeschlagenen Einstellungen beibehalten worden. Lediglich an der Stellschraube „Class Images Per Instance Image“ habe ich den einen oder anderen Wert ausprobiert und hier bin ich mit der Zahl 4 als Wert ganz gut gefahren. Ist der Wert z. B. sehr hoch wie 100 dann hätte mein Rechner ca. 35 Stunden lang nur Bilder erzeugt was wohl nicht zielführend gewesen wäre. Weiter unten habe ich von diesen Versuchen Bilder der verschiedenen Tests der Terminal Fenster eingefügt nebst kleiner Zeitberechnung.

Stable Diffusion Training Dreambooth Concepts 02
Savings 1/1
Hier habe ich wieder nichts verändert und die vorgeschlagenen Einstellungen übernommen.
Stable Diffusion Training Dreambooth Savings 01
Generate 1/2
Hier habe ich wieder nichts verändert und die vorgeschlagenen Einstellungen übernommen.

Stable Diffusion Training Dreambooth Generate 01
Generate 2/2
Hier habe ich wieder nichts verändert und die vorgeschlagenen Einstellungen übernommen.
Stable Diffusion Training Dreambooth Generate 02
Testing 1/1
Hier habe ich wieder nichts verändert und die vorgeschlagenen Einstellungen übernommen.
Stable Diffusion Training Dreambooth Testing 01
Die jetzt folgenden Bilder zeigen das Training auf meinem Computer. Einmal ist das Stable-Diffusion Terminal Fenster zu sehen in dem das Training läuft. Darunter ist die Ausgabe von nvidia-smi gezeigt mit der Auslastung meiner NVIDIA RTX A6000 Karte. Diese hat hier wirklich gut zu arbeiten und das Netz das gerade hier berechnet wird passt mit seinen ca. 11 GB gut in den Speicher der Grafikkarte.
Active Training
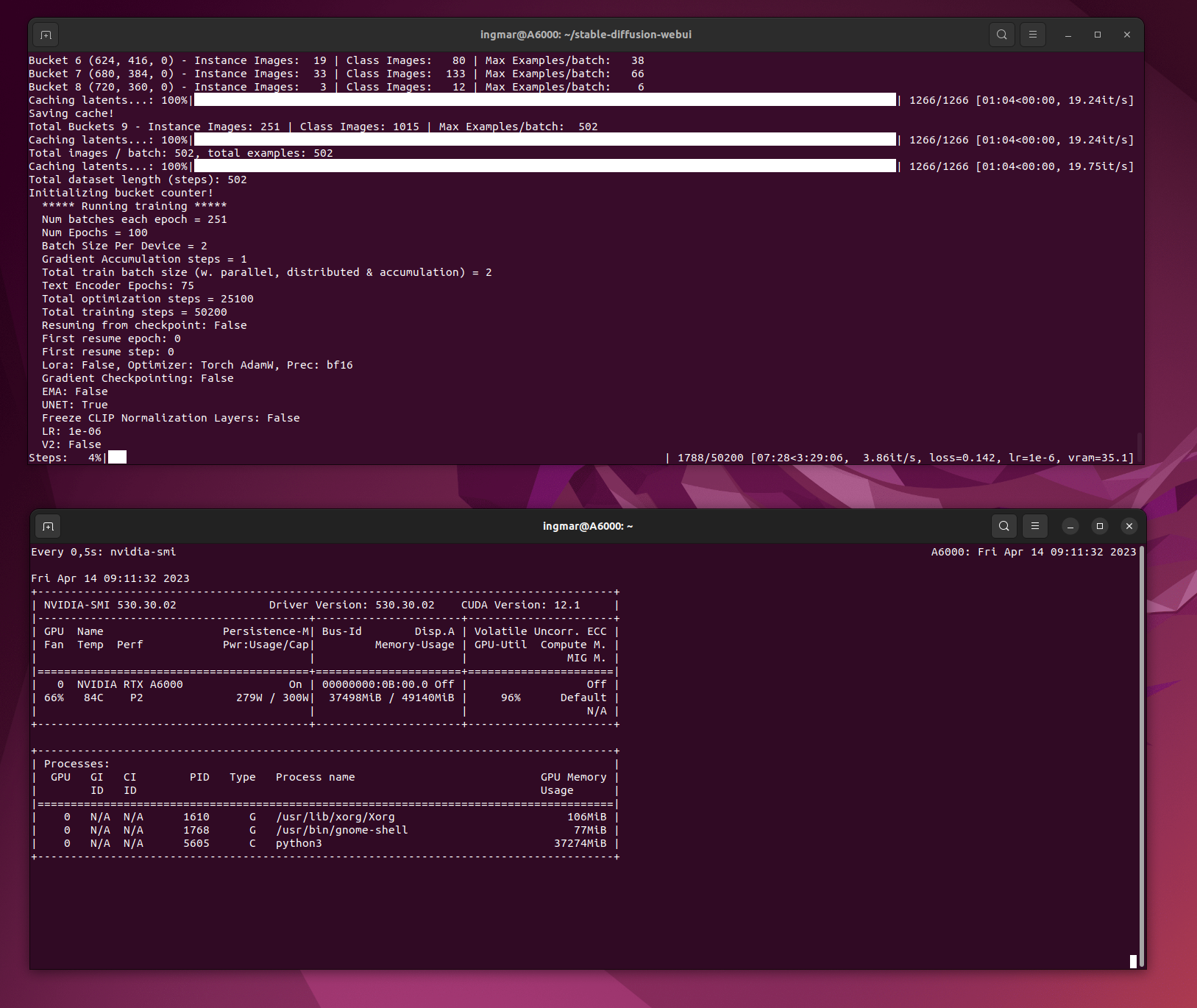
Stable Diffusion Training Dreambooth training active running
Generierung von 284 Class Images
Hier ist einmal das erzeugen der Bilder zu sehen also der Class Images. Ich habe hier einmal eine kleine Rechnung angefügt wie lange dies dauert. Weiter oben bin ich auf die Konfiguration bereits eingegangen und hatte die Bilder der Terminal Fenster bereits erwähnt.
Zeit für das Erzeugen der Class Images:
284 x 5 sec = 1420 sec
1420 sec / 60 = 24 min
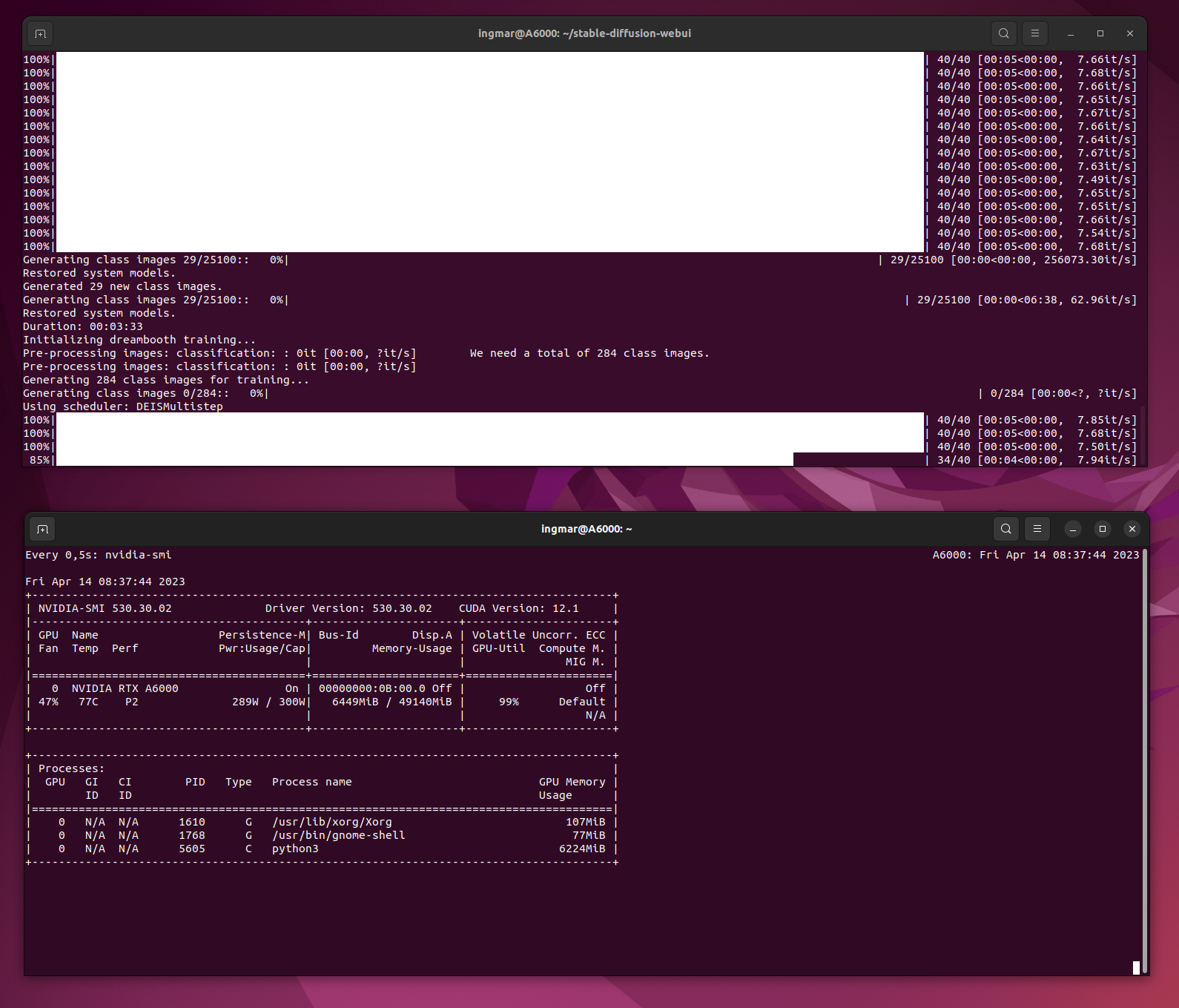
Stable Diffusion Training Dreambooth training generating class images
Generierung von viel zu vielen Class Images 25.100
Zeit für das Erzeugen der Class Images:
25.100 x 5 sec = 125.500 sec
125.500 sec / 60 = 2.091 min
2.091 min / 60 = 35 hours
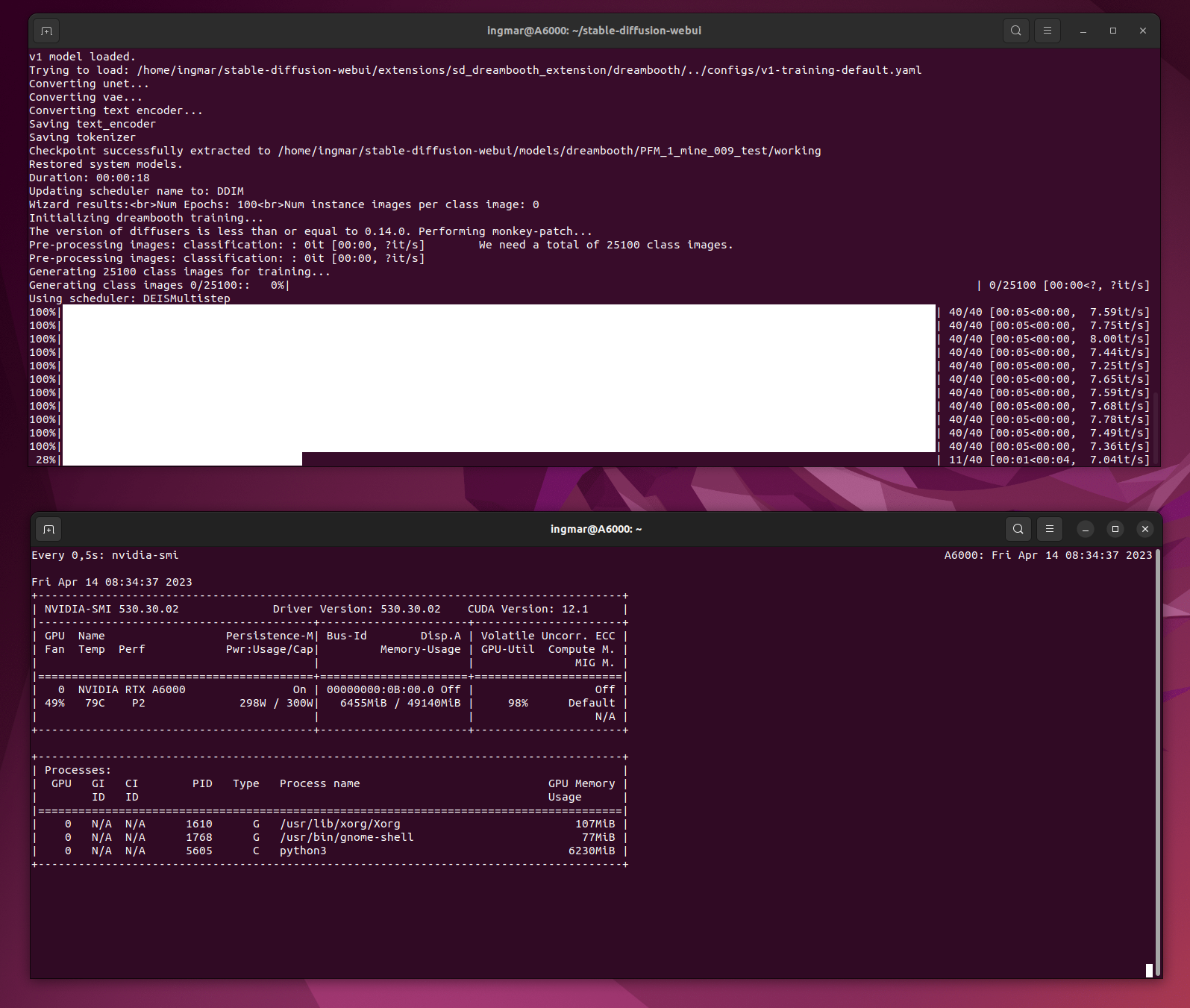
Stable Diffusion Training Dreambooth training generating too much class images
Damit ist einmal mehr oder weniger gezeigt wie ich das Netz trainiert habe. Als Ergebnis ist jetzt folgendes Bild der PFM-1 Antipersonenmine entstanden.

PFM-1 Stable Diffusion generated mine 20230414
Zusammenfassung
Für mich ist das Ergebnis soweit einmal okay. Ich werde noch ein paar mehr Bilder von dieser Mine mit Blender erzeugen und für das Training heran nehmen. Eventuell werde ich die gerenderten Bilder aus Blender auf die Vorderseite und Rückseite beschränken und nicht so viele Bilder mehr von der Seite verwenden. Denn meistens wird die Mine flach auf dem Boden liegen und nicht hochkant stehen. Die Ergebnisse die ich mit solch einem Trainingsdatensatz dann erzielen konnte werde ich hier noch ergänzen sobald ich dazu gekommen bin.
Artikelübersicht - Stable Diffusion:
Stable Diffusion - AUTOMATIC1111 Ubuntu Installation Teil 1/2Stable Diffusion - AUTOMATIC1111 Ubuntu Installation Teil 2/2
Stable Diffusion - Bilder lokal generieren mit Prompt Beispielen
Stable Diffusion - AUTOMATIC1111 Experten Konfiguration
Stable Diffusion - Dreambooth Training Finetuning einrichten Teil 1/2
Stable Diffusion - Dreambooth Training Finetuning ausführen Teil 2/2








{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…