

Die Spracherkennung steht: Mit Parakeet (Teil 2) und Canary (Teil 3) habe ich die Eingangsrichtung also Sprache zu Text NVIDIA-nativ abgedeckt. Jetzt kommt die Gegenrichtung, die Sprachausgabe. In diesem Beitrag betreibe ich NVIDIA Magpie TTS als lokales NIM und lasse mir deutschen Text natürlich vorlesen. Das ist das NVIDIA-native Gegenstück zu meinem früheren Beitrag über deutsche TTS mit Piper und XTTS aber diesmal komplett im NVIDIA-Ökosystem und wie immer lokal, auf eigener Hardware.
Was ist Magpie TTS?
Magpie TTS ist ein end-to-end mehrsprachiges, neuronales Text-to-Speech-Modell. Es erzeugt Sprache, indem es über eine Transformer-Encoder-Decoder-Architektur diskrete Audio-Codec-Tokens vorhersagt; ein nachgelagertes Audio-Codec-Modell wandelt diese Tokens dann in die hörbare Wellenform bzw. Frequenzen um.
Für uns sind drei Eigenschaften wichtig:
- Mehrsprachig inkl. Deutsch: Magpie Multilingual deckt neun Sprachen ab und darunter auch Deutsch
de-DE. - Streaming und Offline: Es kann das fertige Audio am Stück liefern oder die ersten Fragmente streamen, sobald sie bereit sind. Letzteres ist mir sehr wichtig fürs spätere Voice-Agent-Gefühl.
- Mehrere Stimmen: pro Sprache mindestens eine männliche und eine weibliche Stimme, teils mit emotionalen Stilen.
Kurz: das TTS-Gegenstück zu den ASR-NIMs aus Teil 2 und 3.
Das Zielbild dieses Beitrags
Wir betreiben das Magpie-TTS-NIM lokal: deutscher Text rein, natürliche deutsche Sprachausgabe als WAV raus. Optional auch im Streaming-Modus, der die ersten Audio-Fragmente liefert, sobald sie fertig sind. Alles lokal also dein Text und das erzeugte Audio bleiben auf der Maschine.
Voraussetzungen
Wenn du Teil 2 und 3 durchlaufen hast, ist die Grundlage bereits vorhanden, und wir referenzieren sie nur kurz:
- NGC-Account und API-Key,
docker loginannvcr.io(siehe Teil 2) - die venv
riva-clientmit installiertemnvidia-riva-client– das geklontepython-clients-Repo bringt unterscripts/tts/auch die TTS-Skripte mit - GPU ≥ Compute Capability 8.0 – Magpie Multilingual belegt bei
batch_size=8rund 11 GB VRAM
Neu installieren musst du also nichts. Wichtig nur: Magpie nutzt dieselben Ports (9000/50051) wie die ASR-NIMs. Stoppe vor diesem Schritt einen eventuell noch laufenden Parakeet- oder Canary-Container (Strg + C), sonst gibt es einen Port-Konflikt.
Schritt 1: Das Magpie-TTS-NIM starten
Falls dein API-Key in der aktuellen Terminal-Sitzung nicht mehr gesetzt ist, setze ihn erneut:
Befehl: export NGC_API_KEY="nvapi-xxxxxxxxxxxxxxxxxxxxx"
Dann Container und Profil wählen. Beim TTS-NIM wird das Profil über name= gewählt (nicht über mode= wie bei der ASR):
Befehl: export CONTAINER_ID=magpie-tts-multilingual
Befehl: export NIM_TAGS_SELECTOR=name=magpie-tts-multilingual
Befehl: docker run -it --rm --name=$CONTAINER_ID --runtime=nvidia --gpus '"device=0"' --shm-size=8GB -e NGC_API_KEY -e NIM_HTTP_API_PORT=9000 -e NIM_GRPC_API_PORT=50051 -p 9000:9000 -p 50051:50051 -e NIM_TAGS_SELECTOR -v ~/.cache/nim:/opt/nim/.cache nvcr.io/nim/nvidia/$CONTAINER_ID:latest
Den Cache-Ordner ~/.cache/nim aus Teil 2/3 kannst du weiterverwenden. Der erste Start lädt wieder das Modell und baut die Inferenz-Engine; bereit ist der Dienst, sobald „Application is ready to receive API requests“ in den Logs erscheint.
Hinweis zur Batch-Größe:
Standard ist batch_size=8 (~11 GB VRAM). Brauchst du mehr Parallelität, hängst du die Batch-Größe an: export NIM_TAGS_SELECTOR="name=magpie-tts-multilingual,batch_size=32" . Diese Konfiguration belegt dann allerdings rund 31 GB. Auf der A6000 Ada (48 GB) ist beides machbar; mit nvidia-smi behältst du die Belegung im Blick.
Nach dem Start sah das Terminal-Fenster wieder nicht sehr spannend aus. Aber es sollte alles passen und ordentlich hochgefahren sein.
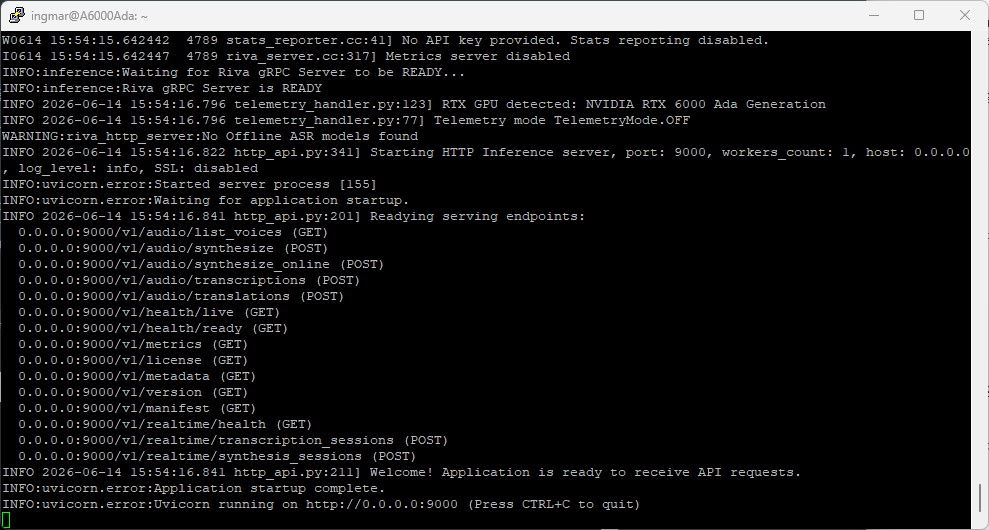
NVIDIA NIM Container Magpie setup
Schritt 2: Container-Status prüfen
In einem zweiten Terminal prüfst du wie gewohnt, ob der Dienst läuft.
Befehl: docker ps
Befehl: curl http://localhost:9000/v1/health/ready
Antwortet der Health-Check mit {"object":"health.response","message":"ready","status":"ready"}, steht dein TTS-Microservice.
Schritt 3: Verfügbare Stimmen auflisten
Bevor wir etwas vorlesen lassen, schauen wir, welche Stimmen das Modell anbietet. Aktiviere zuerst die venv:
Befehl: source ~/venvs/riva-client/bin/activate
Dann fragst du die Stimmen ab:
Befehl: python python-clients/scripts/tts/talk.py --server 0.0.0.0:50051 --list-voices
Du bekommst eine JSON-Liste der Sprachen und Stimmen zurück. Für Deutsch suchst du nach Einträgen, die mit Magpie-Multilingual.DE-DE. beginnen. Es gibt hier verschiedene Sprachen wie z.B. eine weibliche und eine männliche Stimme, teils mit emotionalen Stilen (z. B. .Neutral, .Calm). Den exakten Namen der deutschen Stimme, die du nehmen möchtest, tragen wir gleich in den Synthese-Befehl ein.
Hier ein Auszug der Stimmen für die deutsche Sprache:
„Magpie-Multilingual.IT-IT.Pascal.Happy“,
„Magpie-Multilingual.IT-IT.Pascal.Disgust“,
„Magpie-Multilingual.IT-IT.Pascal.Sad“,
„Magpie-Multilingual.DE-DE.Pascal“,
„Magpie-Multilingual.DE-DE.Pascal.Neutral“,
„Magpie-Multilingual.DE-DE.Pascal.Calm“,
„Magpie-Multilingual.DE-DE.Pascal.Angry“,
„Magpie-Multilingual.DE-DE.Pascal.Happy“,
„Magpie-Multilingual.DE-DE.Pascal.Disgust“,
„Magpie-Multilingual.DE-DE.Pascal.Sad“,
„Magpie-Multilingual.DE-DE.Mia“,
„Magpie-Multilingual.DE-DE.Mia.Neutral“,
„Magpie-Multilingual.DE-DE.Mia.Calm“,
„Magpie-Multilingual.DE-DE.Mia.Angry“,
„Magpie-Multilingual.DE-DE.Mia.Happy“,
„Magpie-Multilingual.DE-DE.Mia.Sad“,
„Magpie-Multilingual.DE-DE.Diego“,
„Magpie-Multilingual.DE-DE.Diego.Neutral“,
„Magpie-Multilingual.DE-DE.Diego.Calm“,
„Magpie-Multilingual.DE-DE.Diego.Angry“,
„Magpie-Multilingual.DE-DE.Diego.Happy“,
„Magpie-Multilingual.DE-DE.Diego.PleasantSurprised“,
„Magpie-Multilingual.DE-DE.Diego.Disgust“,
„Magpie-Multilingual.DE-DE.Sofia“,
„Magpie-Multilingual.DE-DE.Sofia.Neutral“,
„Magpie-Multilingual.DE-DE.Sofia.Calm“,
„Magpie-Multilingual.DE-DE.Sofia.Angry“,
„Magpie-Multilingual.DE-DE.Sofia.Happy“,
„Magpie-Multilingual.DE-DE.Sofia.Fearful“,
„Magpie-Multilingual.EN-US.Pascal“,
„Magpie-Multilingual.EN-US.Pascal.Neutral“,
„Magpie-Multilingual.EN-US.Pascal.Calm“,
„Magpie-Multilingual.EN-US.Pascal.Angry“,
Schritt 4: Erste deutsche Sprachausgabe
Jetzt lassen wir deutschen Text vorlesen und speichern das Ergebnis als WAV. Wichtig auf einem headless Server (wie meinem A6000-Ada per SSH): Es gibt keine Soundkarte zum direkten Abspielen und ich sitze ja auch nicht direkt an dem Rechner. Wir schreiben deshalb in eine Datei (--output) und hören sie danach an (z. B. nach dem Herunterladen per scp).
Hinweis: Bitte achtet darauf das ihr den –output Parameter entsprechend anpasst das die Datei auch an einem Pfad geschrieben wir den es bei euch gibt.
Befehl: python python-clients/scripts/tts/talk.py --server 0.0.0.0:50051 --language-code de-DE --voice Magpie-Multilingual.DE-DE.Sofia.Neutral --text "Hallo, das ist eine lokale Sprachausgabe mit NVIDIA Magpie." --output /home/ingmar/asr/de_Sofia.Neutral.wav
Den Stimm-Namen ersetzt du durch den passenden Wert aus Schritt 3.
Alternativ geht das auch direkt über die HTTP-Schnittstelle des NIM:
Befehl: curl -sS http://localhost:9000/v1/audio/synthesize --fail-with-body -F language=de-DE -F text="Hallo, das ist eine lokale Sprachausgabe mit NVIDIA Magpie." --output ausgabe.wav
Audio/Hörprobe:
Schritt 5: Streaming-TTS für niedrige Latenz
Vorab, weil „Streaming“ hier leicht verwirrt: Es wird keine URL im Browser geöffnet und nichts „live“ abgespielt. Es ist exakt derselbe Kommandozeilen-Befehl wie in Schritt 4 nur mit dem zusätzlichen Schalter --stream. Der Unterschied liegt allein darin, wie das NIM das Audio zurückgibt:
- Ohne
--stream(Offline): Du schickst den Text, das NIM synthetisiert die komplette Sprachausgabe und schickt sie erst dann in einem Stück zurück. Du wartest, bis alles fertig ist. - Mit
--stream: Das NIM liefert das Audio in kleinen Fragmenten, sobald sie fertig sind. Der Client bekommt schon die ersten Bruchteile einer Sekunde, während der Rest noch erzeugt wird. Das ist die niedrige „Time-to-first-Audio“, die einen Voice-Agenten natürlich wirken lässt.
Also geht es jetzt nur darum zu testen ob der Parameter --stream überhaupt geht.
Befehl: python python-clients/scripts/tts/talk.py --server 0.0.0.0:50051 --language-code de-DE --voice Magpie-Multilingual.DE-DE.Mia.Calm --text "Hallo, das ist eine lokale Sprachausgabe mit NVIDIA Magpie." --stream --output /home/ingmar/asr/ausgabe_stream.wav
Was bedeutet das auf einem headless Server konkret?
In beiden Fällen entsteht am Ende dieselbe Datei ausgabe*.wav, die du herunterlädst und anhörst. Den Streaming-Vorteil (sofort losreden, statt zu warten) hörst du erst, wenn das Audio live an einen Lautsprecher geht. Hier auf dem Server testen wir also vor allem, dass der Streaming-Modus sauber durchläuft und eine gültige WAV erzeugt. Den echten Nutzen spielt Streaming später in Teil 6 aus, wenn Pipecat die Audio-Fragmente direkt an die Wiedergabe durchreicht.
Zwei praktische Punkte:
- Anhören: Lade die WAV per
scpauf deinen Arbeitsrechner und spiele sie dort ab. - Lange Texte: Bei langen Eingaben ist
--streamohnehin die bessere Wahl, weil die Offline-Antwort sonst das gRPC-Limit von 4 MB pro Nachricht sprengen kann.
Schritt 6: Stimmen und Stile
Magpie Multilingual bringt pro Sprache mindestens eine männliche und eine weibliche Stimme mit, dazu emotionale Stile. Über den --voice-Namen wählst du gezielt aus, welche Stimme und welcher Stil gesprochen wird. Das haben wir ja bereits gesehen.
Hinweis zum Voice-Cloning: Echtes Zero-Shot-Voice-Cloning (eine Stimme aus einem kurzen Audioprompt nachbilden) ist nicht Teil dieses multilingualen NIM, sondern ein separates, zugriffsbeschränktes Modell (magpie-tts-zeroshot). Hier nutzen wir die vordefinierten Stimmen. Diese reichen zum Testen und ausprobieren für einen sauberen deutschen Voice-Agenten völlig aus. Ob man diese wirklich produktiv verwenden möchte bleibt jedem selbst überlassen.
Tipps und Troubleshooting
- Port-Konflikt: Magpie belegt 9000/50051 wie die ASR-NIMs. Vorher den jeweils anderen Container stoppen oder im
docker runandere Ports zuweisen. - Headless Server: Ohne Soundkarte kein direktes Abspielen aber schreibe die Audioausgabe mit
--outputin eine WAV und höre sie nach dem Herunterladen an (statt--play-audio). - Lange Texte / gRPC-4-MB-Limit: Bei langen Eingaben den Streaming-Modus (
--stream) nutzen, sonst kann die Offline-Antwort die gRPC-Nachrichtengröße sprengen. - Stimm-Name exakt übernehmen: Den
--voice-Wert genau aus--list-voiceskopieren; ein Tippfehler führt zu einer Fehlermeldung. - VRAM: ~11 GB bei
batch_size=8, ~31 GB beibatch_size=32. Mitnvidia-smiprüfen. - Sample-Rate/Encoding: Standard ist
LINEAR_PCM; über die Parameter lässt sich z. B. die Ausgabe-Samplerate (etwa 44100 Hz) steuern.
Fazit
Mit Magpie liegt jetzt auch die Sprachausgabe als NVIDIA-Microservice vor. Damit habe ich ASR (Parakeet, Canary) und TTS (Magpie) komplett NVIDIA-nativ und lokal beisammen. Das sind die beiden Hälften eines Sprach-Agenten: zuhören und antworten.
Im nächsten Teil kommt das Gehirn dazu: der Orchestrator über das NVIDIA NeMo Agent Toolkit (NAT), der erkennt, was der Nutzer will, und die passende Aktion auslöst. Danach verbinden wir in Teil 6 alle Bausteine mit Pipecat zu einem durchgängigen, unterbrechbaren Voice-Loop – dem vollständigen lokalen Sprach-Agenten.
Wenn du das Setup nachbaust: Schreib mir gern in die Kommentare, welche deutsche Magpie-Stimme dir am natürlichsten vorkommt.
Artikelübersicht – Souveräner lokaler Voice-Agent:
Teil 1: NVIDIA Nemotron ASR Streaming lokal mit NeMoTeil 2: NVIDIA NIM lokal – deutsche Spracherkennung (Parakeet)
Teil 3: NVIDIA Canary lokal – mehrsprachige Spracherkennung & Übersetzung
Teil 4: NVIDIA Magpie TTS lokal – deutsche Sprachausgabe
Teil 5: NeMo Agent Toolkit (NAT) – Orchestrator lokal aufsetzen
Teil 6: Lokaler Voice-Agent – ASR, LLM & TTS mit Pipecat zum Loop
Teil 7: Voice-Agent mit Tool-Calling – NAT als Gehirn
Teil 8: Souveräner Voice-Agent – lokales Wake-Word als Türsteher






{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…