


Schon länger juckt es mich in den Fingern: Firecrawl selbst gehostet, im eigenen LAN, ohne Cloud-Abhängigkeit, an meinen lokalen Ollama-Server angebunden. Web-Scraping ist eine der Schlüsselfähigkeiten, die ein KI-Agent braucht, wenn er ernsthaft recherchieren und auch Zugriff auf aktuelle Informationen aus dem Internet haben soll. Genau diese Fähigkeit wollte ich für meine NemoClaw-Experimente in Eigenregie betreiben, um nebenbei auch die OpenShell von NVIDIA besser zu verstehen. Heute zeige ich Euch, wie ich Firecrawl auf meiner zweiten A6000-Workstation aufgesetzt habe.
Das Hauptproblem an dieser Stelle vorneweg: Die populären Self-Hosting-Anleitungen, die man im Netz findet, sind nicht mehr aktuell. Die Firecrawl-Codebase hat sich in den letzten Monaten deutlich weiterentwickelt – mit neuen Containern, anderen Umgebungsvariablen und einer fiesen Race-Condition beim Start, in die jeder hineintappt, der einfach docker compose up -d aufruft. Genau diese Stolpersteine sammle ich hier und gebe Euch eine Anleitung, mit der Ihr direkt zum Ziel kommt.
local ai stack – firecrawl hermes agent
Was sich gegenüber älteren Anleitungen geändert hat
Drei Dinge, die mich beim ersten Versuch echt Zeit gekostet haben:
- Neue Container im Stack: Statt nur
api,worker,playwright-serviceundredisgibt es jetzt zusätzlichnuq-postgres(für Queue-Persistenz) undrabbitmq(als Message-Broker). Der separateworker-Container ist verschwunden – seine Aufgaben sind jetzt eingebettet imapi-Container. - Anderer Variablenname für die LLM-Anbindung: Frühere Anleitungen verwenden
OLLAMA_BASE_URL=http://host:11434/api. Die aktuelle Codebase ignoriert diese Variable komplett. Stattdessen mussOPENAI_BASE_URL=http://host:11434/v1gesetzt werden, weil Firecrawl jetzt den OpenAI-kompatiblen Endpoint von Ollama spricht. - Race-Condition beim Start: Der
api-Container versucht beim Hochfahren sofort, eine Postgres-Verbindung aufzubauen. Postgres braucht aber 10 bis 20 Sekunden, bis es Verbindungen akzeptiert. Resultat: Der API-Container crasht, alle Worker mit ihm. Lösung: Backend-Services zuerst starten, warten, dann erst die API nachziehen.
Damit ist auch klar: Diese Anleitung gilt für den Stand Mai 2026. Wenn Ihr das später nachbaut, lohnt sich ein kurzer Blick in das Firecrawl-Repo, um zu prüfen, ob sich nochmal etwas geändert hat.
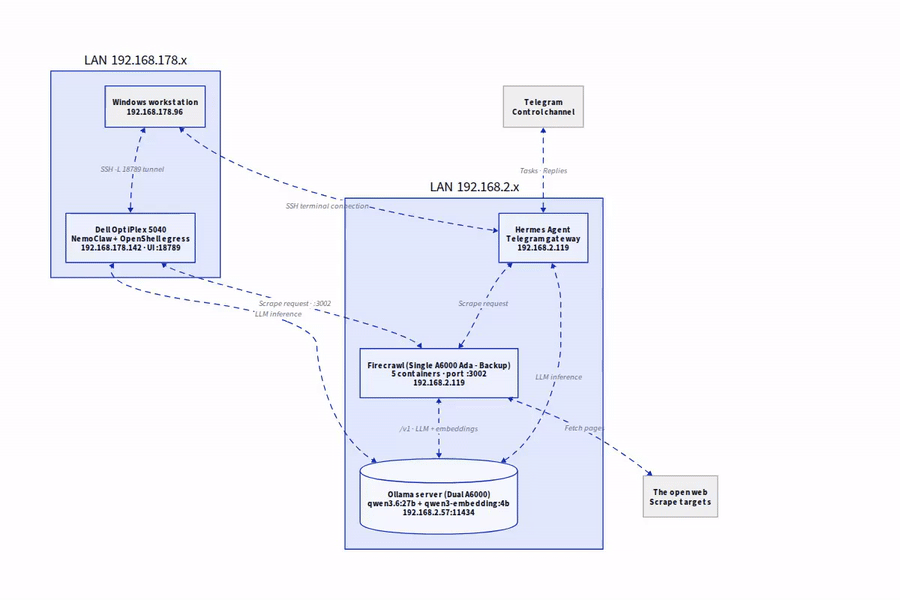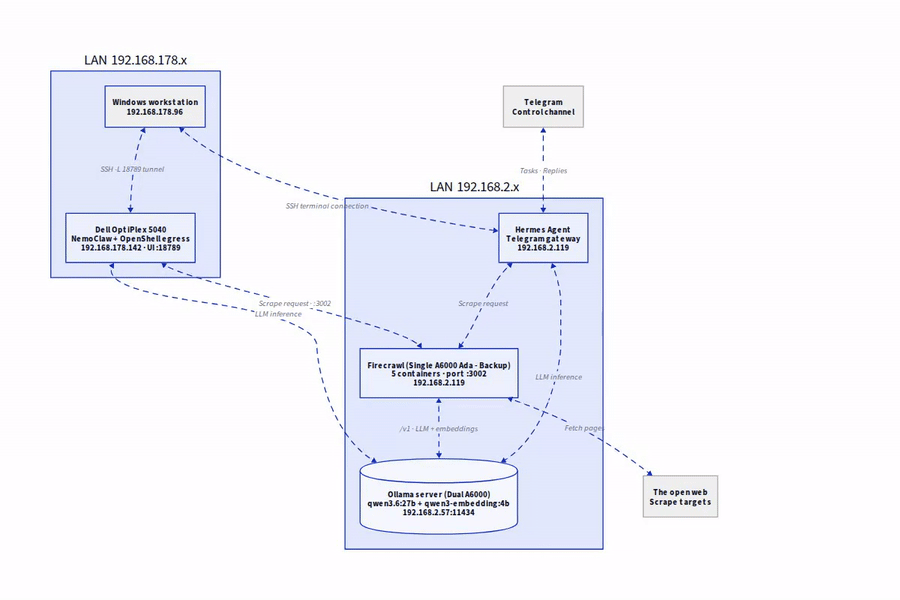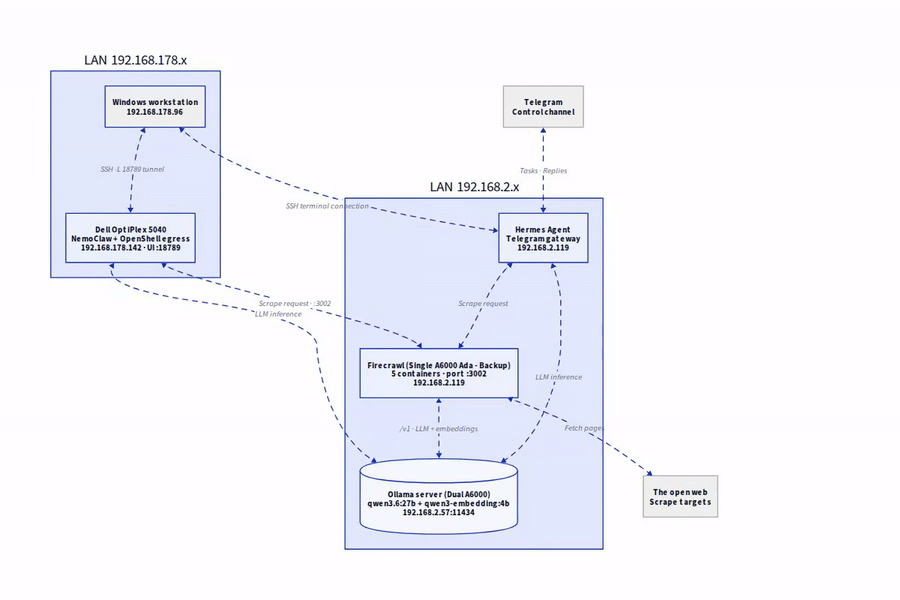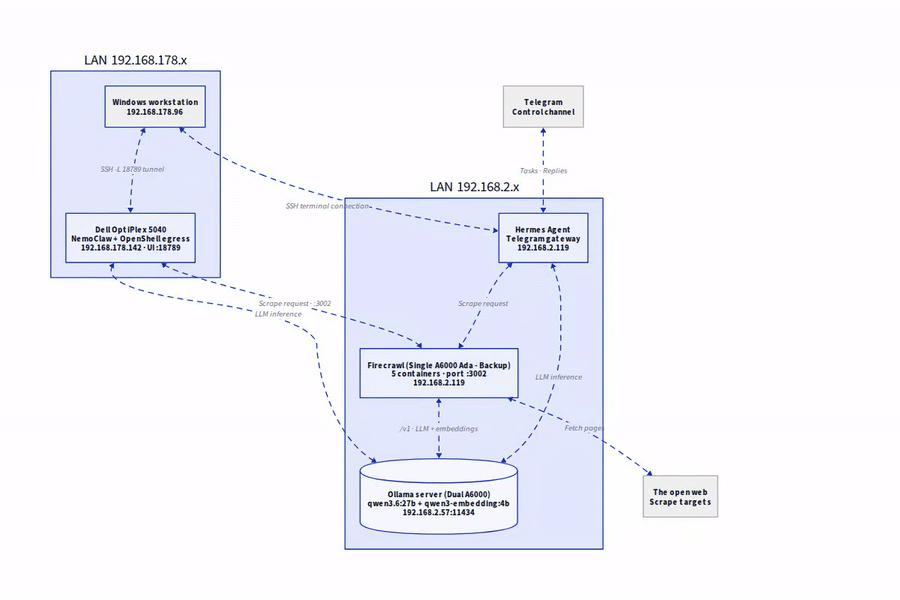
Die Zielarchitektur
Bevor ich loslege, kurz das Gesamtbild:
- Ollama-Host (192.168.2.57): Mein A6000-Server mit den lokalen Modellen
qwen3.6:27bfür Chat undqwen3-embedding:4bfür Embeddings. - Firecrawl-Host (192.168.2.119): Meine A6000Ada-Workstation, auf der der Firecrawl-Stack läuft und Port 3002 bereitstellt.
- Kommunikation: Firecrawl ruft Ollama über den OpenAI-kompatiblen Endpoint
/v1auf. Komplett ohne Cloud, komplett im eigenen LAN.
Warum Firecrawl überhaupt ein LLM und ein Embedding-Modell braucht
Eine berechtigte Zwischenfrage, die ich mir auch gestellt habe, als ich die .env zum ersten Mal vor mir hatte: Wofür braucht ein Web-Scraper denn überhaupt ein Sprachmodell? Lasst mich das kurz aufdröseln, weil die Antwort entscheidend ist für die Modellwahl.
Firecrawl kann tatsächlich vieles ohne KI. Das HTML-Laden, das Markdown-Extrahieren, das Folgen von Links beim Crawl, das Sammeln einer Sitemap all das ist klassische, regelbasierte Software. Wenn Ihr nur einen einfachen scrape mit formats: ["markdown"] aufruft, kommt überhaupt kein LLM zum Einsatz.
Das LLM kommt erst ins Spiel, wenn Ihr strukturierte Extraktion möchtet. Also etwa Firecrawl bittet, aus einer Seite ein JSON-Objekt nach einem bestimmten Schema zu bauen („gib mir Titel, Hauptthemen und Veröffentlichungsdatum als JSON“). Diese semantische Übersetzung von Fließtext in strukturierte Daten kann eine deterministische Regel nicht. Genau dafür braucht es ein Sprachmodell, das den Inhalt versteht und aufbereiten kann.
Das Embedding-Modell hat einen anderen Zweck. Es wandelt Texte in Vektoren um, damit Firecrawl semantisch ähnliche Inhalte vergleichen kann. Das nutzt Firecrawl etwa beim Filtern eines Crawls auf themenrelevante Seiten oder beim Reranking von Suchergebnissen.
In der Praxis heißt das für mein Setup: Mein Agent ruft Firecrawl meistens nur mit dem Wunsch „gib mir Markdown“ auf und macht die eigentliche Analyse selbst mit seinem eigenen Reasoning-Modell. Trotzdem konfiguriere ich beide Modelle in der .env, damit die Premium-Features verfügbar sind, falls ich sie brauche oder mein OpenClaw oder Hermes-Agent das nutzen möchte. Das schadet nicht, denn die Modelle laufen ohnehin auf meinem Ollama-Server. Das Schöne an lokaler KI ist ob Firecrawl sie nutzt oder nicht, kostet mich nichts extra.
Ollama Inferenz-Server vorbereiten
Alle nachfolgenden Schritte laufen auf dem Inferenz-Server ab, auf dem ich Ollama eingerichtet habe. Ollama stellt die Sprachmodelle bereit, die Firecrawl für die oben beschriebenen KI-Features braucht. Ich gehe jetzt nicht darauf ein, wie Ihr Ollama einrichtet und im Netzwerk für alle Rechner als Inferenz-Service verfügbar macht – das habe ich in früheren Beiträgen ausführlich beschrieben.
Wichtig für die weitere Konfiguration von Firecrawl ist, dass die Modelle, die Ihr in der .env konfiguriert, auch tatsächlich auf dem Ollama-Inferenz-Server verfügbar sind.
Modelle prüfen und ggf. herunterladen
Ich verwende einmal das qwen3.6:27b-Modell für Chat und das qwen3-embedding:4b-Modell für Embeddings. Das war es dann auch schon, was Ihr auf Eurem Ollama-Server bereitstellen müsst.
OpenAI-kompatiblen Endpoint testen
Wie schon erwähnt, spricht Firecrawl nicht mehr Ollamas native /api/...-Endpoints, sondern die OpenAI-kompatiblen Endpoints auf /v1/.... Den Test mache ich am besten gleich vom Firecrawl-Host aus, damit ich auch die Netzwerk-Erreichbarkeit verifiziere:
Befehl: curl http://192.168.2.57:11434/v1/models
Erwartete Ausgabe: Eine JSON-Liste mit den lokal verfügbaren Modellen. Falls dort ein 404 zurückkommt, ist Ollama zu alt oder nicht erreichbar.
Docker auf dem Firecrawl-Host installieren
Jetzt sind wir wieder auf dem Rechner, der unser Firecrawl-Host werden soll. Wer Docker und das Compose-Plugin bereits installiert hat, kann diesen Abschnitt überspringen. Mit dem folgenden Befehl könnt Ihr prüfen, ob alles da ist.
Befehl: docker --version && docker compose version
Falls nicht, hier die Kurzfassung der offiziellen Docker-Installation für Ubuntu.
Zunächst entfernen wir einmal die alten Pakete:
for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do
sudo apt-get remove -y $pkg 2>/dev/null
done
Jetzt das offizielle Docker-Repository einbinden:
Befehl: sudo apt-get update
Befehl: sudo apt-get install -y ca-certificates curl
Befehl: sudo install -m 0755 -d /etc/apt/keyrings
Befehl: sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
Befehl: sudo chmod a+r /etc/apt/keyrings/docker.asc
Befehl: echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
Jetzt einmal den Update-Befehl ausführen und anschließend die Docker Engine plus Compose-Plugin installieren:
Befehl: sudo apt-get update
Befehl: sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Jetzt noch den eigenen User zur Docker-Gruppe hinzufügen:
Befehl: sudo usermod -aG docker $USER
Befehl: newgrp docker
Zum Abschluss noch einmal überprüfen, ob alles geklappt hat:
Befehl: docker run --rm hello-world
Jetzt ist alles vorbereitet und wir können Firecrawl auf unseren Host klonen.
Firecrawl klonen
Das Repository klone ich nach /opt/firecrawl und übertrage mir die Owner-Rechte, damit ich später nicht ständig mit sudo arbeiten muss:
Befehl: cd /opt
Befehl: sudo git clone https://github.com/firecrawl/firecrawl.git
Befehl: sudo chown -R $USER:$USER /opt/firecrawl
Befehl: cd /opt/firecrawl
Die zentrale Konfigurationsdatei .env
Hier passieren die meisten Fehler bei Newcomern. Die .env-Datei legt fest, wie Firecrawl mit Ollama spricht und welche Modelle verwendet werden. Achtet vor allem auf die Variablennamen. Diese haben sich gegenüber älteren Anleitungen geändert und haben mir ein paar Probleme bereitet.
Die .env anlegen
Mit dem folgenden Befehl öffnest Du eine noch leere .env-Datei, um diese zu befüllen.
Befehl: nano /opt/firecrawl/.env
Jetzt fügst Du den folgenden Inhalt in die .env-Datei ein. Achte darauf, dass Du die IP-Adresse zu Deinem Ollama-Inferenz-Server anpasst und auch das Modell, das Du nutzen möchtest.
# ===== Pflicht =====
PORT=3002
HOST=0.0.0.0
USE_DB_AUTHENTICATION=false
# ===== Ollama via OpenAI-kompatible API =====
# WICHTIG: Variable heißt jetzt OPENAI_BASE_URL (nicht mehr OLLAMA_BASE_URL!)
# Pfad ist /v1 (nicht mehr /api!)
OPENAI_BASE_URL=http://192.168.2.57:11434/v1
OPENAI_API_KEY=ollama
MODEL_NAME=qwen3.6:27b
MODEL_EMBEDDING_NAME=qwen3-embedding:4b
# ===== Queue-Admin =====
BULL_AUTH_KEY=CHANGE_ME_TO_A_LONG_RANDOM_STRING
# ===== Optional: lokale Webhooks erlauben =====
ALLOW_LOCAL_WEBHOOKS=true
Mit STRG+X, dann Y und ENTER speicherst Du die Änderungen ab.
Sicheren BULL_AUTH_KEY generieren
Den Platzhalter CHANGE_ME_TO_A_LONG_RANDOM_STRING ersetze ich durch einen echten Zufallsstring:
Befehl: openssl rand -hex 32
Die Ausgabe in die .env einsetzen. Dieser Key landet später in der Admin-URL für die Queue, also wirklich zufällig und lang.
Die drei wichtigsten Punkte zur .env
- Der Variablenname
OPENAI_BASE_URList neu. Frühere Anleitungen verwendenOLLAMA_BASE_URL. Diese Variable wird aber von der aktuellen Codebase ignoriert. - Der Pfad
/v1statt/apiist Pflicht. Denn Firecrawl spricht den OpenAI-kompatiblen Endpoint von Ollama. - Der OPENAI_API_KEY muss gesetzt sein, akzeptiert aber jeden beliebigen String. Ich nehme einfach
ollamaals Dummy.
Self-Hosting unterstützt übrigens kein Supabase und kein Fire-engine. Die vielen Warnungen, die Ihr gleich beim Start sehen werdet, über fehlende SUPABASE_*, SEARXNG_* und SLACK_*-Variablen sind alle erwartet und harmlos.
Build & Start von Firecrawl – Achtung Race-Condition!
Das ist die Phase, in der die meisten Anleitungen einfach docker compose up -d empfehlen, und dann muss man leider das Gesicht verziehen, weil nichts läuft. Genau so ist es mir auch passiert. Mag vielleicht an meiner Hardware liegen aber gleich mehr dazu.
Container-Images bauen
Jetzt bauen wir erst einmal mit dem folgenden Befehl die Container-Images:
Befehl: cd /opt/firecrawl && docker compose build
Der erste Build dauert je nach Hardware 15 bis 35 Minuten. Auf meiner Workstation waren es etwa 25 Minuten. Plant das mit ausreichend Tee oder Kaffee ein.
Der gestaffelte Start
Wenn Ihr jetzt einfach docker compose up -d ausführt, passiert mit hoher Wahrscheinlichkeit Folgendes:
- Alle Container werden als „Started“ gemeldet.
- Sekunden später ist der
firecrawl-api-1-Container wieder weg. - In den Logs des API-Containers steht
ECONNREFUSED 172.19.0.2:5432.
Das ist die Race-Condition mit Postgres. Der Worker nuq-prefetch-worker im API-Container versucht sofort beim Start eine Postgres-Verbindung und stirbt, wenn Postgres noch nicht bereit ist. Das reißt den ganzen API-Container mit sich und damit alle Worker-Prozesse.
Mein Workaround für ein erstes manuelles Hochfahren sind vier Schritte:
Schritt 1: Backend-Services starten und warmlaufen lassen.
Befehl: docker compose up -d nuq-postgres rabbitmq redis playwright-service
Schritt 2: 20 Sekunden warten, bis Postgres Verbindungen akzeptiert.
Befehl: sleep 20
Schritt 3: Optional verifizieren, dass Postgres bereit ist.
Befehl: docker compose logs nuq-postgres --tail=5
Erwartet wird in der Ausgabe die Zeile database system is ready to accept connections.
Schritt 4: API-Container nachziehen.
Befehl: docker compose up -d api
Hinweis zum festen sleep: Für ein manuelles Hochfahren, bei dem Ihr zuschaut, sind die 20 Sekunden okay. Verlässlich ist eine feste Wartezeit aber nicht – Postgres kann nach einem Reboot auch länger brauchen, und startet die API zu früh, stirbt sie sofort mit ECONNREFUSED ...:5432. Für den automatischen, reboot-festen Start zeige ich Euch im nächsten Abschnitt die robuste Variante, die aktiv auf die Bereitschaft von Postgres wartet.
Status prüfen
Jetzt bitte einmal mit dem folgenden Befehl prüfen, ob alle Container laufen und bereit sind.
Befehl: docker compose ps
Erwartet werden jetzt fünf laufende Container:
firecrawl-api-1(mit eingebetteten Workern)firecrawl-nuq-postgres-1firecrawl-rabbitmq-1firecrawl-redis-1firecrawl-playwright-service-1
Alle mit Status Up. Wenn der API-Container Exited zeigt oder ganz fehlt, schaut Ihr in die Logs:
Befehl: docker compose logs api --tail=80
Den Stack reboot-fest machen: systemd, Restart-Policy und ein RabbitMQ-Stolperstein
Ein Punkt, der mir nach den ersten Tests noch auf die Füße gefallen ist: Nach einem Neustart des Firecrawl-Hosts war der komplette Stack weg – ein docker compose ps zeigte keine Container mehr. Der Grund: Die Container haben keine Restart-Policy, also fährt Docker sie beim Boot nicht von allein hoch. Und selbst wenn, würden sie alle gleichzeitig starten und genau in die Race-Condition von oben laufen.
Die belastbare Lösung besteht aus drei Bausteinen, die ich mir der Reihe nach erarbeitet habe: ein geordneter Autostart per systemd, eine Restart-Policy als Sicherheitsnetz und – als letzter, überraschender Stolperstein – ein fester Erlang-Cookie für RabbitMQ.
Baustein 1: Geordneter Start per Skript
Die Idee ist dieselbe wie beim manuellen Start, nur automatisiert: erst die Backend-Dienste, dann aktiv warten, bis Postgres wirklich Verbindungen annimmt (per pg_isready, nicht per fester Wartezeit), und erst danach die API. Entscheidend ist das Warten auf Postgres, nicht auf RabbitMQ – RabbitMQ ist oft in wenigen Sekunden gesund, während Postgres länger braucht, und genau dieser Unterschied ist die Race.
Befehl: nano /opt/firecrawl/start-firecrawl.sh
#!/usr/bin/env bash
set -euo pipefail
cd /opt/firecrawl
# 1. Backend-Dienste starten
docker compose up -d nuq-postgres rabbitmq redis playwright-service
# 2. Aktiv warten, bis Postgres Verbindungen annimmt (DAS ist die eigentliche Race)
echo "Warte auf nuq-postgres ..."
until docker compose exec -T nuq-postgres pg_isready -q 2>/dev/null; do sleep 2; done
# 3. Sicherheitshalber auch auf RabbitMQ healthy warten
echo "Warte auf rabbitmq (healthy) ..."
until [ "$(docker inspect -f '{{.State.Health.Status}}' firecrawl-rabbitmq-1 2>/dev/null)" = "healthy" ]; do sleep 2; done
# 4. Erst jetzt die API nachziehen
docker compose up -d api
Ausführbar machen:
Befehl: chmod +x /opt/firecrawl/start-firecrawl.sh
Baustein 2: Die systemd-Unit
Damit das Skript bei jedem Boot läuft, kapsele ich es in eine systemd-Unit.
Befehl: sudo nano /etc/systemd/system/firecrawl.service
[Unit]
Description=Firecrawl Stack (gestaffelter Start)
Requires=docker.service
After=docker.service network-online.target
Wants=network-online.target
[Service]
Type=oneshot
RemainAfterExit=yes
WorkingDirectory=/opt/firecrawl
ExecStart=/opt/firecrawl/start-firecrawl.sh
ExecStop=/usr/bin/docker compose down
TimeoutStartSec=300
[Install]
WantedBy=multi-user.target
Aktivieren:
Befehl: sudo systemctl daemon-reload
Befehl: sudo systemctl enable firecrawl.service
Baustein 3: Restart-Policy als Sicherheitsnetz
Das geordnete Warten trifft das Zeitfenster fast immer – aber „fast“ reicht mir nicht. Der api hat keinen internen Retry: Schlägt die allererste Postgres-Verbindung fehl, reißt es den ganzen Container. Deshalb gebe ich ihm eine Restart-Policy, damit Docker ihn nach einem Crash schlicht neu startet, bis Postgres bereit ist. Das mache ich über eine docker-compose.override.yaml, damit die Upstream-Compose unangetastet bleibt – Compose mischt diese Datei automatisch dazu. Die endgültige Fassung dieser Datei zeige ich gleich im nächsten Schritt, weil dort noch der Cookie hinzukommt.
Baustein 4: Der RabbitMQ-Stolperstein nach dem Reboot
Jetzt der Teil, der mich beim ersten echten Reboot überrascht hat: Trotz allem startete RabbitMQ nicht mehr, und in docker compose logs rabbitmq stand:
Error when reading /var/lib/rabbitmq/.erlang.cookie: eaccesDas ist keine Datenkorruption, sondern ein Rechteproblem: Der Reboot hatte die Zugriffsrechte des Erlang-Cookies verbogen, und ohne lesbaren Cookie startet der Knoten gar nicht erst. Weil das Startskript auf einen gesunden RabbitMQ wartet, hängt dann der ganze Start.
Zwei Schritte beheben das dauerhaft. Erstens den kaputten Zustand einmalig zurücksetzen – die Queue ist transient, es geht nichts Wertvolles verloren:
Befehl: docker compose rm -sfv rabbitmq
Zweitens den Cookie fest vorgeben, damit RabbitMQ ihn bei jedem Start mit korrekten Rechten neu schreibt, statt von der alten Datei abzuhängen. Dazu erzeugt Ihr einen Zufallsstring …
Befehl: openssl rand -hex 16
… und tragt ihn in die Override-Datei ein. So sieht die fertige docker-compose.override.yaml aus – inklusive der Restart-Policies aus Baustein 3:
Befehl: nano /opt/firecrawl/docker-compose.override.yaml
services:
api:
restart: on-failure
rabbitmq:
restart: on-failure
environment:
RABBITMQ_ERLANG_COOKIE: "HIER_EUER_ZUFALLSSTRING"
(Neuere RabbitMQ-Versionen drucken dazu eine Deprecation-Warnung – die könnt Ihr ignorieren, die Variable wird weiterhin ausgewertet.)
Aktivieren und der ehrliche Reboot-Test
Einmal sauber durchstarten:
Befehl: sudo systemctl restart firecrawl
Und dann der eigentliche Beweis – ein echter Neustart:
Befehl: sudo reboot
Nach dem Hochfahren prüft Ihr auf dem Firecrawl-Host, ob alle fünf Container von allein laufen:
Befehl: cd /opt/firecrawl && docker compose ps
RabbitMQ sollte als (healthy) erscheinen und der api mit 0.0.0.0:3002. Im Journal von systemctl status firecrawl seht Ihr den geordneten Ablauf rabbitmq Healthy → api Started. Ab jetzt übersteht der Stack jeden Neustart ohne Handarbeit.
Funktionstest
Jetzt müssen wir nur noch herausfinden, ob Firecrawl wirklich bei uns auf dem Host läuft. Dazu habe ich am Host selbst im Terminal-Fenster den folgenden Befehl ausgeführt:
Befehl: curl http://localhost:3002/
Erwartete Antwort:
{"message":"Firecrawl API","documentation_url":"https://docs.firecrawl.dev"}
Einfacher Scrape
curl -X POST http://localhost:3002/v2/scrape \
-H 'Content-Type: application/json' \
-d '{
"url": "https://ai-box.eu",
"formats": ["markdown"]
}'
Erwartete Antwort: Ein JSON-Objekt mit dem Feld data.markdown, in dem die gescrapete Seite als Markdown steht. Das ist der Moment, an dem ich mir immer kurz die Hände reibe. Jetzt habe ich meinen eigenen Web-Scraper, vollständig lokal im eigenen Netzwerk.
KI-Feature testen
Um die Ollama-Anbindung zu verifizieren, starten wir jetzt einen strukturierten Scrape, der das Ergebnis im vorgegebenen JSON-Format zurückgibt:
Befehl: curl -X POST http://localhost:3002/v2/scrape -H 'Content-Type: application/json' -d '{
"url": "https://ai-box.eu",
"formats": [{
"type": "json",
"schema": {
"type": "object",
"properties": {
"title": {"type": "string"},
"main_topics": {"type": "array", "items": {"type": "string"}}
}
}
}]
}'
Wenn ein sauberes, strukturiertes JSON mit Titel und Themen zurückkommt, funktioniert Eure Ollama-Anbindung.
Queue-Admin-UI
Im Browser aufrufen:
URL: http://<firecrawl-host>:3002/admin/<BULL_AUTH_KEY>/queues
Hier seht Ihr laufende, fehlgeschlagene und wartende Jobs. Praktisch zum Debugging und Monitoring während längerer Crawl-Sessions.
Mein persönliches Fazit
Firecrawl im eigenen LAN zu betreiben war für mich der nächste konsequente Schritt im Sovereign-AI-Setup: Wenn ich schon meinen Ollama-Server lokal habe und meinen Agenten-Host (NemoClaw) lokal habe, dann gehört auch die Web-Recherche-Komponente in den eigenen Maschinenpark. Mit diesem Setup kann mein Agent jetzt Webseiten lesen und durchsuchen, ohne dass dabei auch nur ein Byte das Haus verlässt. Genau das Mindset, das mich an dem ganzen lokalen KI-Thema reizt.
Was mich beim Aufsetzen am meisten Nerven gekostet hat, waren weniger die Linux-Standardaufgaben, sondern die veralteten Anleitungen im Netz. Ich habe gut zwei Stunden damit verbracht zu verstehen, warum mein API-Container immer wieder stirbt. Es hatte etwas gedauert bis ich kapiert habe, dass es nicht an meinem Setup liegt, sondern an einer Race-Condition, die im aktuellen Build der Codebase steckt. Genau deswegen schreibe ich diese aktualisierte Anleitung: Damit Ihr euch die Zeit spart, die ich gebraucht habe.
Im nächsten Beitrag zeige ich Euch dann, wie ich diese Firecrawl-Instanz an meinen OpenClaw-Agenten in der NemoClaw-Sandbox angebunden habe inklusive der knackigen OpenShell-Egress-Policy, die ich dafür konfigurieren musste. Das ist der eigentlich spannende Teil, in dem alle Bausteine zusammenkommen.
Wir lesen uns im nächsten Teil!






{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…