

Die beiden Hälften eines Sprach-Agenten stehen: Mit Parakeet (Teil 2) und Canary (Teil 3) hört der Agent zu, mit Magpie (Teil 4) antwortet er. Was noch fehlt, ist das Gehirn: die Schicht, die aus dem erkannten Text eine Entscheidung macht und die passende Antwort oder Aktion auslöst. Genau dafür nehme ich mir in diesem Teil das NVIDIA NeMo Agent Toolkit (NAT) vor. Mit NAT baue ich den Orchestrator, der später im Voice-Loop zwischen ASR und TTS sitzt.
Was ist das NeMo Agent Toolkit – und ist das ein Teil des NIM?
Kurz vorweg, weil ich genau diese Frage hatte: NAT ist kein NIM. Die beiden Dinge liegen auf unterschiedlichen Ebenen.
Ein NIM ist eine Auslieferungsform für Modelle von NVIDIA. Es ist vielmehr ein Docker-Container, der ein Modell (ASR, TTS oder ein LLM) hinter einer standardisierten API serviert. Das NeMo Agent Toolkit ist dagegen ein Framework, also eine Python-Bibliothek, die du separat installierst (pip install nvidia-nat) und über die CLI nat mit YAML-Workflows steuerst. NAT braucht selbst keine GPU; es ruft Modelle nur auf.
Das Verhältnis ist also: NAT ist der Dirigent, die NIMs (und dein Ollama-LLM) sind das Orchester. Welches LLM NAT zum Denken nutzt, trägst du im YAML über z. B. die Base-URL sowie Schnittsellentyp ein. Das LLM kann also ein LLM-NIM sein oder, wie bei mir, mein bestehender Ollama-Server. NAT steckt also nicht „im NIM“, sondern sitzt eine Ebene darüber.
Hinweis: Die NAT-Grundlagen habe ich in eigenen Beiträgen schon ausführlich behandelt. So habe ich einen Beitrag zu dem Setup mit Ollama in „Vom Inferenz-Layer zum Orchestrator-Layer“, die ReAct-Schleife und ein eigenes Python-Tool sowie das Multi-Agent-Supervisor-Pattern. Hier in diesem Beitrag wiederhole ich das alles bewusst nicht, sondern baue den schlanken Teil, den ich für den Sprach-Loop brauche.
Das Zielbild dieses Beitrags
Wir bauen einen minimalen, lokalen Agenten-Workflow nach dem Muster Text rein -> Entscheidung/LLM -> Text raus. Genau diese Schnittstelle füttert später in Teil 6 die ASR (sie liefert den Text) und liest die TTS aus (sie spricht die Antwort). Am Ende stellen wir den Workflow als kleinen API-Dienst bereit, damit Pipecat ihn im nächsten Teil ansprechen kann. Als Reasoning-Backend dient mein bestehender Ollama-Server.
Voraussetzungen
- Ein laufendes lokales LLM-Backend. Bei mir ist das mein Ollama-Server (auf einer separaten Maschine); jedes OpenAI-kompatible Backend funktioniert.
- Python 3.11 und eine saubere venv analog zu den anderen Teilen.
- Netzwerkzugriff vom NAT-Rechner auf das LLM-Backend (IP/Port des Ollama-Servers).
- Die Speech-NIMs aus Teil 2–4 müssen für diesen Teil noch nicht laufen denn wir verdrahten sie erst in Teil 6.
Schritt 1: NAT installieren
NAT kommt in eine eigene venv, getrennt von der riva-client-Umgebung. Lege sie an und aktiviere sie:
Befehl: python3.11 -m venv ~/venvs/nat
Befehl: source ~/venvs/nat/bin/activate
Befehl: pip install --upgrade pip setuptools wheel
Dann das Toolkit installieren. Das Meta-Paket nvidia-nat bringt den Kern mit; Framework-Integrationen kommen als Extras dazu. Für den ReAct-Agenten brauchen wir die LangChain-Integration:
Befehl: pip install "nvidia-nat[langchain]"
Prüfe anschließend, dass die CLI da ist. Der folgende Befehl gibt die Hilfe und die Version aus:
Befehl: nat --version
Platzhalter: Die genaue Versionsnummer (aktuell 1.7.x) und ob neben [langchain] noch ein weiteres Extra nötig ist, tragen wir nach der Installation ein.
Schritt 2: Das lokale LLM-Backend eintragen
NAT-Workflows sind YAML-Dateien. NAT schreibt dir keinen festen Ablageort vor denn die Befehle nat run, serve und validate nehmen über --config_file jeden Pfad entgegen. Es lohnt sich daher, einen eigenen Projektordner anzulegen, in dem du alle Workflow-YAMLs sammelst. Für reine Konfigurations-Workflows (nur YAML + eingebaute Tools) reicht ein einfacher Ordner; eine configs/-Unterstruktur ist sauber und entspricht der Konvention, die NAT auch in seinen Beispielen nutzt:
Befehl: mkdir -p ~/nat-voice-agent/configs
Der llms:-Block in der Workflow-Datei sagt NAT, welches Modell es zum Arbeiten also für die Inferenz nutzt. Für ein OpenAI-kompatibles Backend wie Ollama ist der Typ openai; du zeigst einfach mit base_url auf den Ollama-Server. Lege jetzt die die Datei voice_agent.yml mit dem folgenden Befehl an:
Befehl: nano ~/nat-voice-agent/configs/voice_agent.yml
Und füge folgenden Inhalt ein:
llms:
local_llm:
_type: openai
api_key: "ollama" # von Ollama ignoriert, aber Pflichtfeld
base_url: "http://<OLLAMA-SERVER-IP>:11434/v1"
model_name: "<dein-ollama-modell>" # z. B. qwen3:8b oder llama3.1:8b
functions:
current_datetime:
_type: current_datetime
workflow:
_type: react_agent
tool_names: [current_datetime]
llm_name: local_llm
verbose: truePlatzhalter – beim Durchgehen eintragen:
base_url– die IP/der Port deines Ollama-Servers (bei lokalem Ollamahttp://localhost:11434/v1).model_name– der exakte Name des Modells, das du in Ollama geladen hast (mitollama listprüfen).
Mit Strg + x speicherst Du die Datei ab.
Validiere die frisch Konfiguration, bevor du sie startest denn das fängt YAML- und Schemafehler früh ab:
Befehl: nat validate --config_file ~/nat-voice-agent/configs/voice_agent.yml
Als Ergenis habe ich nach dem Ausführen des Befehls folgendes im Terminal-Fenster angezeigt bekommen.
Validating configuration file: /home/ingmar/nat-voice-agent/configs/voice_agent.yml
✓ Configuration file is valid!
(nat) ingmar@A6000Ada:~$
Hinweis: Solange wir nur eingebaute Tools nutzen, genügt dieser Ordner. Sobald du in Schritt 4 eigene Python-Tools schreibst, lohnt sich ein vollwertiges NAT-Projekt. Das legst du mit nat workflow create --workflow-dir ~/nat-voice-agent <name> an. So erzeugst Du die komplette Struktur inkl. configs/config.yml und pyproject.toml und so wird auch dein Tool gleich als Python-Package installiert.
Schritt 3: Der erste Lauf – Text rein, Text raus
Jetzt schicken wir eine einzelne Eingabe durch den Workflow. nat run ist der einfachste Weg und ideal zum Debuggen:
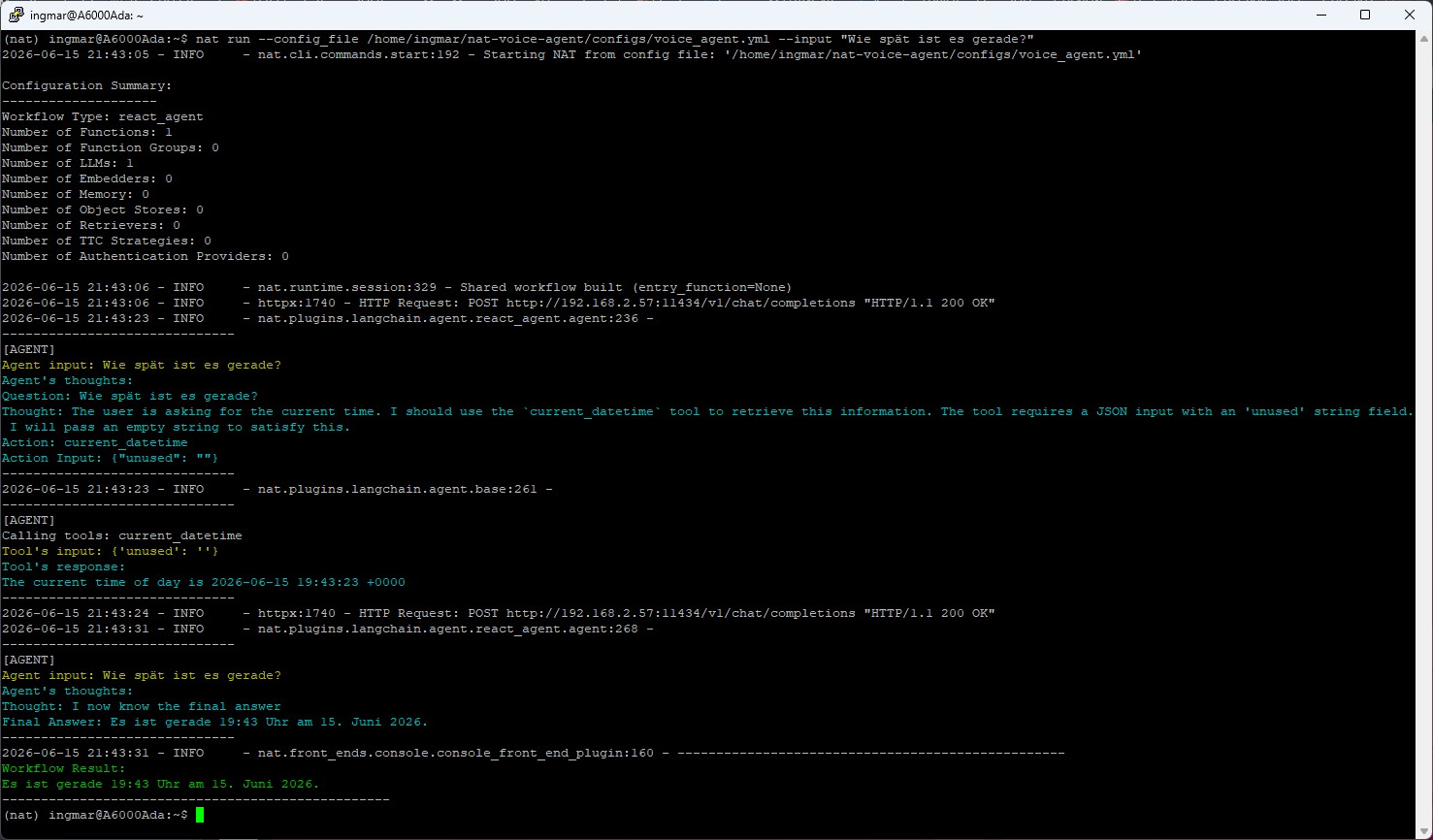
Befehl: nat run --config_file /home/ingmar/nat-voice-agent/configs/voice_agent.yml --input "Wie spät ist es gerade?"
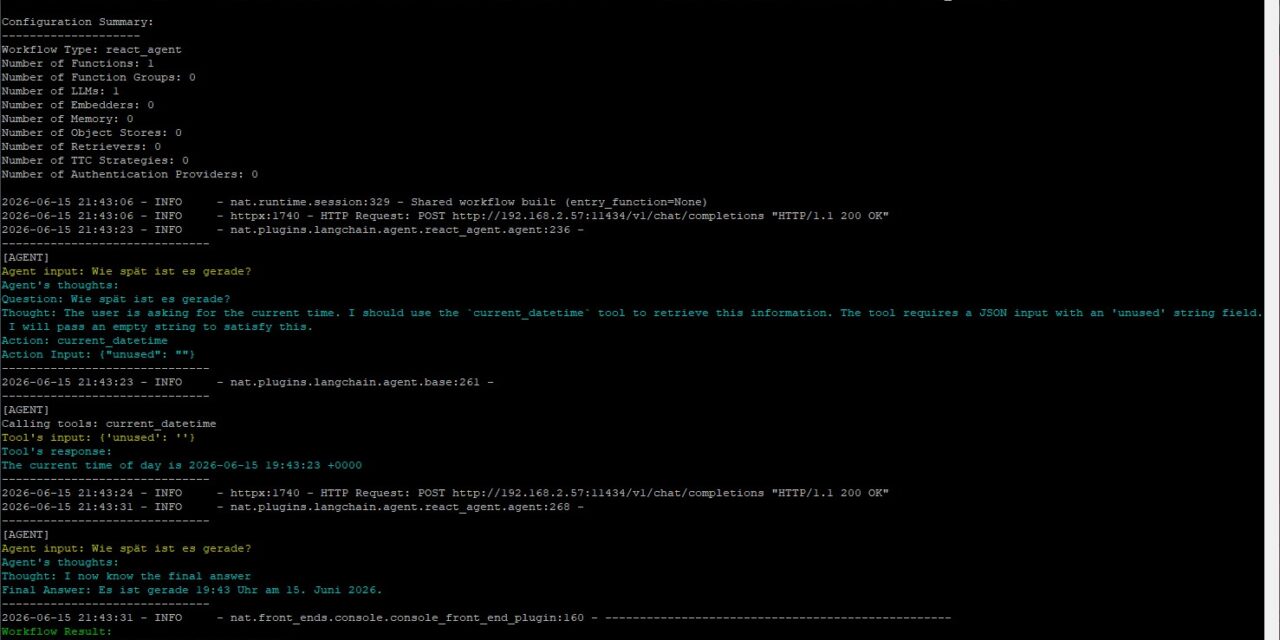
Der Agent durchläuft seine ReAct-Schleife, erkennt, dass er das current_datetime-Tool braucht, ruft es auf und formuliert eine Antwort in natürlicher Sprache. Genau dieses „Text rein → Text raus“ ist die Schnittstelle, die später ASR und TTS verbindet.
Das folgende Bild zeigt die Textausgabe die über das Tool [current_datetime] erzeugt wurde.
NVIDIA nim date time output
Schritt 4: Eigene Tools andocken
Ein Agent wird erst spannend, wenn er eigene Aktionen auslösen kann die einem auch bei etwas helfen. Die Zeitansage ist ja ganz nett aber mehr als eine Demonstration zu verstehen wie NAT und ReAct Templates funktionieren. Wie man ein eigenes Python-Tool schreibt, als Package registriert und im Workflow referenziert, habe ich hier im Orchestrierungs-Beitrag Schritt für Schritt gezeigt (dort am Beispiel eines GPU-Status-Tools).
Für den Sprach-Agenten reicht zunächst das Prinzip: Jedes registrierte Tool taucht unter functions: auf und wird im workflow.tool_names freigeschaltet. So wächst der Agent von „nur reden“ zu „etwas tun“.
Schritt 5: Den Agenten als Dienst bereitstellen
Das ist der entscheidende Brücken-Schritt zu Teil 6. Statt jede Eingabe einzeln über nat run zu schicken, starten wir den Workflow als Webserver. Pipecat schickt dann später den ASR-Text per HTTP-POST hinein und bekommt die Agenten-Antwort zurück, die direkt an die TTS geht.
Befehl: nat serve --config_file ~/nat-voice-agent/configs/voice_agent.yml
NAT startet einen lokalen HTTP-Server mit einer Swagger-/OpenAPI-Oberfläche, über die du die genauen Routen und das Anfrage-/Antwort-Schema einsehen und den Endpunkt direkt im Browser testen kannst.
Platzhalter – nach dem Start verifizieren: den genauen Host/Port aus der Startausgabe, die POST-Route und die URL der Swagger-Doku. Diese Werte brauchen wir in Teil 6 für die Pipecat-Anbindung.
Schritt 6: Routing über mehrere Tools (kurzer Ausblick)
Sobald mehrere Tools registriert sind, entscheidet der Orchestrator anhand des Intents, welches Tool er aufruft. Das ist dann das klassische Router-/Supervisor-Muster. Wie das mit mehreren Agenten als „Tools“ eines übergeordneten Supervisors aussieht, habe ich im Supervisor-Pattern-Beitrag gezeigt. Für den Voice-Loop reicht zunächst der einfache ReAct-Agent aus Schritt 2 bis 3. Das Routing kann man später beliebig ausbauen.
Tipps: Guardrails und Deny-by-default
- Validierte Tool-Calls: Lieber klar abgegrenzte, schema-geprüfte Tools als ein Tool, das „alles“ kann.
- Deny-by-default: Nur explizit freigegebene Tools im
tool_names-Block. Im Zweifel nachfragen lassen statt raten. Bei einem Agenten, der Aktionen auslöst, ist das Pflicht. - Observability: Mit
verbose: truebzw. dem Tracing/Observability-Teil von NAT kannst du nachvollziehen, welche Entscheidung der Agent warum getroffen hat. Das ist wichtig fürs Debugging der späteren Pipeline und auch Dokumentation der Schritte die durchlaufen wurden.
Fazit
Damit steht das Gehirn: ein lokaler NAT-Workflow, der Text entgegennimmt, mit meinem Ollama-LLM denkt, bei Bedarf Tools aufruft und als API-Dienst bereitsteht. Zusammen mit ASR (Parakeet, Canary) und TTS (Magpie) liegen jetzt alle Bausteine lokal vor.
Im nächsten und finalen Teil verbinde ich sie mit NVIDIA Pipecat zu einem durchgängigen, unterbrechbaren Sprach-Loop:
sprechen -> verstehen -> entscheiden -> antworten -> vorlesen.
Danach setze ich optional noch ein Wake-Word als „Türsteher“ davor so wie wir es von den uns umgebenden KI-Services kennen wenn wir diese denn nutzen.
Wenn du NAT schon nutzt: Schreib mir gern in die Kommentare, welches lokale Modell dir die zuverlässigsten Tool-Calls liefert.







{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…