
Wer im Bereich der KI-Bilderzeugung mit Tools wie ComfyUI arbeitet, kennt das Problem: Ein Workflow rendert, und man möchte bereits den nächsten vorbereiten oder eine zweite Idee parallel testen. Mit nur einer GPU wird das schnell zum Flaschenhals. Doch was, wenn man das Glück hat, zwei oder mehr Grafikkarten in seinem System zu haben? Dann lässt sich die Arbeit wunderbar parallelisieren!
In diesem Beitrag zeige ich Dir, wie Du zwei separate Instanzen von ComfyUI auf einem Ubuntu-System startest und jeder Instanz eine eigene GPU zuweist. Damit das Ganze auch nach einem Neustart automatisch funktioniert, richten wir die Instanzen als systemd-Dienste ein. Zusätzlich optimieren wir unser Setup, indem wir das speicherintensive models-Verzeichnis auf ein separates, größeres Laufwerk auslagern.
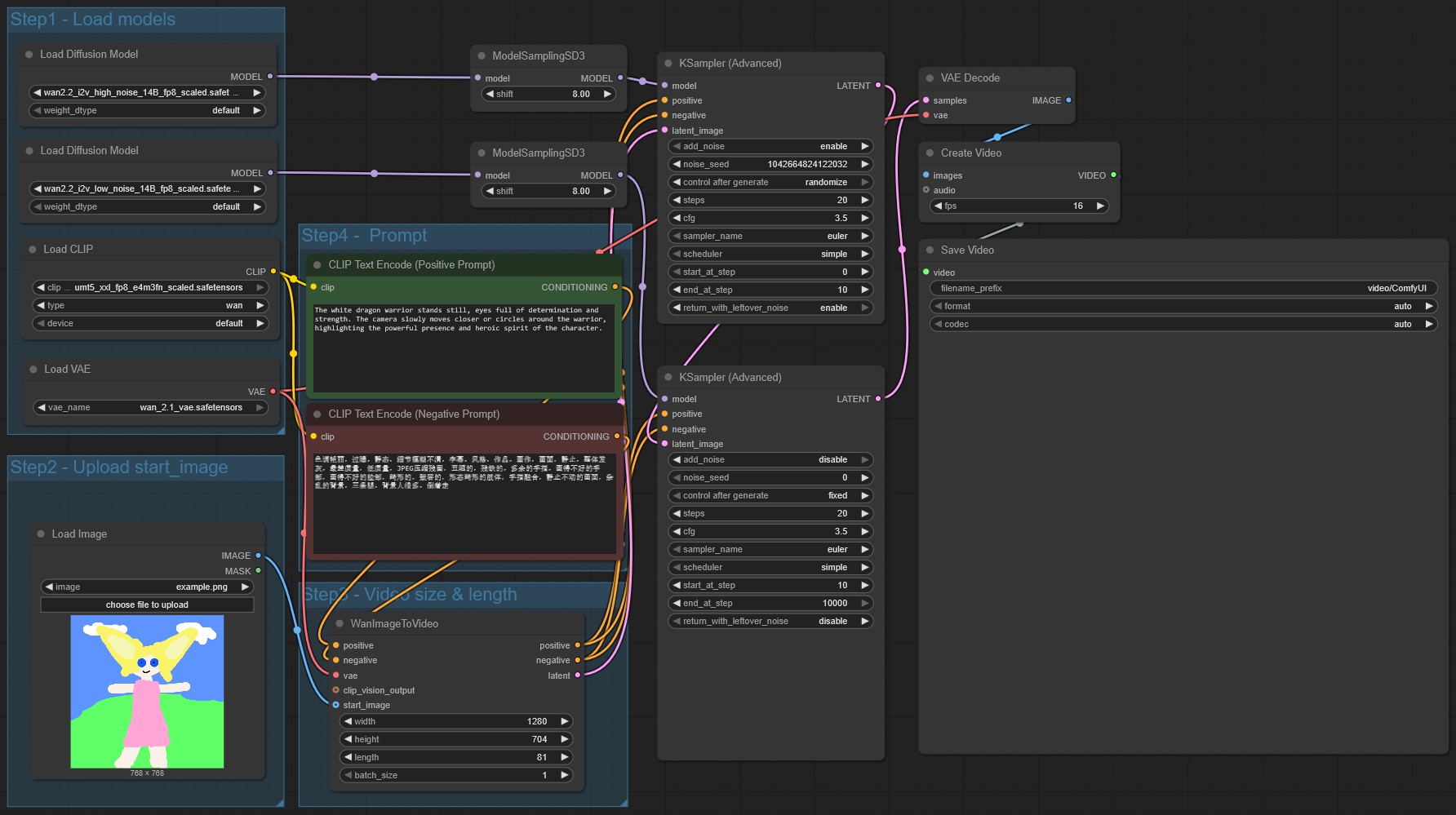
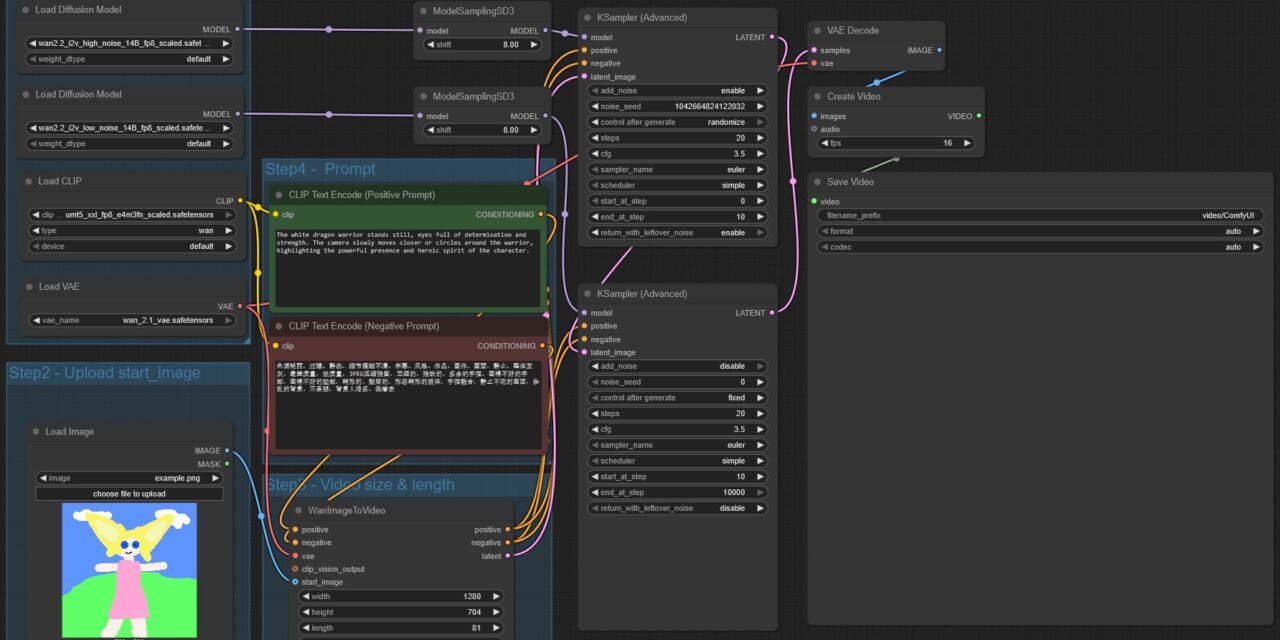
WAN2.2 ComfyUI Workflow
Die Magie der systemd-Services
Um ComfyUI nicht jedes Mal manuell im Terminal starten zu müssen, nutzen wir systemd, den Standard-Init-System-Manager in den meisten modernen Linux-Distributionen. Wir legen für jede GPU eine eigene Service-Datei an.
Vorbereitung: Erstelle zwei neue Service-Dateien im Verzeichnis /etc/systemd/system/. Du benötigst dafür sudo-Rechte.
Befehl: sudo nano /etc/systemd/system/comfyui-gpu0.service
Befehl: sudo nano /etc/systemd/system/comfyui-gpu1.service
Service-Datei für die erste GPU (GPU 0)
Füge den folgenden Inhalt in die Datei comfyui-gpu0.service ein. Passe bei Bedarf den Benutzer (User=ingmar) und die Pfade zu deinem ComfyUI-Verzeichnis an.
Wichtig: Achte darauf das Du in der Zeile User=ingmar Deinen user eintägst mit dem der Service also ComfyUI gestartet werden soll. Andernfalls wird es zu Fehler kommen und der Service nicht starten. Das gleiche gilt für die Pfade weiter in der Konfiguration die ebenfalls angepasst werden müssen.
# ComfyUI GPU 0
[Unit]
Description=ComfyUI instance on GPU 0
After=network.target
[Service]
Type=simple
User=ingmar
WorkingDirectory=/home/ingmar/ComfyUI
Environment="CUDA_VISIBLE_DEVICES=0"
ExecStart=/home/ingmar/ComfyUI/venv_comfyUI/bin/python /home/ingmar/ComfyUI/main.py --port 8188 --listen --highvram --extra-model-paths-config /home/ingmar/ComfyUI/extra_model_paths.yaml
Restart=always
Environment=PYTHONUNBUFFERED=1
[Install]
WantedBy=multi-user.target
Was passiert hier?
- Description: Eine kurze Beschreibung dessen, was der Service tut.
- User: Der Benutzer, unter dem das Skript ausgeführt wird.
- WorkingDirectory: Das Hauptverzeichnis deiner ComfyUI-Installation.
- Environment=“CUDA_VISIBLE_DEVICES=0″: Das ist der entscheidende Befehl! Er sorgt dafür, dass dieser Prozess nur die GPU mit der ID 0 „sehen“ und nutzen kann.
- ExecStart: Der eigentliche Startbefehl. Wir starten ComfyUI auf Port 8188 und übergeben den Pfad zu unserer Konfigurationsdatei für die ausgelagerten Modelle.
- Restart=always: Stürzt ComfyUI ab, wird es automatisch neu gestartet.
Service-Datei für die zweite GPU (GPU 1)
Nun füllen wir die Datei comfyui-gpu1.service mit fast identischem Inhalt. Wir ändern lediglich drei wichtige Details: die Beschreibung, die zugewiesene GPU und den Port.
# ComfyUI GPU 1
[Unit]
Description=ComfyUI instance on GPU 1
After=network.target
[Service]
Type=simple
User=ingmar
WorkingDirectory=/home/ingmar/ComfyUI
Environment="CUDA_VISIBLE_DEVICES=1"
ExecStart=/home/ingmar/ComfyUI/venv_comfyUI/bin/python /home/ingmar/ComfyUI/main.py --port 8189 --listen --highvram --extra-model-paths-config /home/ingmar/ComfyUI/extra_model_paths.yaml
Restart=always
Environment=PYTHONUNBUFFERED=1
[Install]
WantedBy=multi-user.target
Die Änderungen im Detail:
- Description: Angepasst für die „GPU 1“.
- Environment=“CUDA_VISIBLE_DEVICES=1″: Dieser Prozess wird exklusiv auf der GPU mit der ID 1 laufen.
- ExecStart: Wir verwenden hier den Port 8189, damit sich die beiden Instanzen nicht gegenseitig blockieren.
Services aktivieren und steuern
Nachdem die Dateien gespeichert sind, müssen wir systemd mitteilen, dass es neue Konfigurationen gibt und die Dienste starten und für den automatischen Start aktivieren.
# systemd neu laden, um die neuen Services zu erkennen
Befehl: sudo systemctl daemon-reload
# Die Services zum ersten Mal starten
Befehl: sudo systemctl start comfyui-gpu0.service
Befehl: sudo systemctl start comfyui-gpu1.service
# Die Services für den automatischen Start beim Systemstart aktivieren
Befehl: sudo systemctl enable comfyui-gpu0.service
Befehl: sudo systemctl enable comfyui-gpu1.service
Nun kannst Du auf zwei ComfyUI-Instanzenüber Deinen Browser zugreifen:
- GPU 0:
http://<deine-server-ip>:8188 - GPU 1:
http://<deine-server-ip>:8189
Mit sudo systemctl status comfyui-gpu0.service kannst Du jederzeit den Status des jeweiligen Dienstes überprüfen.
Befehl: sudo systemctl status comfyui-gpu0.service
Befehl: sudo systemctl status comfyui-gpu1.service
Speicherplatz schaffen: Modelle auf ein anderes Laufwerk auslagern
Checkpoints, LoRAs und andere Modelle können schnell mehrere hundert Gigabyte an Speicherplatz belegen. Oft ist die Systemfestplatte dafür nicht der beste Ort. ComfyUI bietet eine elegante Lösung, um das models-Verzeichnis auszulagern: die extra_model_paths.yaml-Datei.
Erstelle diese Datei im Hauptverzeichnis von ComfyUI und öffne sie mit einem Editor.
Befehl: nano /home/ingmar/ComfyUI/extra_model_paths.yaml
In der Theorie sollte es ausreichen, einen base_path anzugeben, der auf das neue models-Verzeichnis verweist. In der Praxis hat sich jedoch bei mir gezeigt, dass das Definieren der einzelnen Unterverzeichnisse zuverlässiger funktioniert.
Hier ist meine Konfiguration als Beispiel. Alle meine Modelle liegen nun auf einem Laufwerk, das unter /mnt/temp_01/ComfyUi/models eingehängt ist.
comfyui:
# Der 'base_path' ist der Hauptordner auf deinem neuen Laufwerk
# base_path: /mnt/temp_01/ComfyUi/models/
checkpoints: /mnt/temp_01/ComfyUi/models/checkpoints
clip: /mnt/temp_01/ComfyUi/models/clip
clip_vision: /mnt/temp_01/ComfyUi/models/clip_vision
configs: /mnt/temp_01/ComfyUi/models/configs
controlnet: /mnt/temp_01/ComfyUi/models/controlnet
diffusers: /mnt/temp_01/ComfyUi/models/diffusers
diffusion_models: /mnt/temp_01/ComfyUi/models/diffusion_models
embeddings: /mnt/temp_01/ComfyUi/models/embeddings
gligen: /mnt/temp_01/ComfyUi/models/gligen
hypernetworks: /mnt/temp_01/ComfyUi/models/hypernetworks
LLM: /mnt/temp_01/ComfyUi/models/LLM
loras: /mnt/temp_01/ComfyUi/models/loras
photomaker: /mnt/temp_01/ComfyUi/models/photomaker
style_models: /mnt/temp_01/ComfyUi/models/style_models
text_encoders: /mnt/temp_01/ComfyUi/models/text_encoders
unet: /mnt/temp_01/ComfyUi/models/unet
upscale_models: /mnt/temp_01/ComfyUi/models/upscale_models
vae: /mnt/temp_01/ComfyUi/models/vae
vae_approx: /mnt/temp_01/ComfyUi/models/vae_approx
Damit ComfyUI diese Konfiguration auch verwendet, haben wir in unseren systemd-Service-Dateien den Parameter --extra-model-paths-config hinzugefügt. Nach einem Neustart der Dienste (sudo systemctl restart comfyui-gpu0.service oder sudo systemctl restart comfyui-gpu1.service) werden alle Modelle vom neuen Speicherort geladen.
Fazit
Mit diesem Setup kannst Du Deinen Workflow zur Bilderzeugung erheblich beschleunigen. Während eine GPU einen komplexen Batch-Job abarbeitet, kannst Du auf der zweiten Instanz bereits neue Prompts testen, Workflows anpassen oder einfach eine zweite Generation starten. Die Kombination aus dedizierter GPU-Zuweisung über systemd und der Auslagerung der Modelle macht dein ComfyUI-System robust, wartungsfreundlich und extrem leistungsfähig.



{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…