

In meinem letzten Beitrag habe ich NVIDIA Nemotron ASR Streaming direkt mit NeMo lokal betrieben. Das war der „nackte“ Weg über das Framework. In diesem Beitrag gehe ich einen Schritt weiter und steige in NVIDIA NIM ein. NIM steht für NVIDIA Inference Microservices also die Microservice-Variante, mit der NVIDIA seine Modelle als fertige, optimierte Container ausliefert. Das Ziel: einen deutschen Spracherkennungs-Dienst als lokalen Microservice betreiben, der sich später sauber in einen vollständigen Sprach-Agenten einklinken lässt. Das Ziel ist es natürlich wie immer das alles auf eigener Hardware, ohne Cloud lokal läuft.
Was ist NVIDIA NIM?
NIM (NVIDIA Inference Microservices) verpackt ein Modell samt optimierter Inferenz-Engine in einen einzelnen Docker-Container. Statt dir wie in Teil 1 selbst eine Umgebung mit PyTorch, NeMo und den passenden Abhängigkeiten zu bauen, ziehst du einen fertigen Container aus der NVIDIA-Registry (`nvcr.io`) und startest ihn. Der Container bringt eine standardisierte API mit (HTTP und gRPC), sodass du den Dienst genauso ansprechen kannst wie eine Cloud-API nur eben lokal.
Für mich ist das aus zwei Gründen spannend:
- Erstens ist die Inbetriebnahme deutlich schneller und reproduzierbarer als ein händischer Framework-Aufbau.
- Zweitens ist NIM der Baustein, den NVIDIA auch in seiner eigenen Voice-Agent-Architektur als Deployment-Schicht nutzt
Wer also später einen kompletten Sprach-Agenten bauen will, kommt an NIM kaum vorbei.
Das Zielbild dieses Beitrags
Wir betreiben ein ASR-NIM für Deutsch auf Basis des streamingfähigen, mehrsprachigen Parakeet-Modells. Anders als bei einem reinen Datei-Upload geht es diesmal um echtes Live-Streaming: Am Ende sprichst du ins Mikrofon und siehst dein Transkript live im Browser entstehen und ich betone es noch einmal alles komplett lokal das ist mein Ziel.
Damit knüpfen wir direkt an Teil 1 an, und genau hier liegt der spannende Unterschied:
- In Teil 1 lief das Modell in deinem Python-Prozess (NeMo, cache-aware). Die kleine Gradio-Web-App hat das Modell selbst geladen.
- In diesem Teil sitzt das Modell hinter einem Microservice. Unsere Web-App wird zum dünnen Streaming-Client, der das Mikrofon-Audio chunk-weise an den lokalen NIM-Endpunkt schickt.
Gleiche UX im Browser, komplett anderer Unterbau und genau das macht den Microservice-Gedanken greifbar. Die App dazu (nim_asr_gradio_app.py) bauen wir am Ende des Beitrags an den Dienst an.
Bleibt das wirklich lokal? Riva ≠ Cloud
Eine Frage, die hier sofort aufkommt: Wir sprechen gleich den Riva-Client an und einen wichtigen Punkt für mich. Verlassen meine Sprachdaten durch die Nutzung von Riva nicht mein Netzwerk? Nein. „Riva“ ist kein Cloud-Dienst, sondern NVIDIAs Speech-Framework, also die API-Schicht. Es gibt einen Riva-Client und einen Riva-Server. Wohin die Daten gehen, hängt einzig davon ab, auf welchen Server der Client zeigt:
--server 0.0.0.0:50051→ dein lokaler NIM-Container auf der eigenen GPU. Das Audio läuft über localhost, es verlässt die Maschine nicht.- Zeigst du den Client stattdessen auf einen NVIDIA-gehosteten Endpunkt, dann ginge das Audio in die Cloud. Das machen wir hier bewusst nicht.
Sobald der Container läuft, könntest du die Maschine sogar vom Internet trennen (Air-Gapped) und die Transkription liefe weiter. Nach draußen geht nur einmalig der Modell-Download aus nvcr.io beim ersten Start und der Lizenz-Check über den API-Key. Niemals dein Sprachmaterial.
Hinweis: Parakeet eignet sich als Einstieg besonders gut, weil es Streaming unterstützt und damit näher am späteren Agenten liegt. Wer maximale Genauigkeit oder zusätzlich Übersetzung braucht, kann alternativ das Canary-NIM nehmen. Die Schritte sind nahezu identisch, es ändern sich nur Container-ID und Profil. Genau das ist Thema von Teil 3.
Voraussetzungen
- Betriebssystem: Linux (ich nutze Ubuntu Server)
- GPU: NVIDIA-GPU mit Compute Capability ≥ 8.0 und mindestens 16 GB VRAM. Meine RTX A6000 Ada (48 GB) erfüllt das mehr als deutlich.
- Docker und das NVIDIA Container Toolkit (das hast du bereits, wenn du Container schon mit GPU-Zugriff betreibst)
- Ein aktueller NVIDIA-Treiber
- Ein kostenloser NGC-Account und ein NGC-API-Key zum Ziehen der NIM-Container
- Eine Python-venv für den Client und die Web-App (wie in Teil 1)
Schritt 1: NGC-Account und API-Key anlegen
Die NIM-Container liegen in der NVIDIA-Registry und sind zugriffsbeschränkt. Du brauchst daher einen kostenlosen NGC-Account und einen persönlichen API-Key.
Jetzt muss Du erst einmal die Registrierung auf ngc.nvidia.com durchführen umd anschließend einen API-Key erzeugen zu können.
URL: ngc.nvidia.com
Nach der erfolgreichen Registrierung musst Du jetzt die folgende Seite öffnen.
URL: org.ngc.nvidia.com
Jetzt solltest Du folgendes Dashboard sehen.
NVIDIA ngc Dashboard Organisations-Verwaltung
Jetzt bitte die folgende URL öffnen um die persönlichen Keys anlegen zu können die wir benötigen.
URL: org.ngc.nvidia.com/setup/personal-keys
Auf der Setup-Seite siehst du dann den Button für den Personal Key. Für unseren lokalen NIM-Betrieb nimmst genau diesen also klickst auf den Button „Generate Personal Key“. Im Dialog dann:
- Name vergeben, Expiration großzügig wählen
- bei Services Included unbedingt NGC Catalog anhaken (sonst klappt später der Container-Pull nicht)
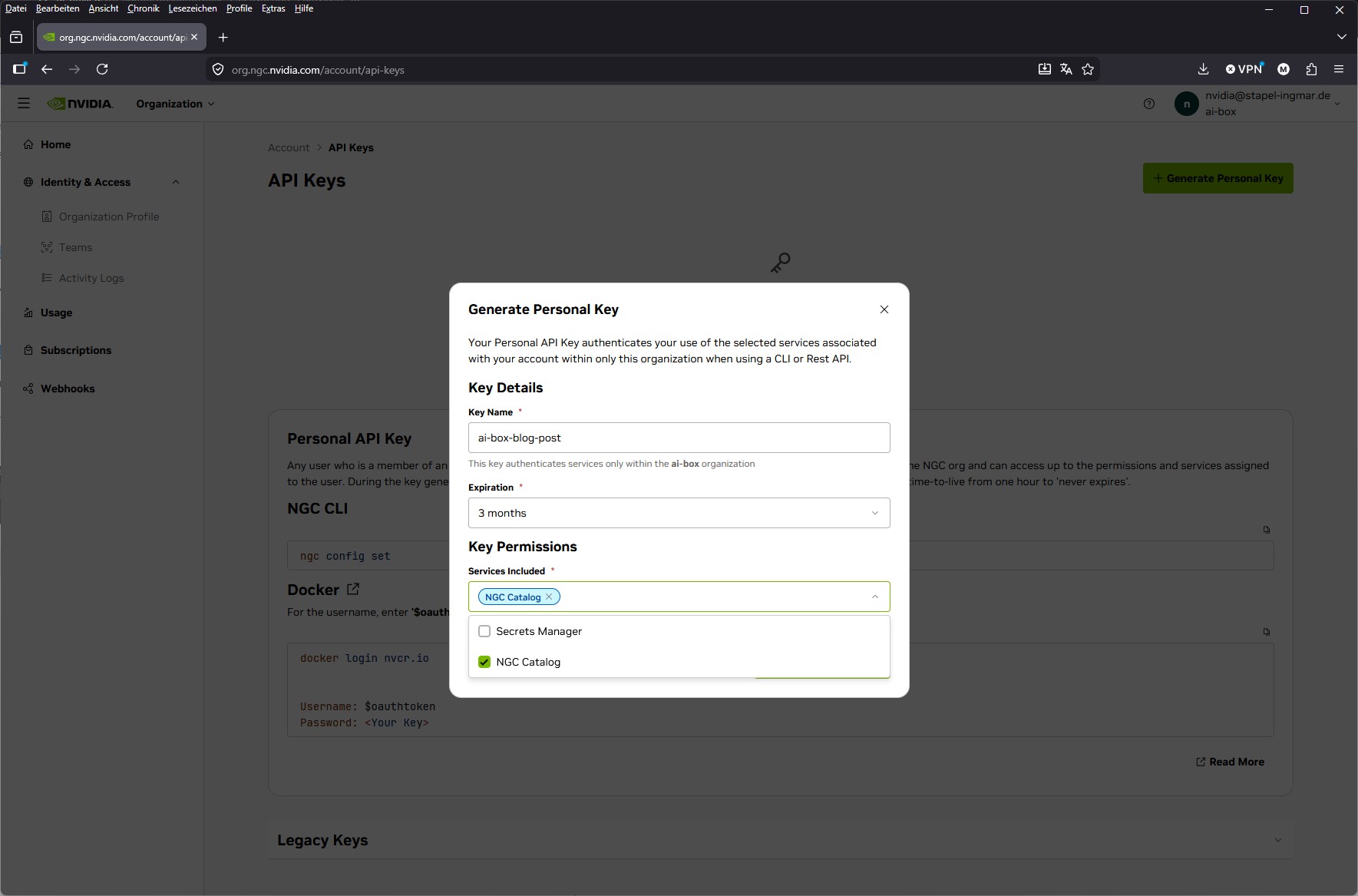
NVIDIA ngc dashboard personal key config
Den Eintrag Secrets Manager brauchst du für unseren Zweck nicht daher habe ich diesen auch nicht ausgewählt.
Jetzt geht es weiter und ja lege den Key sicher ab.
Schritt 2: Docker an der NVIDIA-Registry anmelden
Mit dem API-Key meldest du Docker an der Registry nvcr.io an. Als Benutzername wird der feste Wert $oauthtoken verwendet, als Passwort dein API-Key.
Befehl: docker login nvcr.io
Bei der Abfrage gibst du als Username $oauthtoken ein und als Passwort deinen NGC-API-Key.
Bei mir kam dann folgendes im Terminal Fenster.
ingmar@A6000Ada:~$ docker login nvcr.io
Username: $oauthtoken
Password:WARNING! Your credentials are stored unencrypted in ‚/home/ingmar/.docker/config.json‘.
Configure a credential helper to remove this warning. See
https://docs.docker.com/go/credential-store/Login Succeeded
ingmar@A6000Ada:~$
Hinweis:
Du brauchst den gespeicherten Login eigentlich nur zum Ziehen des Container-Images. Sobald das Image einmal lokal liegt (nach dem ersten docker run), kannst du mit dem folgenden Befehl wieder löschen.
Befehl: docker logout nvcr.io
Die Zugangsdaten werden damit wieder aus der Datei entfernen. Das Image bleibt im lokalen Cache, und der laufende Container authentifiziert sich übers NGC_API_KEY (Umgebungsvariable), nicht über den Docker-Login. Erst wenn du das Image mal aktualisieren willst, meldest du dich kurz neu an.
Schritt 3: API-Key und Cache vorbereiten
Damit der Container den Key nutzen kann, legen wir ihn als Umgebungsvariable ab. Zusätzlich richten wir ein lokales Cache-Verzeichnis ein, damit das Modell nicht bei jedem Start neu heruntergeladen wird.
Befehl: export NGC_API_KEY="export NGC_API_KEY="nvapi-fb4jkmeJl3rFfAM75--------------------rY0trE""
Zusätzlich legen wir ein lokales Cache-Verzeichnis an. Der Hintergrund: Beim ersten Start lädt das NIM das Modell (mehrere GB) aus der NGC-Registry herunter. Da wir den Container mit --rm starten, wird er beim Beenden komplett gelöscht. Läge der Cache nur im Container, würde das Modell bei jedem Neustart erneut geladen. Deshalb mounten wir in Schritt 4 dieses Host-Verzeichnis in den Container (-v ~/.cache/nim:/opt/nim/.cache). So bleibt das Modell auf der Platte deiner Maschine, und der Dienst ist beim zweiten Start in Sekunden bereit statt nach minutenlangem Download.
Das Verzeichnis legen wir vorab selbst an, damit es deinem Benutzer gehört und nicht von Docker als root erzeugt wird:
Befehl: mkdir -p ~/.cache/nim
Schritt 4: Das deutsche ASR-NIM im Streaming-Modus starten
Jetzt starten wir den eigentlichen Microservice. Der grundsätzliche Aufbau eines NIM-Starts sieht so aus: Wir reichen die GPU durch, setzen den API-Key, öffnen den HTTP- und den gRPC-Port und wählen über NIM_TAGS_SELECTOR ein Modell-Profil.
Da unser Ziel der Live-Voice-Pfad ist, nehmen wir das Streaming-Profil mit niedriger Latenz: mode=str. Als Modell nutzen wir das mehrsprachige Parakeet, das Deutsch direkt mitbringt:
Befehl: export CONTAINER_ID=parakeet-1-1b-rnnt-multilingual
Befehl: export NIM_TAGS_SELECTOR="mode=str"
Befehl: docker run -it --rm --name=$CONTAINER_ID --runtime=nvidia --gpus '"device=0"' --shm-size=8GB -e NGC_API_KEY -e NIM_HTTP_API_PORT=9000 -e NIM_GRPC_API_PORT=50051 -p 9000:9000 -p 50051:50051 -e NIM_TAGS_SELECTOR -v ~/.cache/nim:/opt/nim/.cache nvcr.io/nim/nvidia/$CONTAINER_ID:latest
Der erste Start dauert eine Weile, da der Container das Modell herunterlädt und die Inferenz-Engine vorbereitet. Bereit ist der Dienst, sobald in den Logs eine entsprechende „running“-Zeile erscheint.
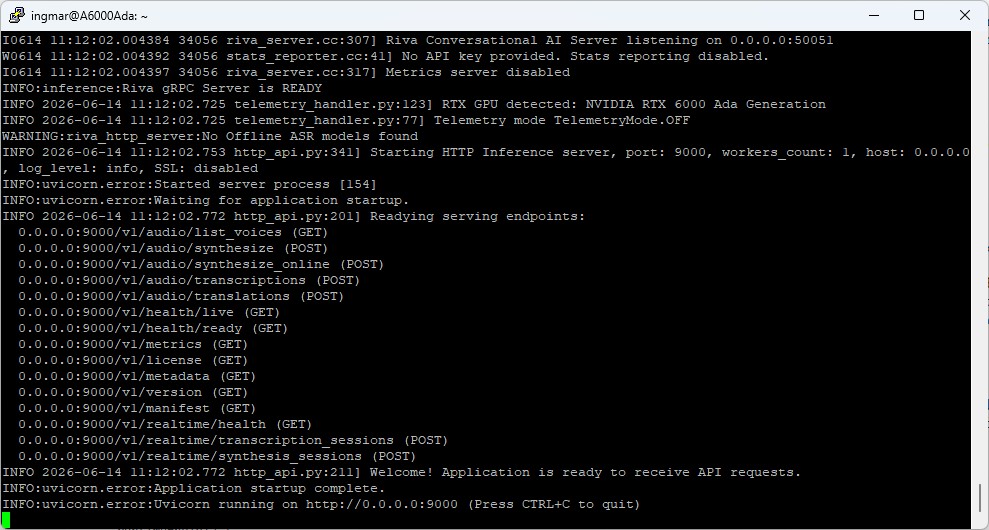
NVIDIA NIM container setup
Hinweis zu Container-ID und Profil: Beide stammen aus der aktuellen NIM-ASR-Support-Matrix. Sollte NVIDIA das Modell umbenennen oder Profile ändern, findest du die gültigen Werte dort bzw. auf der Modellseite auf build.nvidia.com. Die verfügbaren Profile (str, str-thr, ofl) schauen wir uns in Schritt 8 noch genauer an.
Schritt 5: Container-Status prüfen
In einem zweiten Terminal kannst du prüfen, ob der Dienst läuft.
Befehl: docker ps
Befehl: curl http://localhost:9000/v1/health/ready
Antwortet der Health-Check mit etwas wie nachfolgend gezeigt, dann steht dein ASR-Microservice.
ingmar@A6000Ada:~$ curl http://localhost:9000/v1/health/ready
{"object":"health.response","message":"ready","status":"ready"}ingmar@A6000Ada:~$
Schritt 6: Schneller Funktionstest auf der Kommandozeile
Bevor wir die Web-App anschließen, prüfen wir mit dem offiziellen Riva-Client kurz, ob der Dienst korrekt transkribiert. Da der Dienst lokal läuft, brauchen wir keine Cloud-Authentifizierung – wir zeigen einfach auf localhost und den gRPC-Port.
Jetzt legen wir erst einmal eine weitere virtuelle Umgebung an mit dem folgenden Befehl.
Befehl: python3 -m venv ~/venvs/riva-client
Jetzt müssen wir diese virtuelle Umgebung starten.
Befehl: source ~/venvs/riva-client/bin/activate
Wichtig ist das wir jetzt alle weiteren Befehle immer in dieser virtuellen Umgebung ausführen. Soll heißen diese muss immer aktiv sein bzw. aktiviert werden wenn z. B. der Rechner mal neugestratet wurde oder die SSH-Verbidung neu aufgebaut werden musste.
Befehl: pip install nvidia-riva-client
Mit dem jetzt folgenden Befehl wird das nvidia-riva Repository auf den Rechner herunter geladen.
Befehl: git clone https://github.com/nvidia-riva/python-clients.git
Jetzt müssen wir in das Repository also in den Ordner wechseln der angelegt wurde.
Befehl: cd python-clients
Weil wir das Streaming-Profil fahren, nutzen wir das Streaming-Skript transcribe_file.py das bereits dabei ist. Ees streamt die Datei chunk-weise an den Dienst und genau so erreichen wir das Verhalten, das wir gleich live brauchen.
Hinweis: Wie in Teil 1 gilt: Mono-WAV, 16 kHz im Zweifel vorher mit ffmpeg konvertieren.
Wichtig ist das im Ordner z.B. /home/ingmar/audio/ eine Datei audio.wav liegt die Mono und nicht als Stereo aufgenommen wurde.
Befehl: python python-clients/scripts/asr/transcribe_file.py --server 0.0.0.0:50051 --language-code de-DE --automatic-punctuation --input-file /home/ingmar/audio/audio.wav
Bei mir wurde dann als Ergebnis der eingesprochene Text im Terminal-Fenster ausgegeben.
Sprach-Code prüfen: Das multilinguale Parakeet erkennt die gesprochene Sprache teils automatisch, und die exakt erwarteten Sprach-Codes hängen vom geladenen Profil ab. Welche Modelle und Codes dein Container tatsächlich anbietet, listet dir folgender Aufruf auf. Den passenden Wert tragen wir danach an einer Stelle in der Web-App ein:
python python-clients/scripts/asr/transcribe_file.py \
--server 0.0.0.0:50051 --list-modelsKommt hier ein sauberes deutsches Transkript mit Satzzeichen zurück, ist die Basis fertig – und wir können die Live-App andocken.
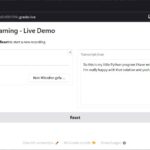
Schritt 7: Die Live-App an das NIM andocken
Jetzt kommt der Brückenschlag zu Teil 1. Statt das Modell wie damals selbst zu laden, wird unsere Gradio-App zum Streaming-Client: Sie nimmt das Mikrofon auf, wandelt das Audio nach Mono/16 kHz und schickt es chunk-weise über die Riva-gRPC-Streaming-API an localhost:50051. Die Transkripte laufen live zurück in den Browser.
Die nötigen Pakete installieren wir jetzt in der venv riva-client:
Befehl: pip install gradio nvidia-riva-client numpy scipy
Anschließend startest du die App. Den Sprach-Code aus Schritt 6 trägst du oben in der Datei bei LANGUAGE_CODE ein; NIM_SERVER bleibt auf localhost:50051.
Befehl: python nim_asr_gradio_app.py
Download: Das Python-Programm gibt es hier zum Download.
Wie in Teil 1 brauchst du für den Mikrofon-Zugriff entweder einen SSH-Tunnel auf den Server oder die Gradio-Share-URL (share=True), weil der Browser ohne HTTPS sonst kein Mikrofon freigibt.
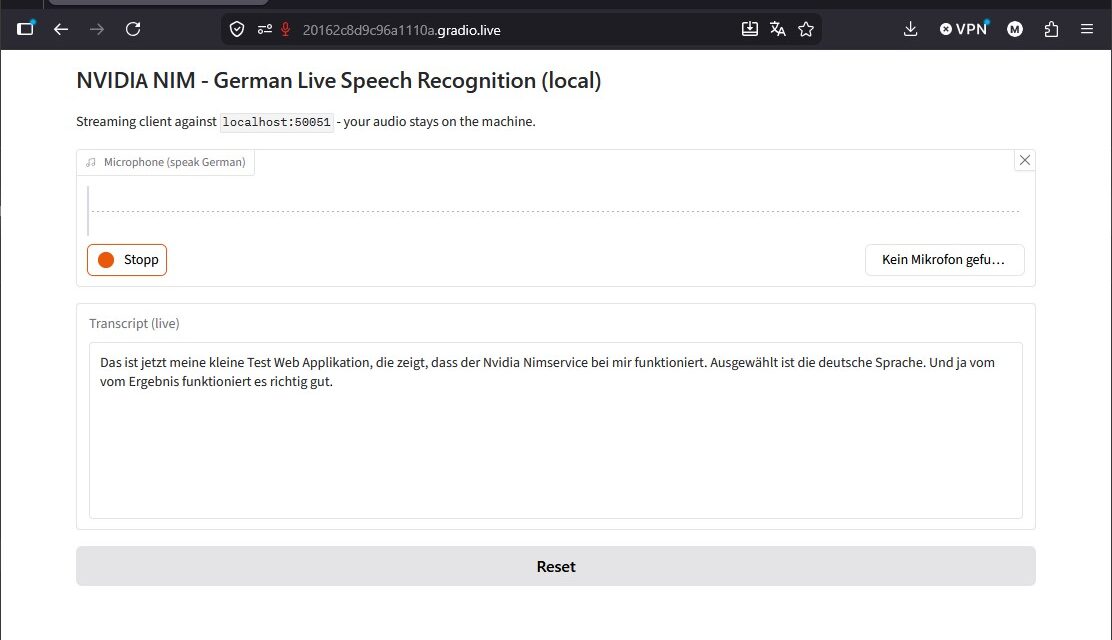
Web-App Screenshot:
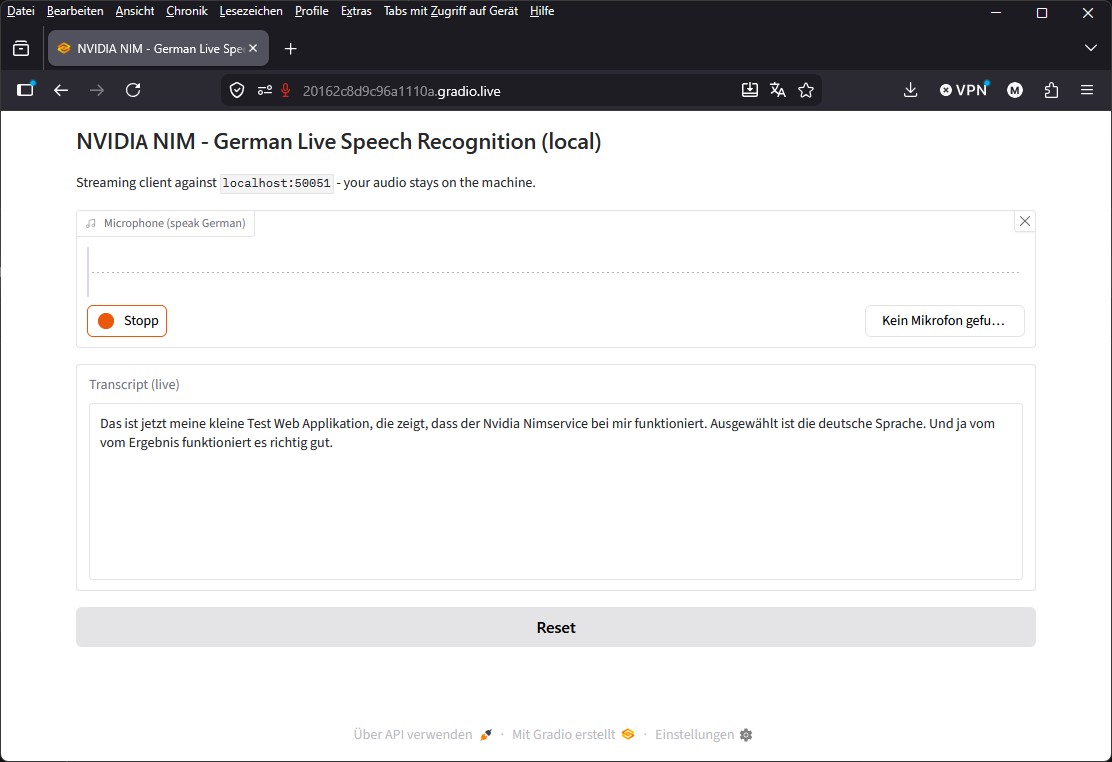
NVIDIA NIM ASR Web-App
Schritt 8: Die NIM-Profile im Überblick
NIM stellt für ein Modell mehrere Profile bereit, die du über NIM_TAGS_SELECTOR wählst. Für den späteren Voice-Agenten ist das Streaming-Profil mit niedriger Latenz entscheidend. Das ist der Grund warum ich oben mode=str genommen.
| NIM_TAGS_SELECTOR | Modus | Wann nehmen? |
|---|---|---|
mode=str |
Streaming, niedrige Latenz | Live-Transkription, Voice-Agent (unsere Wahl) |
mode=str-thr |
Streaming, hoher Durchsatz | Viele parallele Streams gleichzeitig |
mode=ofl |
Offline / Batch | Ganze Dateien am Stück, höchste Genauigkeit |
Tipps und Troubleshooting
- VRAM im Blick behalten: Prüfe mit
nvidia-smi, dass der Container die GPU belegt und genug Speicher frei ist. - Falsche GPU: Über
--gpus '"device=0"'wählst du gezielt eine Karte aus. Auf einem Multi-GPU-Rechner ist das wichtig. - Audioformat: Mono, 16 kHz – die häufigste Fehlerquelle, genau wie bei Nemotron in Teil 1. Die Web-App normalisiert das Mikrofon-Audio vor dem Senden automatisch.
- Mikrofon im Browser: Ohne HTTPS kein Mikrofon. Entweder SSH-Tunnel auf den Server legen oder die Gradio-Share-URL nutzen.
- Ports belegt: Laufen 9000 oder 50051 schon, einfach im
docker runauf freie Ports umbiegen.
Fazit
Mit NIM wird aus dem händischen Framework-Aufbau von Teil 1 ein sauberer, reproduzierbarer Microservice: ein Container, eine standardisierte API, deutsche Live-Spracherkennung auf eigener Hardware. Dieselbe Web-App wie in Teil 1, aber mit ausgetauschtem Unterbau. Die wichtigste Änderung ist, dass Modell ist jetzt ein Dienst, die App nur noch sein Client. Das passt exakt in den Gedanken der souveränen KI, der sich durch meinen gesamten Stack zieht. Die Daten gehören mir und bleiben bei mir, die Kontrolle bleibt bei mir.
Im nächsten Teil nehme ich mir das Schwestermodell vor: NVIDIA Canary als NIM. Canary glänzt bei der Genauigkeit und kann zusätzlich übersetzen . Also aus deutschem Audio direkt englischen Text erzeugen. Danach folgt mit Magpie-TTS die Sprachausgabe, und Stück für Stück wächst daraus der vollständige lokale Sprach-Agent.
Wenn du das Setup nachbaust: Schreib mir gern in die Kommentare, welches Modell-Profil bei dir auf welcher Hardware die beste Balance aus Latenz und Genauigkeit liefert.



{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…