
Meine beiden NVIDIA RTX A6000 haben inzwischen fünf Jahre auf dem Buckel. Sie stammen aus der Ampere-Generation und unterstützen die neueren FP8-Formate moderner LLMs nicht mehr direkt in Hardware. Trotzdem leisten sie in meinem Homelab täglich treue Dienste als souveräner KI-Server. Als Dr. Tristan Behrens auf LinkedIn von MIFCOM eine Workstation mit einer brandaktuellen AMD-GPU zum Testen bekam, war meine Neugier sofort geweckt. Wie schlägt sich meine betagte RTX A6000 gegen die AMD Radeon AI PRO R9700? Also gegen das Neueste, was AMD aktuell im KI-Segment zu bieten hat.
Die Karte im Mittelpunkt ist die AMD Radeon AI PRO R9700 mit 32 GB VRAM auf RDNA4-Basis. Tristan hat sie mit Qwen3.6-35B-A3B getestet und kam auf beachtliche 134 Token pro Sekunde. Genau diese Zahl wollte ich auf meiner eigenen Hardware nachstellen: mit demselben Modell, derselben Q4-Quantisierung und so weit wie möglich denselben Bedingungen. Denn ein Benchmark ist für mich nur dann etwas wert, wenn er sauber nachvollziehbar ist.
Hier der Post von Tristan auf LinkedIn, auf den ich mich beziehe: Dr. Tristan Test – AMD Radeon AI PRO R9700. Und hier der Link zu MIFCOM, die die Workstation bereitgestellt haben: https://www.mifcom.eu/.
Wie immer geht es erst einmal darum, auf einem Ubuntu-System die Software so zu installieren, dass alles funktioniert und vor allem nachvollzogen werden kann. Los geht’s …
Schritt 1 – Voraussetzungen prüfen
Befehl: nvidia-smi
Befehl: nvcc --version
Befehl: cmake --version
Befehl: gcc --version
Wenn nvcc fehlt, ziehst Du das Toolkit nach. Das passiert häufig, weil vLLM und Ollama den Compiler nicht brauchen. Achte darauf, dass die Version kleiner oder gleich der von nvidia-smi angezeigten ist:
Befehl: sudo apt update
Befehl: sudo apt install -y build-essential cmake git libcurl4-openssl-dev ccache
CUDA-Toolkit, falls nvcc fehlt (Ubuntu 24.04, passe die Version ggf. an):
Befehl: sudo apt install -y nvidia-cuda-toolkit
Mit dem folgenden Befehl prüfst Du, ob nvcc vorhanden ist und unter welchem Pfad es liegt:
Befehl: ls -l /usr/local/cuda/bin/nvcc
Als Ausgabe solltest Du etwas angezeigt bekommen wie folgt.
ingmar@A6000:~/llama.cpp$ ls -l /usr/local/cuda/bin/nvcc
-rwxr-xr-x 1 root root 23099816 Oct 30 2024 /usr/local/cuda/bin/nvcc
ingmar@A6000:~/llama.cpp$
PATH setzen und nvcc verifizieren:
Befehl: export PATH=/usr/local/cuda/bin:$PATH
Befehl: export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
Wenn Du möchtest, kannst Du mit den beiden folgenden Befehlen den PATH dauerhaft setzen. Dann musst Du das nicht in jeder neuen Shell wiederholen:
Befehl: echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
Befehl: echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
Jetzt prüfen wir, ob die Version von nvcc auch wirklich angezeigt wird.
Befehl: nvcc --version
Jetzt sollte folgendes im Terminal Fenster zu sehen sein.
ingmar@A6000:~/llama.cpp$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Tue_Oct_29_23:50:19_PDT_2024
Cuda compilation tools, release 12.6, V12.6.85
Build cuda_12.6.r12.6/compiler.35059454_0
ingmar@A6000:~/llama.cpp$
Ich habe wie folgt llama.cpp auf meinem NVIDIA dual RTX A6000 GPU Inferenz-Server eingerichtet.
Befehl: git clone https://github.com/ggml-org/llama.cpp
Befehl: cd llama.cpp
Befehl: cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=86 -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc -DLLAMA_CURL=ON
Befehl: cmake --build build --config Release -j
Wenn der Build ohne Fehler durchgelaufen ist, was er jetzt wirklich sollte, kannst Du diesen mit den folgenden Befehlen verifizieren.
Befehl: ./build/bin/llama-cli --version
Befehl: ls ./build/bin/ | grep -E 'llama-(server|bench|cli)'
Ein schneller test ob auch die GPU erkannt wird.
Befehl: CUDA_VISIBLE_DEVICES=0 ./build/bin/llama-cli --list-devices
Als Ergebnis kam bei mir im Terminal-Fenster folgendes:
Available devices:
CUDA0: NVIDIA RTX A6000 (48537 MiB, 42911 MiB free)
Modell laden & Server starten
Das GGUF (~20 GB) wird beim ersten Start automatisch nach ~/.cache/llama.cpp/ gezogen:
Befehl: CUDA_VISIBLE_DEVICES=0 ./build/bin/llama-server \
--hf-repo unsloth/Qwen3.6-35B-A3B-GGUF \
--hf-file Qwen3.6-35B-A3B-UD-Q4_K_XL.gguf \
-ngl 99 -c 262144 -np 1 -fa on \
--cache-type-k q8_0 --cache-type-v q8_0 \
--jinja \
--host 0.0.0.0 --port 11447 -a qwen3.6-35b
Smoke-Test
Jetzt möchte ich gerne wissen, ob mein Setup auch wirklich funktioniert.
Befehl: curl http://localhost:11447/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"qwen3.6-35b","messages":[{"role":"user","content":"Sag in einem Satz hallo."}]}'
Bei mir kam direkt eine Antwort zurück. Sie hat mir auch einen Wert für die Decode-Rate im timings-Block geliefert.
predicted_per_second: 127.73
Speed-Test mit llama-benchy
Jetzt die eigentlich spannende Frage: Wie schnell ist die Q4-Variante von Qwen3.6-35B-A3B auf einer einzelnen RTX A6000? Zum Messen nehme ich mein bewährtes Werkzeug llama-benchy. Der Charme liegt darin, dass ich so messe, wie es als Nutzer über die API ankommt. Und ich kann das Ergebnis direkt gegen meinen früheren BF16-Lauf über Ollama stellen.
Da llama-benchy per uvx startet, muss ich nichts dauerhaft installieren. Der Lauf geht gegen den llama.cpp-Endpoint auf Port 11447:
Befehl: uvx llama-benchy --base-url http://192.168.2.57:11447/v1 --model qwen3.6-35b --tokenizer Qwen/Qwen3.6-35B-A3B --depth 0 4096 8192 --latency-mode generation
Der Stolperstein bleibt der Tokenizer: Mein llama.cpp-Server meldet sich über den Alias qwen3.6-35b (gesetzt per -a). Das ist kein gültiger HuggingFace-Tokenizer-Name. Deshalb setze ich --tokenizer wieder explizit auf das kanonische Basis-Repo Qwen/Qwen3.6-35B-A3B. Die Quantisierung (hier Q4_K_XL) ändert nichts am Tokenizer. Ich verweise also wie immer auf das offizielle Hersteller-Repo.
Mein Ergebnis auf einer NVIDIA RTX A6000 (Q4_K_XL)
Das Modell läuft hier als UD-Q4_K_XL-GGUF auf einer A6000, gepinnt per CUDA_VISIBLE_DEVICES=0, mit q8_0-KV-Cache und Flash-Attention.
| test | t/s | peak t/s | ttfr (ms) | est_ppt (ms) | e2e_ttft (ms) |
|---|---|---|---|---|---|
| pp2048 | 2977.44 ± 22.72 | — | 815.15 ± 5.24 | 688.22 ± 5.24 | 815.15 ± 5.24 |
| tg32 | 124.29 ± 1.01 | 128.30 ± 1.04 | — | — | — |
| pp2048 @ d4096 | 2975.04 ± 10.89 | — | 2192.36 ± 7.42 | 2065.43 ± 7.42 | 2192.36 ± 7.42 |
| tg32 @ d4096 | 119.73 ± 0.43 | 123.59 ± 0.45 | — | — | — |
| pp2048 @ d8192 | 2956.89 ± 5.87 | — | 3590.38 ± 6.87 | 3463.45 ± 6.87 | 3590.38 ± 6.87 |
| tg32 @ d8192 | 115.76 ± 0.39 | 119.50 ± 0.40 | — | — | — |
llama-benchy 0.3.8 · 2026-06-27 · latency mode: generation · Modell: Qwen3.6-35B-A3B UD-Q4_K_XL · 1× RTX A6000
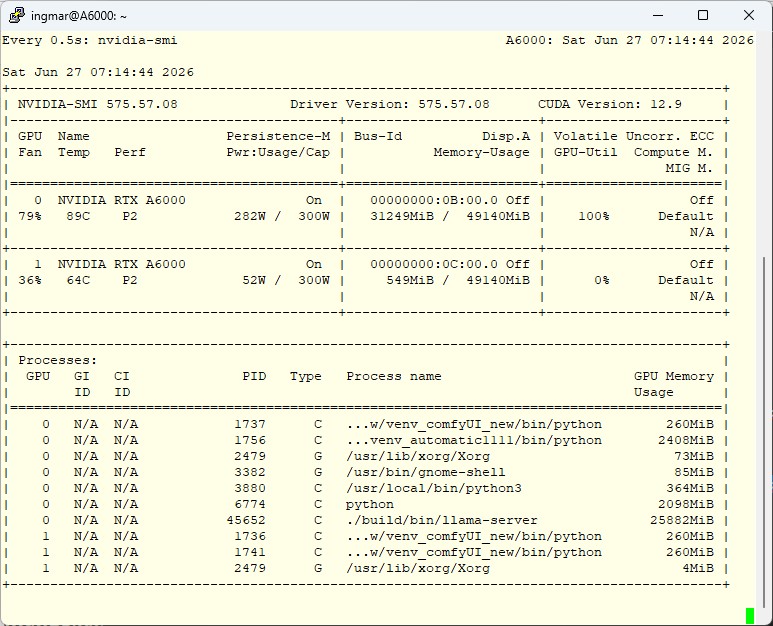
llama benchy Testlauf
Dann habe ich noch den folgenden Test laufen lassen, um etwas mehr Tiefe in den Ergebnissen zu erzielen.
Befehl: uvx llama-benchy --base-url http://192.168.2.57:11447/v1 --model qwen3.6-35b --tokenizer Qwen/Qwen3.6-35B-A3B --depth 0 32768 131072 260000 262144 --latency-mode generation
Mein Ergebnis bei großer Kontext-Tiefe (Q4_K_XL)
Dieser zweite Lauf treibt die Kontext-Tiefe bewusst nach oben. Von leerem Kontext über 32k und 131k geht es bis an die 260k-Marke. So sehe ich, wie sich Decode- und Prefill-Rate verhalten, wenn der KV-Cache richtig voll läuft.
| test | t/s | peak t/s | ttfr (ms) | est_ppt (ms) | e2e_ttft (ms) |
|---|---|---|---|---|---|
| pp2048 | 2955.29 ± 7.68 | — | 819.09 ± 1.80 | 693.34 ± 1.80 | 819.09 ± 1.80 |
| tg32 | 123.24 ± 0.38 | 127.22 ± 0.39 | — | — | — |
| pp2048 @ d32768 | 2671.87 ± 27.59 | — | 13158.08 ± 135.15 | 13032.33 ± 135.15 | 13158.08 ± 135.15 |
| tg32 @ d32768 | 97.50 ± 1.61 | 100.65 ± 1.66 | — | — | — |
| pp2048 @ d131072 | 1967.89 ± 7.91 | — | 67773.04 ± 272.37 | 67647.29 ± 272.37 | 67773.04 ± 272.37 |
| tg32 @ d131072 | 58.41 ± 0.33 | 60.30 ± 0.34 | — | — | — |
| pp2048 @ d260000 | 1462.60 ± 2.31 | — | 179291.95 ± 282.46 | 179166.19 ± 282.46 | 179291.95 ± 282.46 |
| tg32 @ d260000 | 39.16 ± 0.14 | 40.43 ± 0.14 | — | — | — |
llama-benchy 0.3.8 · 2026-06-27 · latency mode: generation · Modell: Qwen3.6-35B-A3B UD-Q4_K_XL · 1× RTX A6000
Zwei Dinge fallen hier deutlich ins Auge. Erstens sinkt die Decode-Rate erwartungsgemäß mit wachsender Kontext-Tiefe. Sie fällt von 123 t/s bei leerem Kontext über 97 t/s bei 32k und 58 t/s bei 131k bis auf 39 t/s bei 260k. Das ist kein Problem der Leistungsfähigkeit der Karte. Es ist die normale Folge des immer größeren KV-Caches, durch den bei jedem neuen Token mehr Daten gelesen werden müssen. Auch das Prefill gibt nach, von rund 2.955 t/s auf etwa 1.463 t/s. Die Wartezeit bis zum ersten Token wächst entsprechend. Bei 260k Kontext sind das knapp 180 Sekunden, also fast drei Minuten allein für die Prompt-Verarbeitung.
Zweitens habe ich bewusst auch die Stufe 262144 mitlaufen lassen. Und genau dort bin ich an die harte Grenze gestoßen. llama-benchy addiert zur eingestellten Tiefe noch die Test-Tokens hinzu. So hat die Anfrage mit rund 264.195 Tokens das mit -c 262144 konfigurierte Kontextfenster überschritten. Der Server quittierte das sauber mit einem HTTP 400 und dem Hinweis exceed_context_size_error. Deshalb fehlt diese Zeile in der Tabelle. Wer wirklich bis an die volle 262k-Marke messen will, muss den Server mit einem etwas größeren Kontext starten oder die Tiefe leicht unter das Maximum legen. Das ist ein gutes Beispiel dafür, dass die nominelle Kontextlänge und die tatsächlich nutzbare Prompt-Größe nicht dasselbe sind.
Vergleich – dasselbe Setup auf einer RTX 6000 Ada
Nach dem Q4-Lauf auf der A6000 ließ mir eine Frage keine Ruhe. Wie schnell ist genau dasselbe Setup auf einer moderneren Karte? Deshalb habe ich den kompletten Aufbau noch einmal wiederholt, diesmal auf einer einzelnen NVIDIA RTX 6000 Ada. Es ist bewusst derselbe Text, dasselbe Modell, dieselbe UD-Q4_K_XL-Quantisierung, derselbe q8_0-KV-Cache, dieselbe Flash-Attention und derselbe llama-benchy-Befehl wie oben. Geändert hat sich einzig die GPU. Die RTX 6000 Ada gehört zur Ada-Lovelace-Generation mit Compute Capability 8.9, die A6000 zur älteren Ampere-Generation mit 8.6.
Hier die Ergebnisse der RTX 6000 Ada bei wachsender Kontext-Tiefe:
| test | t/s | peak t/s | ttfr (ms) | est_ppt (ms) | e2e_ttft (ms) |
|---|---|---|---|---|---|
| pp2048 | 5230.45 ± 133.59 | — | 496.21 ± 9.84 | 392.00 ± 9.84 | 496.21 ± 9.84 |
| tg32 | 154.43 ± 5.94 | 159.41 ± 6.13 | — | — | — |
| pp2048 @ d32768 | 4454.93 ± 122.48 | — | 7925.43 ± 211.67 | 7821.21 ± 211.67 | 7925.43 ± 211.67 |
| tg32 @ d32768 | 134.65 ± 1.92 | 139.00 ± 1.98 | — | — | — |
| pp2048 @ d131072 | 2515.84 ± 22.46 | — | 53021.59 ± 469.57 | 52917.37 ± 469.57 | 53021.59 ± 469.57 |
| tg32 @ d131072 | 79.10 ± 0.62 | 81.65 ± 0.64 | — | — | — |
| pp2048 @ d260000 | 1652.25 ± 6.75 | — | 158707.63 ± 649.29 | 158603.42 ± 649.29 | 158707.63 ± 649.29 |
| tg32 @ d260000 | 50.84 ± 0.50 | 52.48 ± 0.52 | — | — | — |
llama-benchy 0.3.8 · 2026-06-28 · latency mode: generation · Modell: Qwen3.6-35B-A3B UD-Q4_K_XL · 1× RTX 6000 Ada
Auch hier bin ich bei 262144 wieder an die harte Grenze gestoßen, mit demselben HTTP 400 und exceed_context_size_error wie auf der A6000. Das Verhalten ist also identisch und nicht von der Karte abhängig.
Der direkte Vergleich beider Karten auf identischem Setup sieht so aus:
| Kontext-Tiefe | Decode A6000 (t/s) | Decode RTX 6000 Ada (t/s) | Vorsprung Ada | Prefill A6000 (t/s) | Prefill RTX 6000 Ada (t/s) |
|---|---|---|---|---|---|
| 0 | 123.24 | 154.43 | +25 % | 2955.29 | 5230.45 |
| 32k | 97.50 | 134.65 | +38 % | 2671.87 | 4454.93 |
| 131k | 58.41 | 79.10 | +35 % | 1967.89 | 2515.84 |
| 260k | 39.16 | 50.84 | +30 % | 1462.60 | 1652.25 |
Beide Karten: Qwen3.6-35B-A3B UD-Q4_K_XL, q8_0-KV-Cache, Flash-Attention, je 1 GPU.
Das Bild ist eindeutig. Die RTX 6000 Ada liegt im Decode über alle Kontext-Tiefen vorn, mit einem Vorsprung von rund 25 bis 38 Prozent. Bei leerem Kontext erreicht sie 154 t/s. Damit zieht sie sogar an der AMD Radeon AI PRO R9700 mit ihren 134 t/s vorbei. Wo die A6000 noch knapp unter der AMD-Karte lag, setzt sich die Ada klar davor.
Beim Prefill ist der Abstand bei kleinem Kontext am größten. Bei leerem Kontext verarbeitet die Ada den Prompt mit rund 5.230 t/s und damit fast doppelt so schnell wie die A6000. Bei sehr großer Tiefe schrumpft dieser Vorsprung. Das passt zur Theorie. Prefill ist rechenlastig, und genau dort spielt die jüngere Ada-Architektur ihre größere Rechenleistung aus. Der Decode hängt dagegen vor allem an der Speicherbandbreite. Die RTX 6000 Ada bietet rund 960 GB/s, die A6000 rund 768 GB/s. Dieses Verhältnis von etwa 1,25 deckt sich fast exakt mit dem Decode-Vorsprung von 25 Prozent bei leerem Kontext.
Mein Fazit zum Karten-Vergleich: Vier Jahre Architektur-Fortschritt zahlen sich aus. Die RTX 6000 Ada ist im Decode rund ein Drittel schneller und im Prefill bei kurzem Kontext fast doppelt so schnell. Trotzdem bleibt die alte A6000 für lokale, souveräne KI absolut brauchbar. Sie liefert solide Token-Raten und reicht für den Alltag im Homelab vollkommen aus.
Update – llama.cpp aktuell halten
llama.cpp entwickelt sich rasant weiter. Neue Modell-Architekturen, Performance-Optimierungen und Bugfixes erscheinen teils im Tagesrhythmus. Deshalb lohnt es sich, das Repository regelmäßig zu aktualisieren. Der Ablauf ist denkbar einfach: neuesten Stand ziehen und neu bauen. Dank des zuvor installierten ccache geht der erneute Build deutlich schneller, weil unveränderte Objekte aus dem Cache kommen.
Zuerst wechselst Du in das Projektverzeichnis:
Befehl: cd ~/llama.cpp
Dann holst Du den aktuellen Stand vom Upstream-Repository:
Befehl: git pull
Anschließend baust Du mit denselben Optionen wie bei der Erstinstallation neu. Wichtig ist, dass Du dieselben CMake-Flags verwendest. So bleiben CUDA-Support und die passende Compute-Capability (hier 86 für Ampere) erhalten:
Befehl: cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=86 -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc -DLLAMA_CURL=ON
Befehl: cmake --build build --config Release -j
Nach dem Build prüfst Du kurz, ob die neue Version sauber durchgelaufen ist:
Befehl: ./build/bin/llama-cli --version
Tipp: Manchmal schlägt ein Update fehl, etwa weil sich Build-Optionen oder Abhängigkeiten geändert haben. Dann hilft meist ein sauberer Neubau. Dazu löschst Du das build-Verzeichnis vorher:
Befehl: rm -rf build
Danach führst Du die beiden cmake-Befehle von oben erneut aus. Da llama.cpp sich so schnell bewegt, notiere ich mir für reproduzierbare Benchmarks immer den verwendeten Commit-Hash. Den bekommst Du mit:
Befehl: git rev-parse --short HEAD
Mein Fazit zum Q4-Lauf
Spannend ist der direkte Vergleich auf derselben Hardware. In meinem früheren Beitrag lag dasselbe Modell unquantisiert in BF16 bei rund 57 t/s im Decode (über beide A6000 als Layer-Split via Ollama). Die Q4-Variante auf einer einzelnen Karte erreicht hier 124 t/s und damit mehr als das Doppelte. Genau der Hebel, den ich damals als Vermutung formuliert hatte, ist jetzt mit einer Zahl belegt. Auf Ampere ist FP8 mangels Hardware-Unterstützung kein Thema. Deshalb ist die 4-Bit-Quantisierung hier der entscheidende Beschleuniger.
Auch das Prefill profitiert deutlich. Mit rund 2.977 t/s verarbeitet die Q4-Variante den Prompt fast doppelt so schnell wie die früheren ~1.500 t/s in BF16. Dadurch sinkt die Wartezeit bis zum ersten Token bei 8k Kontext auf etwa 3,6 Sekunden, gegenüber rund 7 Sekunden zuvor. Schön ist außerdem, dass die Decode-Rate über die Kontext-Tiefe stabil bleibt. Sie fällt von 124 t/s bei leerem Kontext auf 116 t/s bei 8k, also nur rund 7 %.
Den Anlass für diesen Test gab Tristans LinkedIn-Post zur AMD Radeon AI PRO R9700. Sie kam mit derselben GGUF-Q4-Konfiguration auf 134 t/s. Damit habe ich endlich eine belastbare Gegenzahl von NVIDIA-Seite. Meine A6000 landet mit 124 t/s (Peak 128) knapp darunter, also bei rund 93 % der Decode-Leistung der deutlich jüngeren RDNA4-Karte. Für eine Profikarte aus dem Jahr 2021 ist das ein bemerkenswert gutes Ergebnis. Es bestätigt Tristans Eindruck: Beide Karten sind solide Single-Player-Systeme für lokale, souveräne KI.






{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…