

Die Fähigkeit, gesprochene Worte präzise in Text umzuwandeln, ist ein Wendepunkt für Content-Ersteller, Forscher und alle, die mit Besprechungsaufzeichnungen, Interviews oder Videoinhalten arbeiten. Aber was wäre, wenn Sie die Worte nicht nur transkribieren, sondern auch sofort wissen könnten, wer was und wann gesagt hat?
Willkommen bei der Whisper + PyAnnote Transcription & Speaker Diarization App – einem leistungsstarken, webbasierten Tool, das die erstklassige Transkription von OpenAI Whisper und die präzise Sprecheridentifikation von PyAnnote.audio in einer benutzerfreundlichen Gradio-Oberfläche vereint. Das tolle dabei ist es läuft alles lokal auf der eigenen Hardware. Keine Daten verlassen das eigene Netzwerk.
Revolutionieren Sie Ihren Workflow mit lokaler KI-Transkription
Diese Anwendung ist nicht nur ein einfacher Transkriptionsdienst; sie ist ein komplettes Toolkit zur Medienverarbeitung und -analyse. Sie ermöglicht es Ihnen, rohe Audio-/Videodateien und Medien-URLs in strukturierte, durchsuchbare und bearbeitbare Transkripte umzuwandeln.
Wichtige Funktionen im Überblick
-
Universeller Media Downloader: Laden Sie Inhalte direkt von YouTube, Vimeo und über 1000 weiteren Plattformen mit
yt-dlpherunter. Die App verarbeitet sogar ganze YouTube-Playlists. -
Präzise Transkription & Übersetzung: Nutzen Sie verschiedene Whisper-Modelle (von tiny bis large-v3) für genaue Transkriptionen in über 50 Sprachen oder übersetzen Sie jede Sprache direkt ins Englische.
-
Automatische Sprecher-Diarisierung: Das Highlight! PyAnnote.audio analysiert die Konversation und identifiziert sowie kennzeichnet automatisch verschiedene Sprecher.
-
Zeitgestempelter Output: Erhalten Sie ein präzises, zeitgestempeltes Protokoll für jedes einzelne Sprachsegment, das es einfach macht, zur genauen Stelle zurückzuspringen, an der eine Phrase gesprochen wurde:
[00:05 - 00:15] Speaker 1: Hello, how are you? -
Bearbeitung & Umbenennung in der App: Bereinigen Sie Transkripte und benennen Sie Sprecher um (z. B. „Sprecher 1“ in „John“) direkt innerhalb der Weboberfläche.
-
KI-gestützte Analyse (Ollama): Chatten Sie mit Ihrem Transkript! Verwenden Sie lokale Ollama-Modelle (wie Llama 3), um Fragen zu stellen, Interviews zusammenzufassen und wichtige Erkenntnisse aus dem gerade generierten Text zu extrahieren.

Whisper PyAnnote Diarization App Process
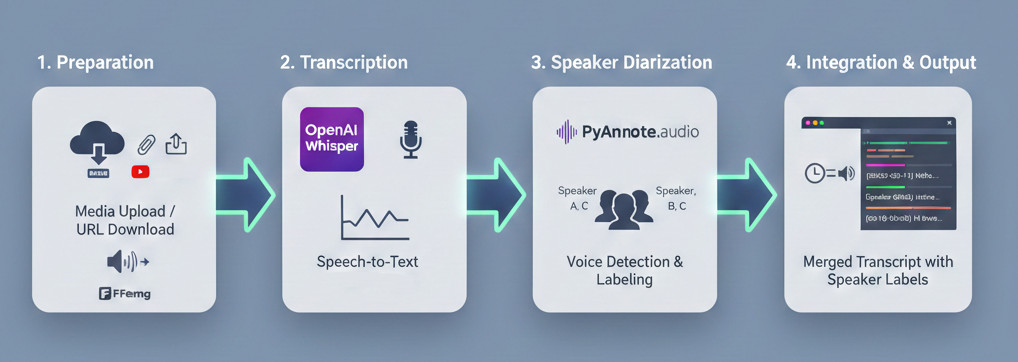
So funktioniert’s: Die KI-Pipeline
Die Anwendung funktioniert, indem sie drei leistungsstarke Open-Source-Technologien in einer einzigen, nahtlosen Pipeline miteinander verbindet.
-
Vorbereitung: Laden Sie eine Audio-/Videodatei hoch oder fügen Sie eine URL ein, damit der integrierte Downloader den Inhalt abruft. Die Medien werden dann mithilfe von FFmpeg vorverarbeitet, um die Kompatibilität zu gewährleisten.
-
Transkription: Das Whisper-Modell verarbeitet das Audio, wandelt Sprache in Text um und generiert hochpräzise wortweise Zeitstempel.
-
Diarisierung: PyAnnote.audio führt eine separate Analyse des Audios durch. Es erkennt Änderungen in der Stimme und weist jedem einzelnen Sprecher eindeutige Kennzeichnungen zu.
-
Integration: Die Anwendung gleicht die Whisper-Segmente intelligent mit den PyAnnote-Sprecherkennzeichnungen basierend auf der zeitlichen Überlappung ab, was zu dem endgültigen, ansprechend formatierten, zeitgestempelten Transkript mit Sprecheridentifikation führt.
Whisper PyAnnote Diarization App
Technischer Vorteil: GPU-Beschleunigung
Für die beste Geschwindigkeit und Qualität erkennt das System automatisch Ihre NVIDIA GPU und installiert die CUDA-fähige Version von PyTorch, was die Verarbeitungszeit sowohl für Whisper als auch für PyAnnote dramatisch beschleunigt.
Erste Schritte
Bereit für eine völlig neue Erfahrung der Audioanalyse? Hier ist, was Sie für den Einstieg benötigen.
📋 Voraussetzungen
Sie benötigen einige Schlüsselkomponenten, die auf Ihrem System installiert sind, bevor Sie die App ausführen können:
-
Python 3.9+
-
FFmpeg: Essenziell für die gesamte Audio-/Videoverarbeitung.
-
Hugging Face Account & Token: Erforderlich, um auf die leistungsstarken, geschützten PyAnnote-Modelle zugreifen zu können. Vergessen Sie nicht, die Bedingungen für die erforderlichen Modelle im Hugging Face Hub zu akzeptieren!
-
Ollama (Optional): Installieren Sie dies, wenn Sie den KI-gestützten Analyse-Tab nutzen möchten.
🛠️ Installation ist automatisiert!
Das Projekt bietet ein hervorragendes, vollautomatisiertes Installationsskript (install_whisper_pyannote.sh) für Linux, das alles übernimmt: Erstellung einer virtuellen Umgebung, Installation von Abhängigkeiten sowie Erkennung/Einrichtung der GPU-Unterstützung.
Konfigurieren Sie nach der Installation einfach Ihren Hugging Face Token in der Datei .env und führen Sie den folgenden Befehl aus:
Command: python whisper_PyAnnote.py
Navigieren Sie dann in Ihrem Browser zu http://<IP-Adresse>:7111, und Sie können mit der Transkription beginnen!
Die Macht der Analyse
Der Analyse-Tab schöpft den Wert Ihrer Transkripte erst richtig aus. Anstatt Stunden von Text manuell durchzuarbeiten, können Sie lokale, datenschutzorientierte KI-Modelle über Ollama nutzen, um:
-
Executive Summaries von langen Besprechungen zu generieren.
-
Wichtige Aktionspunkte und Entscheidungen zu identifizieren.
-
Komplexe Fragen zum Inhalt zu stellen (z. B. „Was waren Johns Hauptbedenken bezüglich des Budgets?“).
Durch die Kombination von Transkription, Sprecher-ID und KI-Analyse ist die Whisper + PyAnnote App ein unverzichtbares Werkzeug für jeden, der es ernst meint mit der Extraktion von Informationen aus gesprochenen Daten.



{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…