
Du hast den ersten großen Schritt getan: Dein eigner, unabhängiger Ollama-Server läuft, die Tokens sind kostenlos und die Daten bleiben bei Dir. Digitale Souveränität ist Realität. Aber Hand aufs Herz: Die Interaktion über die Kommandozeile ist mühsam und ineffizient.
Was wir jetzt brauchen, ist ein Cockpit – eine elegante, grafische Oberfläche, die Deine lokale KI einfach bedienbar macht, ohne sie an externe Cloud-Anbieter zu binden.
Ich zeige Dir heute, wie ich genau das umgesetzt habe, indem ich Open WebUI als Docker-Container auf meinem Ubuntu-Server installiert habe. Du wirst sehen: Die Kombination aus Deinem souveränen Ollama-Backend und diesem Interface ist der Schlüssel zur perfekten, lokalen LLM-Erfahrung.
Voraussetzungen: Ollama im Netzwerk
Damit Open WebUI (das in einem eigenen Docker-Container läuft) mit Deinem Ollama-Server sprechen kann, sind die Vorarbeiten aus meiner vorherigen Anleitung „Souveräne KI für mich und für dich: So baue ich meinen eigenen, unabhängigen Ollama-Server mit NVIDIA GPU-Power“ entscheidend. In dieser erkläre ich detailliert wie Du ein eigenes Ollama Docker Image baust und ausführst:
- Docker & Docker Compose sind installiert.
- Dein Ollama-Server läuft und ist über
OLLAMA_HOST=0.0.0.0(oder Deine spezifische IP) für andere Dienste im Netzwerk (und damit für den Open WebUI-Container) erreichbar.
Phase 1: Die Installation des Web-Cockpits (Open WebUI)
Open WebUI bietet ein offizielles Docker-Image an, was die Installation denkbar einfach macht. Wir müssen nur den Container starten und ihm die richtigen Regeln für den Netzwerkzugriff und die Datenhoheit mitgeben.
Der Befehl zum Starten
Öffne ein Terminal auf Deinem Server und führe den folgenden Befehl aus. Er startet Open WebUI im Hintergrund und legt alle Konfigurationsdaten persistent ab.
Befehl: sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Die Logik hinter dem Befehl (Kontrolle und Persistenz)
Wir schauen uns jeden Teil des Befehls an, um sicherzustellen, dass Deine Kontrolle über die Infrastruktur gewahrt bleibt:
| Parameter | Parameter Beschreibung | Die Logik dahinter (Deine Kontrolle) |
| docker run -d | Startet den Container im Hintergrund. | Gewährleistet, dass das Interface zuverlässig im Hintergrund läuft. |
| -p 3000:8080 | Leitet den externen Port 3000 Deines Servers zum internen Port 8080 des Containers um. | Du entscheidest, über welchen Port Du die Oberfläche erreichst (hier Port 3000). |
| -v open-webui:/app/backend/data | Erstellt ein permanentes Docker Volume namens open-webui auf Deinem Server und mountet es in den Container. | Datenhoheit: Alle Deine Benutzerkonten, Einstellungen und Chat-Verläufe bleiben permanent und lokal auf Deinem Server gespeichert. Nichts geht verloren. |
| –name open-webui | Gibt dem Container einen leicht identifizierbaren Namen. | Bessere Kompetenzhoheit und einfaches Management via Docker Compose oder CLI. |
| –restart always | Stellt sicher, dass der Container bei jedem Server-Neustart automatisch startet. | Zuverlässigkeit und minimale Wartung. |
| –add-host=host.docker.internal:host-gateway | Fügt den Host-Server (dort, wo Ollama läuft) unter dem Namen host.docker.internal in das Netzwerk des WebUI-Containers ein. | Netzwerk-Brücke: Ermöglicht Open WebUI die Kommunikation mit dem Ollama-Server (Dein LLM-Backend) über dessen lokale IP-Adresse oder den Host-Gateway. |
| ghcr.io/open-webui/open-webui:main | Der Name des offiziellen, vorgefertigten Docker-Images. | Wir nutzen das fertige Image, da die Versionsanzeige hier zuverlässig ist, während die Datenhoheit und GPU-Kontrolle durch die Volume- und Deploy-Einstellungen des Ollama-Containers gesichert sind. |
Phase 2: Erststart und Verbindung zu Ollama
Nachdem der Container gestartet ist, ist der Zugriff und die Verknüpfung mit Deinem Ollama-Backend nur noch Formsache.
1. Zugriff auf die Web-Oberfläche
Öffne einen Browser und navigiere zur Adresse Deines Servers auf dem definierten Port:
http://<IP-Adresse-Deines-Servers>:3000
Du wirst jetzt aufgefordert, einen Benutzeraccount zu registrieren. Da das Volume persistent gemappt wurde, sind dies die Zugangsdaten für Dein lokales KI-Cockpit.
2. Ollama-Verbindung prüfen
Nach dem Login sollte Open WebUI Deinen Ollama-Server automatisch erkennen, da wir die Host-Brücke (host.docker.internal) genutzt haben.
Wichtig: Falls keine Verbindung hergestellt werden kann, musst Du im Einstellungsmenü (oftmals im Admin-Bereich oder den Settings) die API-Basis-URL manuell auf die IP Deines Ollama-Servers (oder des Host-Gateways) umstellen:
http://<IP-Adresse-Deines-Ollama-Servers>:11434
3. Modelle herunterladen und chatten
Sobald die Verbindung steht, kannst Du über die Open WebUI-Oberfläche:
- Neue Modelle (wie
llama3:8bodermistral:7b) direkt aus der Ollama-Registry suchen und mit einem Klick auf Deinen Server herunterladen. - Chat-Sitzungen starten und Deine lokalen LLMs über das intuitive Interface nutzen.
Beim Starten einer Anfrage wirst Du über die nvidia-smi-Konsole beobachten können, wie Deine zwei RTX 4090 GPUs sofort anspringen, um die Inferenz Deiner Modelle durchzuführen.
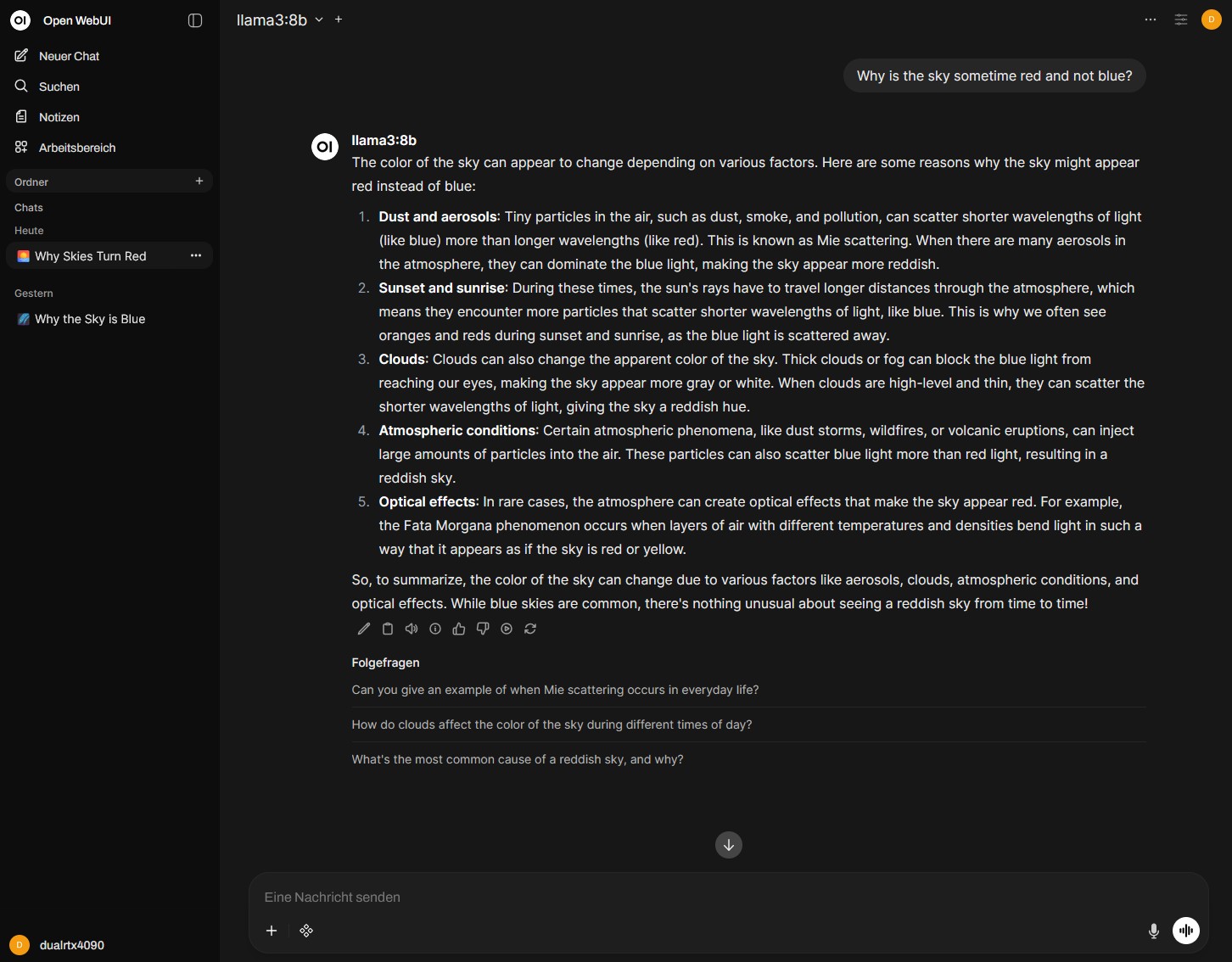
Open WebUI Chat Interface
Dein Souveränes KI-Setup ist komplett
Mit Open WebUI als Frontend hast Du Dein souveränes KI-Setup perfektioniert:
- Backend (Ollama): Volle Kontrolle über Code und Hardware. Kostenloser, lokaler Betrieb.
- Daten (Volumes): Alle Modelle und Chat-Historien bleiben unter Deiner Hoheit.
- Frontend (Open WebUI): Intuitive, moderne Bedienung.
Du hast nun nicht nur die technische Basis geschaffen, sondern auch die Kompetenzhoheit erlangt, um Deine KI-Umgebung selbstbestimmt und benutzerfreundlich zu verwalten. Das ist die wahre digitale Souveränität.
(Anmerkung: Das folgende wird NICHT im Blog veröffentlicht, sondern ist nur eine Ergänzung für Dich:)
Wenn Du auch das Open WebUI-Image selbst bauen und so die maximale Souveränität erreichen willst (analog zu Deinem Ollama-Vorgehen), ist der Prozess zwar aufwendiger, aber möglich. Hierbei würdest Du das Open WebUI-Repository klonen und docker compose build verwenden, wobei Du die Umgebungsvariable OLLAMA_API_BASE_URL in der docker-compose.yml setzen müsstest.
Die "Souveräne KI"-Serie: Ihr Weg zur digitalen Unabhängigkeit
Herzlichen Glückwunsch! Um Sie bei der vollen Kontrolle über Ihre KI-Infrastruktur zu unterstützen, finden Sie hier die vollständige Linksammlung aller Artikel aus dieser Serie:

{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…