

Bei diesem Beitrag geht es darum ein neuronales Netz auf Basis von YOLOv5 zu trainieren. Dieses YOLO Netz soll PFM-1 Antipersonenminen erkennen können um hier beim automatisierten Erkennen dieser Minen zu unterstützen. Da ich selber das erste Mal mit YOLOv5 und synthetischen Daten arbeite bin ich auf die Ergebnisse gespannt die ein Validierungsdatensatz liefern wird. Mir ist zum Zeitpunkt als ich diesen Artikel verfasst habe noch nicht klar wie gut solch ein trainiertes Netz sein wird wenn es dann auf nicht synthetische Bilder der echten PFM-1 Mine trifft und diese Minen erkennen soll.
Für die synthetischen Daten habe ich drei Ansätze verfolgt.
- Im ersten Teil der Erstellung der synthetischen Daten habe ich Bilder der PFM-1 Antipersonenminen mit Blender erstellt und diese gerenderten Bilder auf verschiedenste Hintergrundbilder als Vordergrund gelegt. In Blender bzw. für die gerenderten Bilder der Antipersonenmine habe ich die Draufsicht der Mine gewählt da die Minen meistens flach auf dem Boden liegen. Auch habe ich mit verschiedenen Texturen und Farben gearbeitet um hier einmal mehr Trainingsdaten zu haben.
- Im zweiten Ansatz habe ich mit Stable-Diffusionen sogenannte Hintergrundbilder erzeugen lassen auf denen wieder Bilder der PFM-1 Mine also jene gerenderten und auch Bilder von echten Landminen gelegt wurden. Der Vorteil hier ist das die so erstellen Bilder sehr einfach zu generieren sind und der Zeitaufwand sich deutlich reduziert.
- Der Dritte Ansatz war deutlich komplexer. Hier habe ein Stable-Diffusion Netz beigebracht direkt PFM-1 Antipersonenminen zu generieren in unterschiedlichen Landschaften, Szenen etc.
Dann habe ich alle Daten in mehr als 30 Tests kombiniert, einzelnen getestet etc. um zu sehen wie gut diese Netze abhängig von den verwendeten Typ von Trainingsdaten sich eignen echt PFM-1 Minen die ausgebracht wurden in Videos und Bildern zu erkennen.
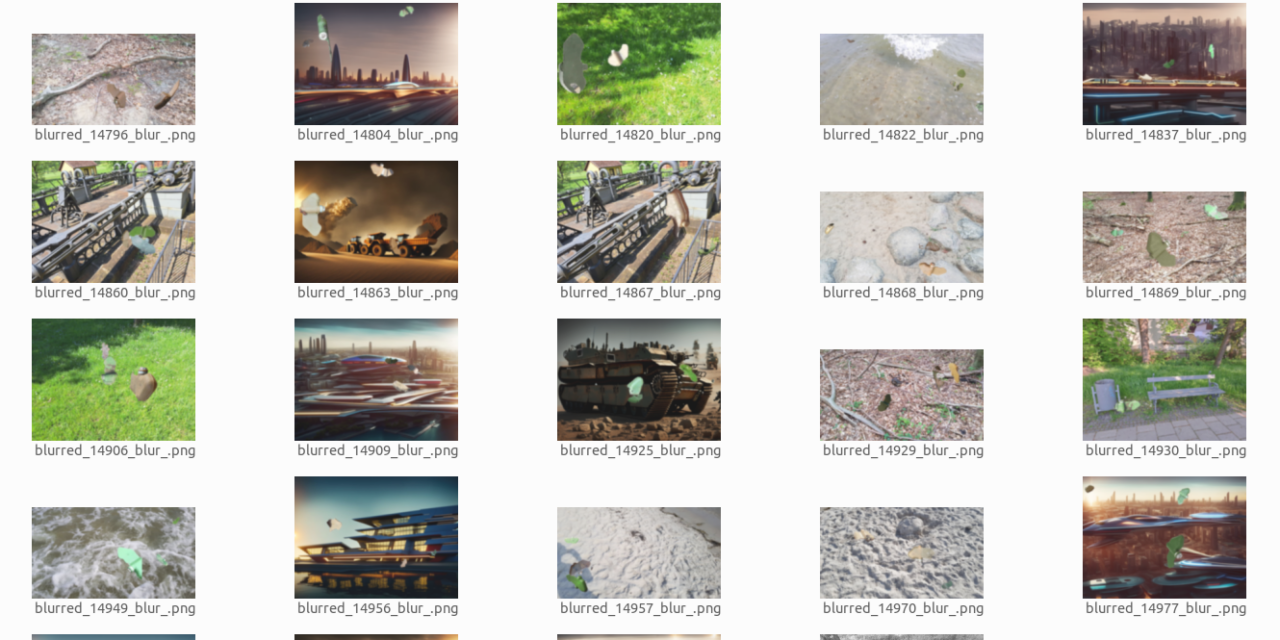
Hier ein Bilder das die erstellten synthetischen Trainingsdaten zeigt.
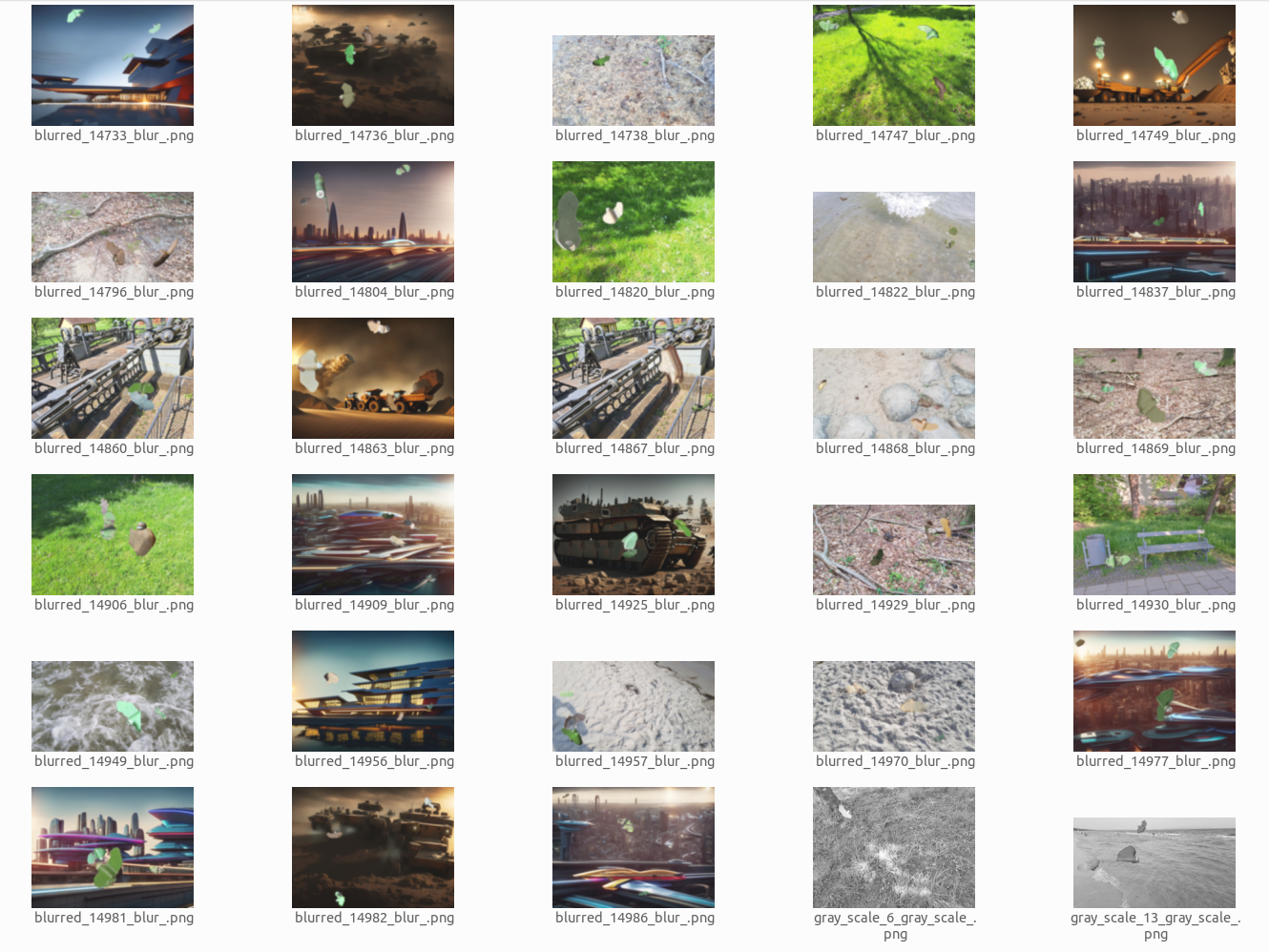
PFM-1 anti-personnel landmine training data overview
Zunächst einmal wird im folgenden Abschnitt darauf eingegangen wie Yolov5 auf einem Ubuntu 22.04 System eingerichtet wird. Da ich immer Anaconda verwende für die verschiedenen Umgebungen kommt hier auch kurz die Erläuterung wie eine entsprechende Anaconda Umgebung angelegt wird. Auch sollte wie bereits mehrfach hier auf meinem Blog beschrieben CUDA von NVIDIA für die Grafikkarte installiert werden damit die GPU auch das Training des neuronalen Netzes beschleunigt.
Anaconda Umgebung aufsetzen
Zunächst einmal die Anaconda Umgebung mit dem Namen yolov5 anlegen.
Befehl: conda create --name yolov5
Mit dem folgenden Befehl kann man sich die verschiedenen bereits angelegten Umgebungen anzeigen lassen.
Befehl: conda info --envs
Immer wenn wir mit yolo jetzt arbeiten werden muss die Umgebung yolov5 aktiviert werden.
Befehl: conda activate yolov5
Hier jetzt der Link auf das GitHub Projekt welches ich einsetzen werden.
URL: https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
YoloV5 lokal einrichten
Jetzt das yolov5 repository clonen.
Befehl: git clone https://github.com/ultralytics/yolov5
Nach dem Clonen des Repositories bitte in den Ordner yolov5 wechseln.
Befehl: cd yolov5
Jetzt alle erforderlichen Bibliotheken installieren.
Befehl: pip install -r requirements.txt
Nach dem alles soweit installiert wurde ist yolov5 einsatzbereit und es müssen die Trainingsdaten aufbereitet werden.
Trainings-Datensatz der PFM-1 Antipersonenminen erstellen
Jetzt bitte die Trainingsdaten erstellen. Ich habe wie eingangs beschrieben mir mit Blender entsprechende Bilder der PFM-1 Mine rendern lassen bzw. Bilder dieser Mine im Internet heraus gesucht. Diese Bilder der PFM-1 Minen habe ich dann automatisiert zu Trainingsdaten verarbeiten lassen und gleich die YOLO Label für die Bounding Boxen erstellen lassen. Dazu habe ich mir Python Programme geschrieben die automatisiert die transparenten Bilder als Vordergrundbilder auf verschiedenen Hintergrundbildern platziert, die Labels für die Bounding Boxen erstellen und auf die Bilder noch verschiedene Filter anwenden. So habe ich weit über 100.000 Trainingsdatensätze erstellt oder mehr als 100GB an Daten für das Training erzeugt. Wie gut die Daten wirklich sind und meine Vorgehensweise das wird sich erst noch zeigen.
Training mit Negativbildern
Um die Anzahl der Falsch-Positiven während des Erkennungsprozesses von YOLO zu reduzieren, ist es wichtig, dass Sie Ihren Trainingsdaten Bilder ohne Beschriftung hinzufügen. Sie müssen aus Ihrer Umgebung wissen, welche Objekte in Ihrem Bild zu einer falsch-positiven Erkennung führen werden. Nachdem Sie diese Bilder zu Ihrem Datensatz hinzugefügt haben, sollten diese Bilder beim Scannen des Datensatzes als „fehlend“ (wenn Sie keine Beschriftungsdatei geliefert haben) oder „leer“ (wenn Sie eine leere Beschriftungsdatei geliefert haben) angezeigt werden. Die Bilder mit einer leeren oder fehlenden Etikettendatei werden beide gleich behandelt, und beide Arten von Bildern helfen Ihnen, die Zahl der falsch-positiven Erkennungen zu verringern. In meinem Fall werden viele Blätter als PFM-1-Minen erkannt, und das sind falsch positive Erkennungen, die ich nicht haben möchte.

PFM-1 anti-personnel landmine false positive
Trainingsdaten mit Yolo Labeln
Zur Überprüfung ob meine mit meinen Python Programmen erstellen Trainingsdaten auch wirklich die passenden Label haben habe ich labelImg installiert und die Trainingsdaten in Stichproben überprüft.
Trainingsdatensatz vorbereiten für YoloV5
Hier einmal der Aufbau einen Trainingsdatensatzes der exakt den Vorgaben von YOLO folgt mit der Aufteilung zwischen Bild und Label und den verschiedenen Unterordnern für das Training, Testen und Validieren während dem Training.
- dataset_pfm-1
- images
- test
- train
- val
- labels
- test
- train
- val
- images
Daten aufteilen
Die Aufteilung habe ich wieder ein Python Programm machen lassen das den Trainingsdaten Satz wie folgt in seiner Verteilung erstellt.
- train: 70%
- test: 20%
- val: 10%
Beispiel Berechnung:
- 2.300 Datensätze und ein Datensatz besteht aus Bild und Label also 4.600 Dateien.
- 2.300 / 100 = 23
- Anzahl Trainingdaten: 70* 23 = 1.610
- Anzahl Testdaten: 20 * 23 = 460
- Anzahl Validierungsdaten: 10 * 23 = 230
Training Konfigurieren
Damit das Training angestoßen werden kann bedarf es noch einer Konfigurationsdatei die beschreibt wo exakt die Daten für das Training liegen. Diese bei mir genannte pfm-1.yaml Datei sieht wie folgt aus.
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /media/ingmar/data/Pictures/02_PFM-1-Pictures/02_training_data/20230514_new_training_data # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: images/test # test images (optional)
# Classes
names:
0: PFM-1
Hier eine Übersicht welche vortrainierten Yolo Modelle es gibt. Für meine Tests und Versuche habe ich das Model YOLOv5m verwendet.
| Model | size (pixels) |
mAPval 50-95 |
mAPval 50 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
Kommentar |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 | |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 | okay |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 | |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 | |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 | |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 | |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 | |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 | |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 | |
| YOLOv5x6 + TTA |
1280 1536 |
55.0 55.8 |
72.7 72.7 |
3136 – |
26.2 – |
19.4 – |
140.7 – |
209.8 – |
Quelle: https://github.com/ultralytics/yolov5#pretrained-checkpoints
Training starten
Sind die Trainingsdaten vorbereitet und die Konfigurationsdatei erstellt dann kann das Training gestartet werden. Der Befehl sieht wie folgt aus.
Befehl: python3 train.py --img 640 --batch 32 --epochs 30 --data /media/ingmar/data/data_backup/yolo/pfm-1-single-dataset-yolo/pfm-1.yaml --weights yolov5s.pt
Hier ein Screenshot vom aktuellen Training exp031 das bei mir über 7 Tagen benötigt und 75.000 Datensätze verwendet.
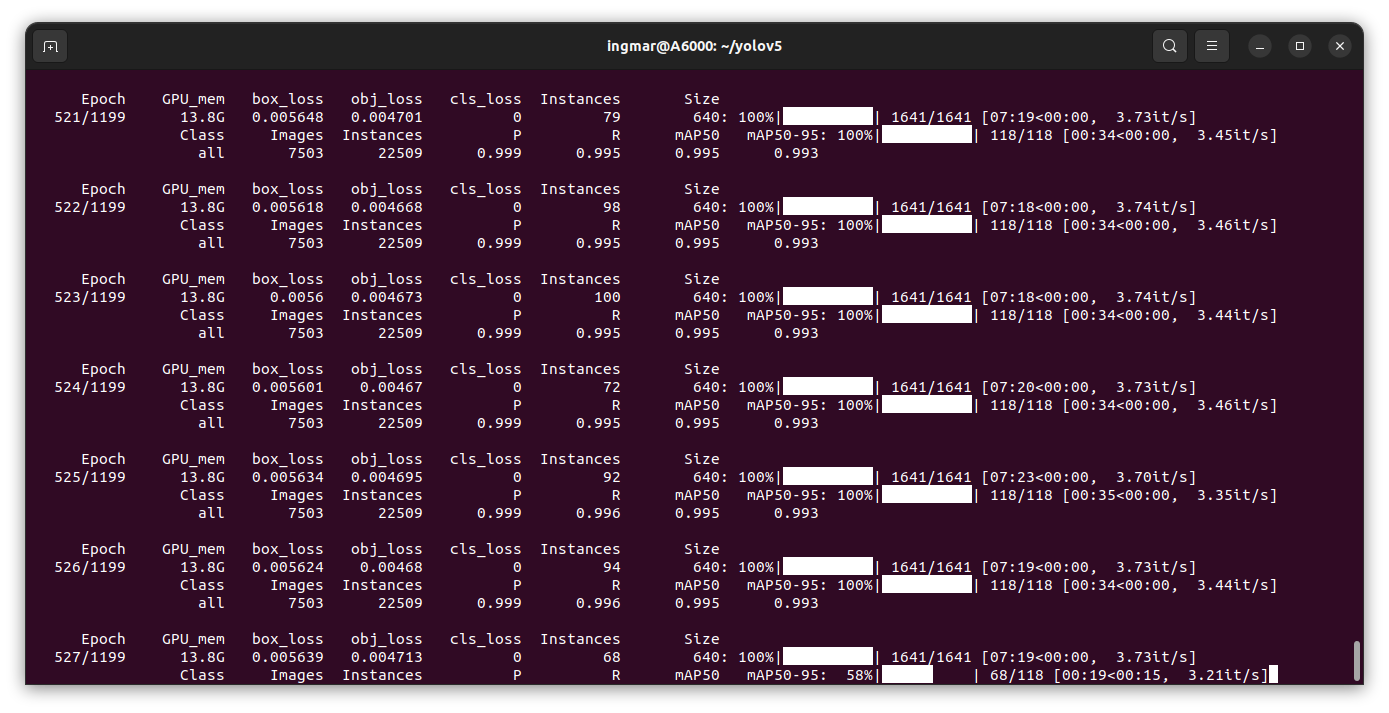
PFM-1 anti-personnel landmine active YOLOv5m training
Neuronales Netz testen
Jetzt ist es natürlich spannend wie gut funktioniert das eigene neuronale Netz bzw. das YOLOv5m Netz. Dazu habe ich ein paar Testbilder die ich dem neuronalen Netz gebe und die Bounding Boxen einzeichnen lasse.
Befehl: python3 detect.py --source /media/ingmar/data/data_backup/pfm-1-internet --weights runs/train/exp5/weights/best.pt --conf 0.6 --iou 0.45 --augment --project run_pfm_1 --name detect_pfm_1_test
Natürlich das solch ein Test sehr subjektiv und sagt nicht so richtig etwas aus. Daher gibt es für YOLOv5 auch ein Python Programm das einem professionell bei der Evaluierung hilft. Der Befehl sieht wie folgt aus um die Evaluierung zu starten. Wichtig hierbei ist nur das der Datensatz der für die Evaluierung verwendet wird wirklich kein Bestandteil der Trainingsdaten war.
Befehl: python3 val.py –batch 64 –data /media/ingmar/data/Pictures/02_PFM-1-Pictures/04_validation_data/data.yaml –weights runs/train/exp31/weights/best.pt –task train –project runs_pfm_1_test –name Validation –augment
Jetzt erhält man eine Detaillierte Auswertung wie gut das eigene trainierte YOLO Netz das Objekt für das es trainiert wurde erkennt.
Das folgende Video zeigt einen Zwischenstand meiner Arbeit. Für die Aufnahme habe ich mir eine PFM-1 Antipersonen Minen ausgedruckt und grün gefärbt.

PFM-1 anti personnel landmine video exp031
Zusammenfassung
Ich bin soweit zufrieden wie gut das Training mit Synthetischen Daten klappt. Wie das kleine Video zeigt hat der Trainingsdatensatz noch Potential verbessert zu werden. Im Austausch mit anderen Gruppen die sich ebenfalls mit diesem Thema beschäftigen denke ich das es möglich sein wird einen guten Detektor für diesen Typ von Minen zu bauen auch wenn gleich die Umwelt auf die Erkennung einen sehr großen Einfluss hat. Aber es ist ein hervorragenden Beispiel hier das Thema künstliche Intelligenz für etwas für die Menschen sehr positives einzusetzen.







{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…