
Mein Homelab-Server mit zwei NVIDIA RTX A6000 macht im Alltag KI-Inferenz. Er bedient lokale Sprachmodelle und bleibt dabei souverän in den eigenen vier Wänden. An diesem Wochenende wollte ich aber etwas ganz anderes ausprobieren. Können die beiden Karten auch eine klassische Finanzaufgabe rechnen? Konkret die Optimierung eines Wertpapier-Portfolios direkt auf der GPU.
Das Werkzeug dafür heißt cuFOLIO. cuFOLIO ist ein Blueprint von NVIDIA. Ein Blueprint ist eine fertige Referenz-Implementierung zum Nachbauen. Dieser hier dreht sich um Portfolio-Optimierung auf der GPU. Portfolio-Optimierung beantwortet eine klassische Frage. Wie verteile ich mein Kapital über viele Wertpapiere? Und zwar so, dass das Verhältnis aus Rendite und Risiko möglichst gut wird.
Üblicherweise misst man das Risiko über die Schwankungsbreite der Kurse, also die Varianz. cuFOLIO nimmt ein anderes Maß: CVaR, den Conditional Value-at-Risk. CVaR schaut gezielt auf die schlechten Tage. Die Kernfrage lautet: Wenn es richtig schlecht läuft, wie groß ist der Verlust im Schnitt? Genau diese Extremfälle bildet CVaR ab. „Mean-CVaR“ verbindet nun beide Seiten. Der „Mean“ ist die erwartete Rendite, die Du maximieren willst. Der „CVaR“ ist das Verlustrisiko im schlechten Fall, das Du begrenzen willst. Die Optimierung wägt beides gegeneinander ab. Sie sucht die Gewichtung, die bei akzeptablem Verlustrisiko die beste erwartete Rendite bringt. Das löst cuFOLIO direkt auf der Grafikkarte.
Das praktische Beispiel dazu liefert NVIDIA aber nur als Jupyter-Notebook. Genau das stört mich. Ein Notebook lässt sich schlecht automatisieren und schlecht versionieren. Also baue ich das cvar_basic-Beispiel als ausführbares Python-Skript nach. Das Ziel für diesen Beitrag ist bewusst bescheiden. Es soll sauber auf meinem Dual-A6000-Server durchlaufen. NVIDIA geht nämlich davon aus, dass ein H100-System oder etwas Vergleichbares zum Einsatz kommt. Daher wird es spannend, ob ich cuFOLIO überhaupt auf meiner Hardware zum Laufen bekomme.
Den Quellcode und das Beispiel findest Du im offiziellen Repository: cuFOLIO auf GitHub. Dort liegt auch das Original-Notebook notebooks/cvar_basic.ipynb, das ich hier ersetze.
- Hardware: 2× RTX A6000 (Ampere)
- Stack: cuOpt, cuML, CUDA 13
- Ziel: headless und einfach lauffähig
Worum es geht
NVIDIA führt cuFOLIO auch unter dem Namen „Quantitative Portfolio Optimization“. Technisch gießt cuFOLIO das Mean-CVaR-Problem in ein lineares Programm. Das ist ein Optimierungsmodell, dessen Ziel und Bedingungen sich als lineare Ausdrücke schreiben lassen. Dieses Modell löst der cuOpt-Solver auf der GPU. cuOpt ist NVIDIAs GPU-Solver für Optimierungsprobleme. Vorher braucht der Solver viele mögliche Zukunftsszenarien für die Kursverläufe. Die erzeugt cuML per Kernel-Density-Estimation. cuML ist die GPU-Bibliothek für maschinelles Lernen aus dem RAPIDS-Projekt. RAPIDS ist NVIDIAs Sammlung von GPU-Bibliotheken für Datenverarbeitung. Kernel-Density-Estimation (kurz KDE) schätzt aus den historischen Renditen eine Verteilung. Daraus zieht sie dann tausende Stichproben. Auch dieser Schritt läuft auf der GPU.
Mir ist ein reproduzierbares Skript lieber als eine Notebook-Sitzung. Das ist besser für systemd, Cron und Versionierung. Also zerlege ich das Notebook in seine sechs Stufen. Sie landen in einem einzigen run_cvar.py.
Die Pipeline: Daten (yfinance) → Log-Returns → KDE-Szenarien (GPU) → Mean-CVaR → cuOpt-Solve (GPU) → Backtest. Log-Returns sind die logarithmierten Tagesrenditen. Ein Backtest ist ein Rückblick-Test. Er spielt die gefundene Gewichtung an historischen Kursen durch und zeigt, wie sich das Portfolio geschlagen hätte.
Erwartungs-Check: Ampere statt H100. cuFOLIO empfiehlt offiziell den H100 ab Compute Capability 9.0. Compute Capability ist die Versionsnummer der GPU-Architektur. Sie sagt, welche Funktionen die Karte in Hardware beherrscht. Meine A6000 sind Ampere mit Compute Capability 8.6. RAPIDS und cuOpt laufen darauf problemlos. Die 48 GB pro Karte sind für dieses Problemformat reichlich. Die Schlagzeilen-Speedups (100 bis 160×) beziehen sich auf den H100. Auf Ampere läuft es genauso, nur nicht ganz so schnell. Für die Frage „läuft es überhaupt sauber durch?“ ist das völlig irrelevant.
Voraussetzungen
- NVIDIA-GPU mit aktuellem Treiber. Für CUDA 13 ist das Treiber 580.65.06 oder neuer. Dazu Docker und das NVIDIA Container Toolkit.
- Ein paar GB freier Plattenplatz. Die SP500-Kursdaten werden per
yfinancegeladen. yfinance ist eine Python-Bibliothek, die Kursdaten von Yahoo Finance abruft. - Internetzugang für den ersten Container-Pull und den Datendownload.
1. Projektordner anlegen und Container starten
cuFOLIO ist auf den NVIDIA-PyTorch-Container abgestimmt. Bevor Du ihn startest, legst Du Dir auf dem Host einen Projektordner an. Das ist wichtig. Der Container wird gleich mit --rm gestartet und nach dem Beenden wieder gelöscht. Nur was in dem gemounteten Host-Ordner liegt, überlebt diesen Neustart.
Befehl: mkdir cufolio-projekt
Befehl: cd cufolio-projekt
Jetzt startest Du den Container aus diesem Ordner heraus. Das -v "$PWD":/workspace/host hängt Dein aktuelles Verzeichnis im Container unter /workspace/host ein.
Befehl: docker run --gpus all -it --rm -v "$PWD":/workspace/host --ipc=host nvcr.io/nvidia/pytorch:25.10-py3
Der Container 25.10 bringt CUDA 13 mit. Welche CUDA-Version aktiv ist, zeigt der Startbanner des Containers an. Bei mir stand dort die entscheidende Zeile:
NOTE: CUDA Forward Compatibility mode ENABLED.
Using CUDA 13.0 driver version 580.95.05 with kernel driver version 575.57.08.
CUDA 13 ist also aktiv. Das entscheidet gleich über das passende Paket-Extra. Die Meldung groups: cannot find name for group ID 992 kannst Du übrigens ignorieren. Sie ist nur kosmetisch.
Im Container wechselst Du als Erstes in den gemounteten Ordner. Erst dort klonst Du das Repo. So liegt am Ende alles physisch auf Deinem Host und ist nach dem Beenden des Containers noch da.
Befehl: cd /workspace/host
2. Umgebung mit uv aufsetzen
cuFOLIO nutzt uv als Paketmanager. uv ist ein schneller Paket- und Umgebungsmanager für Python. Die GPU-Pakete cuML und cuOpt kommen aus dem NVIDIA-Index. Sie werden über ein CUDA-Extra ausgewählt. Diese Schritte stecken im beigelegten setup_cufolio.sh. Hier die einzelnen Kommandos, im Container ausgeführt.
Zuerst das Repo klonen und hineinwechseln.
Befehl: git clone https://github.com/NVIDIA-AI-Blueprints/cuFOLIO.git
Befehl: cd cuFOLIO
Dann uv installieren und die Umgebung laden.
Befehl: curl -LsSf https://astral.sh/uv/install.sh | sh
Befehl: source "$HOME/.local/bin/env"
Der zweite Befehl gibt nichts aus. Das ist Absicht. Er macht nur das Programm uv in Deiner Shell auffindbar. Die virtuelle Umgebung musst Du nicht von Hand aktivieren. Das nimmt Dir uv run später automatisch ab.
Zuletzt die GPU-Pakete passend zur CUDA-Version des Containers ziehen. Für CUDA 13 (PyTorch-Container 25.10):
Befehl: uv sync --extra cuda13
Falls Du einen CUDA-12-Container nutzt, stattdessen:
Befehl: uv sync --extra cuda12
uv sync legt automatisch eine virtuelle Umgebung an. Es installiert alles aus der uv.lock. Dazu gehört auch das lokale Paket cufolio. Es bildet den src/-Ordner ab. Bei mir brach der erste Versuch an einem Netzwerk-Timeout ab, ein einzelnes Paket ließ sich nicht laden. Das ist kein Drama. Ich habe denselben Befehl einfach ein zweites Mal abgesetzt. Dann zieht uv nur das Fehlende nach und meldet am Ende sauber alle 125 Pakete als installiert.
3. Das Notebook durch ein Skript ersetzen
Jetzt der Kern. run_cvar.py bildet die sechs Stufen aus cvar_basic.ipynb 1:1 ab, aber headless. Headless heißt: ohne grafische Oberfläche, rein über die Kommandozeile. Wichtig für den Notebook-freien Betrieb ist matplotlib.use("Agg") ganz oben. Sonst versucht die Backtest-Visualisierung, ein Fenster zu öffnen, und scheitert. Praktisch ist der --check-Schalter. Er prüft vorab, ob beide Karten und der GPU-Stack sichtbar sind. Den vollen Lauf startet er dabei noch nicht.
Die Datei gehört direkt in das cuFOLIO-Verzeichnis, also dorthin, wo auch die pyproject.toml liegt. Nur dann findet uv run python run_cvar.py die Datei ohne Pfadangabe und nutzt die richtige Umgebung. Weil der Ordner auf den Host gemountet ist, übersteht das Skript auch jeden Reboot. Am bequemsten legst Du die Datei auf dem Host an, in einem zweiten Terminal außerhalb des Containers.
Befehl: cd ~/cufolio-projekt/cuFOLIO
Befehl: nano run_cvar.py
Den vollständigen Code von run_cvar.py findest Du in meinem Repository: run_cvar.py auf GitHub.
Kopiere ihn in die Datei, speichere mit Strg+O und schließe den Editor mit Strg+X. Durch das Mount taucht die Datei im Container sofort unter /workspace/host/cuFOLIO/run_cvar.py auf.
4. Erst prüfen, dann laufen lassen
Vor dem vollen Lauf kommt der Smoke-Test. Ein Smoke-Test ist ein schneller Check, ob die Grundvoraussetzungen überhaupt erfüllt sind. Er listet beide A6000 mit Compute Capability. Und er meldet, ob cuML, cuOpt und cufolio importierbar sind.
Befehl: uv run python run_cvar.py --check
Bei mir sah das so aus. Beide Karten werden erkannt, der ganze Stack ist importierbar:
== GPU-Check ==
0, NVIDIA RTX A6000, 49140 MiB, 8.6
1, NVIDIA RTX A6000, 49140 MiB, 8.6
cuml OK 26.04.000
cuopt OK 26.04.000
cvxpy OK 1.9.2
cufolio OK
Wenn alle Zeilen OK zeigen, ist das Setup bereit.
Beide A6000 tauchen mit je rund 49 GB Speicher und Compute Capability 8.6 auf. Das ist genau die Ampere-Karte, bei der vorher die Frage im Raum stand, ob cuFOLIO darauf überhaupt anläuft. Dass cufolio keine Versionsnummer zeigt, ist kein Fehler. Das Paket meldet einfach keine, und das Skript gibt dann nur das „OK“ aus.
Der eigentliche Lauf
Jetzt der scharfe Durchlauf ohne --check.
Befehl: uv run python run_cvar.py
Der erste Lauf lädt zuerst die SP500-Kurse über yfinance. Das dauert einen Moment. Hier war ich ehrlich gespannt, denn yfinance ist beim Download gern mal zickig. Genau so kam es auch. Ein paar Titel brachen weg, einer lief in einen Verbindungs-Timeout. Das ist unkritisch. Das Skript fängt das ab und rechnet mit den Titeln, die ankommen. Am Ende lagen 386 von rund 500 Werten vor. Für einen „läuft es?“-Test ist das mehr als genug.
Der gekürzte Ablauf im Terminal sah so aus:
[1/6] Lade Daten nach data/stock_data/sp500.csv ...
Saved 386 tickers to data/stock_data/sp500.csv
[2/6] Berechne Returns ...
[3/6] Erzeuge 10000 KDE-Szenarien (GPU) ...
[4/6] Loese Mean-CVaR auf der GPU (cuOpt PDLP) ...
[5/6] Optimiertes Portfolio:
[6/6] Backtest gegen Equal-Weight ...
Combined plot saved: results/run_cvar/combined_cuopt_optimal_historical_analysis.png
Fertig. Ergebnisse in: results/run_cvar
Damit ist das eigentliche Ziel erreicht. cuFOLIO läuft auf den A6000, headless und ohne Notebook. Am Ende liegen portfolio.json und die Backtest-Grafik in results/run_cvar/. Weil ich im gemounteten Host-Ordner arbeite, finde ich beides auch direkt auf dem Host unter ~/cufolio-projekt/cuFOLIO/results/run_cvar/.
Die Zahlen aus dem Solve
Spannend ist, wie schnell cuOpt das Problem löst. Der Solver bearbeitet das Mean-CVaR-Modell für 386 Titel und 10.000 Szenarien in deutlich unter einer Sekunde.
| Kennzahl | Wert |
|---|---|
| Erwartete Rendite | 0,2542 % |
| CVaR (95 %) | 2,5949 % |
| Zielwert (Objective) | -0,001473 |
| Setup-Zeit | 0,3574 s |
| CVXPY-Overhead | 0,1118 s |
| Solve-Zeit | 0,9280 s |
cuFOLIO 25.10 · cuOpt PDLP · 2026-06-28 · Modell: Mean-CVaR · 386 Titel · 10.000 Szenarien · Zeitraum 2021-01-01 bis 2024-01-01 · Konfidenz 95 % · 1× RTX A6000
Unter einer Sekunde Solve-Zeit für ein Problem dieser Größe. Und das auf der angeblich „zu alten“ Ampere-Karte. Genau das bestätigt meinen Erwartungs-Check von oben. Für dieses Problemformat ist die A6000 mehr als ausreichend.
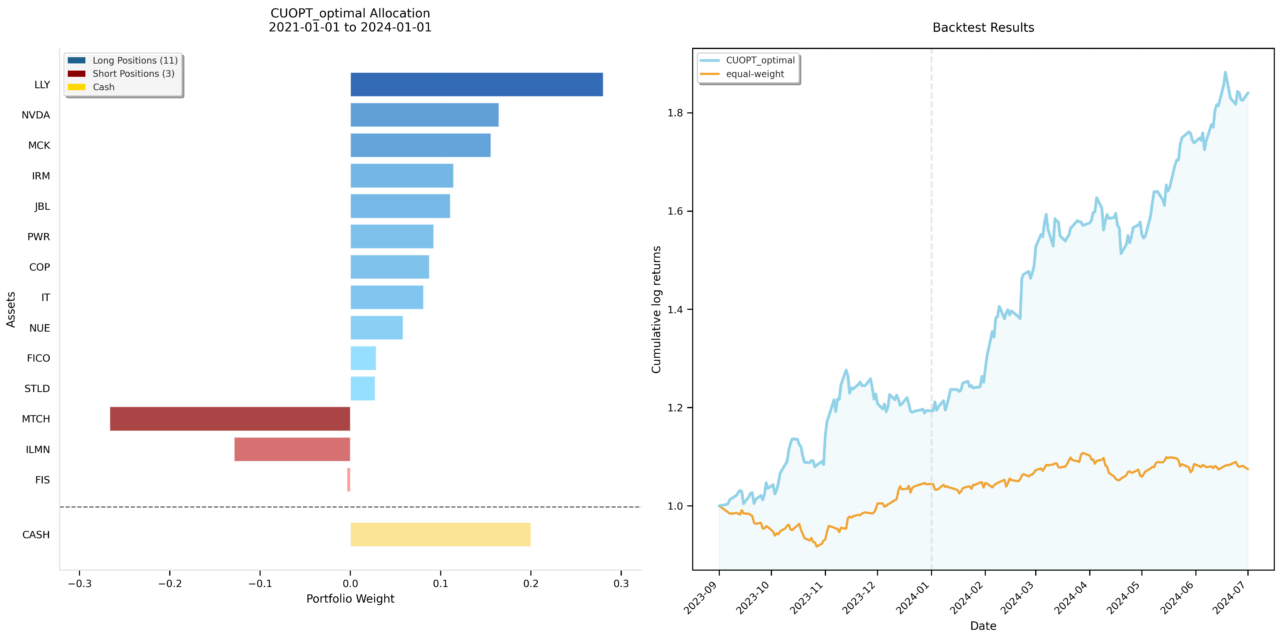
Das optimierte Portfolio
Heraus kommt ein konkretes Portfolio. Es hat elf Long-Positionen, drei Short-Positionen und eine Cash-Quote. Eine Long-Position setzt auf steigende Kurse. Eine Short-Position setzt auf fallende Kurse. Die Summe der Long-Gewichte liegt bei 120 %, die der Shorts bei knapp -40 %. Die Differenz wird durch die Cash-Quote ausgeglichen.
| Titel | Richtung | Gewicht |
|---|---|---|
| LLY | Long | 28,02 % |
| NVDA | Long | 16,44 % |
| MCK | Long | 15,56 % |
| IRM | Long | 11,41 % |
| JBL | Long | 11,07 % |
| PWR | Long | 9,22 % |
| COP | Long | 8,75 % |
| IT | Long | 8,08 % |
| NUE | Long | 5,84 % |
| FICO | Long | 2,86 % |
| STLD | Long | 2,74 % |
| MTCH | Short | -26,68 % |
| ILMN | Short | -12,90 % |
| FIS | Short | -0,41 % |
| Cash | Liquidität | 20,00 % |
cuFOLIO 25.10 · Portfolio CUOPT_OPTIMAL · Zeitraum 2021-01-01 bis 2024-01-01 · Gross Exposure 159,58 % · Net Equity 80,41 %
Die größte Long-Position ist LLY mit 28 %, gefolgt von NVDA mit 16 %. Auf der Short-Seite stehen MTCH und ILMN deutlich im Minus, dazu eine winzige Short-Position in FIS. Diese FIS-Position liegt mit 0,41 % unter einem Prozent. Deshalb taucht sie in der gekürzten Terminal-Ausgabe gar nicht auf, denn das Skript blendet dort alles unter 1 % aus. In der Grafik mit allen Positionen ist sie aber sichtbar, weshalb das Bild von „Short Positions (3)“ spricht. Das Brutto-Exposure von rund 160 % zeigt, dass hier mit Hebel gearbeitet wird. Long und Short zusammen ergeben mehr als das eingesetzte Kapital. Das ist im Modell so vorgesehen und über die Parameter im Skript begrenzt. Die vollständige Gewichtung aller 386 Titel landet als portfolio.json im Ergebnisordner, falls Du jede einzelne Position nachsehen willst.
Backtest gegen Equal-Weight
Zum Schluss prüft das Skript, wie sich das optimierte Portfolio im Rückblick geschlagen hätte. Als Vergleichsbasis dient ein Equal-Weight-Portfolio. Equal-Weight heißt: jeder Titel bekommt das gleiche Gewicht, ganz ohne Optimierung. Zwei Kennzahlen lassen sich gut ablesen.
| Kennzahl | CUOPT optimal | Equal-Weight |
|---|---|---|
| Sortino-Ratio | 6,26 | 1,45 |
| Max Drawdown | 6,98 % | 8,25 % |
cuFOLIO 25.10 · Backtest historisch · Testzeitraum 2023-09-01 bis 2024-07-01 · Vergleich gegen Equal-Weight
Die Sortino-Ratio misst die Rendite im Verhältnis zum Verlustrisiko. Höher ist besser. Der maximale Drawdown ist der größte zwischenzeitliche Verlust vom Höchststand aus. Niedriger ist besser. In beiden Punkten liegt das optimierte Portfolio klar vorne. Die Sortino-Ratio ist mehr als viermal so hoch, und der Drawdown fällt geringer aus. Auch in der Grafik ist der Abstand deutlich. Die Kurve des optimierten Portfolios zieht über den Testzeitraum sichtbar davon und endet bei rund 1,8, während die Equal-Weight-Basis kaum über 1,07 hinauskommt. Für einen Wochenend-Test ist das ein erfreulich deutliches Bild.
cuFOLIO Backtest
5. Optional: beide A6000 nutzen
Für den reinen Lauf reicht eine Karte locker. Die zweite bringt erst dann etwas, wenn Du viele unabhängige Optimierungen fährst. Etwa mehrere Zeiträume oder Parametervarianten. Dann startest Du pro GPU einen Prozess. So verdoppelst Du den Durchsatz. --gpu-id setzt im Skript intern CUDA_VISIBLE_DEVICES. Damit pinnt es den Prozess sauber auf eine Karte.
Starte pro GPU einen Prozess im Hintergrund. Warte am Ende auf beide.
Befehl: uv run python run_cvar.py --gpu-id 0 --regime-range 2015-01-01 2021-01-01 &
Befehl: uv run python run_cvar.py --gpu-id 1 --regime-range 2021-01-01 2024-01-01 &
Befehl: wait
cuFOLIO selbst parallelisiert nicht automatisch über beide Karten. Diese Orchestrierung machst Du. Für den ersten „läuft es?“-Test brauchst Du das aber gar nicht.
Stolpersteine
Falsches CUDA-Extra. cuda12 und cuda13 schließen sich aus. Lies erst die CUDA-Version aus dem Container-Banner oder mit nvidia-smi. Wähle dann das passende --extra. Sonst zieht uv inkompatible cuML/cuOpt-Wheels.
Timeout beim uv sync. Einzelne Pakete laufen beim Download gelegentlich in einen Timeout. Setze einfach denselben uv sync-Befehl noch einmal ab. uv zieht dann nur das Fehlende nach.
„No space left on device“ beim uv sync. Die GPU-Wheels sind groß. Lenke den Cache um. Setze dazu export UV_CACHE_DIR=/workspace/host/.uvcache auf ein Volume mit Platz. Auch dieser Cache zeigt bewusst in den Host-Ordner, damit die großen Dateien nicht im flüchtigen Container landen.
Backtest will ein Fenster öffnen. Ohne matplotlib.use("Agg") vor dem ersten Plot-Import bricht der headless Lauf ab. Im Skript steht die Zeile bewusst ganz oben.
yfinance-Download hakt. Die Daten kommen von Yahoo. Sie sind gelegentlich zickig wegen Rate-Limits. Einzelne Titel können wegbrechen, das ist normal. Läuft der Download durch, liegt die sp500.csv lokal. Beim nächsten Mal wird sie wiederverwendet.
–check zeigt nur eine GPU. Dann ist der Container ohne --gpus all gestartet. Oder eine Karte ist anderweitig belegt. Für den Lauf selbst reicht eine Karte. So siehst Du es aber sofort.
Nach einem Reboot ist der Container weg. Das ist durch --rm so gewollt. Dein Projektordner samt .venv bleibt aber erhalten, weil er auf dem Host liegt. Du startest den Container neu, installierst einmal uv nach und setzt uv sync ab. Das geht dann schnell, weil die Pakete schon da sind.
Fazit
Der Notebook-freie Weg funktioniert sauber. Ein run_cvar.py, ein kurzer --check, ein uv run. Fertige Artefakte liegen in results/. Auf den A6000 läuft cuFOLIO ohne Klimmzüge. Der cuOpt-Solver löst das 386-Titel-Problem in unter einer Sekunde. Für dieses Problemformat ist selbst eine Karte mehr als genug. Und genau das war das Ziel: Es soll erst einmal überhaupt sauber durchlaufen.
Die Erwartung „das braucht einen H100″ hat sich für den reinen Durchlauf nicht bestätigt. Auch Ampere reicht. Die großen Schlagzeilen-Speedups gelten weiterhin für den H100. Für die Frage, ob es läuft und brauchbare Ergebnisse liefert, spielt das hier keine Rolle. Der Backtest zeigt sogar ein deutlich besseres Risikoprofil als die Equal-Weight-Basis.
Ehrlich bleibt: cuFOLIO ist Portfolio-Optimierung, keine Daytrading-Execution-Engine. Es entscheidet, wie Kapital risikooptimal über einen Korb verteilt wird. Als Wochenend-Experiment ist es die Sache aber wert. So lassen sich die eigenen Karten an etwas Trading-Relevantem ausprobieren.
Quelle: github.com/NVIDIA-AI-Blueprints/cuFOLIO (Apache-2.0)







{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…