

In Teil 2 habe ich mit Parakeet ein streamingfähiges ASR-NIM für Deutsch als Sprache aufgesetzt und als live Service betreiben mit niedriger Latenz. In diesem Beitrag nehme ich mir das Schwestermodell vor: NVIDIA Canary als NIM. Canary glänzt nicht bei der Latenz, sondern bei der Genauigkeit und es kann etwas, das Parakeet nicht beherrscht: übersetzen. Aus deutschem Audio direkt englischen Text erzeugen, ohne Umweg. Damit runde ich die ASR-Seite meines lokalen Stacks NVIDIA-nativ ab. Wie immer in dieser kleinen Serie gilt: alles lokal, auf eigener Hardware, ohne Cloud.
Was ist NVIDIA Canary?
Canary ist ein Attention-Encoder-Decoder-Modell (FastConformer-Encoder plus Transformer-Decoder), mehrsprachig und multi-task: Es beherrscht in einem einzigen Modell sowohl die Spracherkennung (ASR) als auch die Sprachübersetzung (AST, Automatic Speech Translation). Seine Stärken sind die hohe Genauigkeit und eben die Übersetzung.
Ein wichtiger Unterschied zu Parakeet: Canary läuft ausschließlich im Offline-Modus. Es gibt also kein kontinuierliches Streaming wie bei Parakeet. Canary nimmt die ganze Audiodatei (bzw. den fertig aufgenommenen Puffer) entgegen und liefert danach das Ergebnis. Für einen Live-Voice-Agenten ist das nichts aber für maximale Genauigkeit und für Übersetzung dagegen ideal.
Canary oder Parakeet – wann was?
Kurz zur Einordnung, damit klar ist, wann du welches Modell nimmst:
| Kriterium | Parakeet (Teil 2) | Canary (dieser Teil) |
|---|---|---|
| Modus | Streaming + Offline | nur Offline / Batch |
| Latenz | sehr niedrig (live) | höher (ganze Datei) |
| Stärke | Live-Transkription | Genauigkeit |
| Übersetzung | nein | ja (AST, de↔en) |
| Typischer Einsatz | Voice-Agent, Live-Untertitel | Protokolle, höchste Genauigkeit, Übersetzung |
Das Zielbild dieses Beitrags
Wir betreiben das Canary-NIM lokal und nutzen es dazu eine deutsche Aufnahme direkt ins Englische übersetzen zu lassen.
Voraussetzungen
Wenn du Teil 2 durchlaufen hast, ist die Grundlage bereits vorhanden, und wir referenzieren sie nur kurz:
- NGC-Account und API-Key,
docker loginannvcr.io(siehe Teil 2) - die venv
riva-clientmit installiertemnvidia-riva-client - das geklonte Repository
python-clients - GPU ≥ Compute Capability 8.0 – Canary 1B ist klein, da reicht wenig VRAM locker
Neu installieren musst du also nichts. Wichtig nur: Canary und Parakeet nutzen dieselben Ports (9000/50051). Du kannst daher nicht beide gleichzeitig laufen lassen. Stoppe vor diesem Schritt den Parakeet-Container (Strg + C in seinem Terminal) oder gib Canary über die Ports andere Werte.
Schritt 1: Das Canary-NIM starten
Falls dein API-Key in der aktuellen Terminal-Sitzung nicht mehr gesetzt ist, setze ihn erneut:
Befehl: export NGC_API_KEY="nvapi-xxxxxxxxxxxxxxxxxxxxx"
Dann wählst du Container und Profil. Anders als bei Parakeet (mode=str) gibt es bei Canary nur den Offline-Modus mode=ofl:
Befehl: export CONTAINER_ID=canary-1b
Befehl: export NIM_TAGS_SELECTOR="mode=ofl"
Befehl: docker run -it --rm --name=$CONTAINER_ID --runtime=nvidia --gpus '"device=0"' --shm-size=8GB -e NGC_API_KEY -e NIM_HTTP_API_PORT=9000 -e NIM_GRPC_API_PORT=50051 -p 9000:9000 -p 50051:50051 -e NIM_TAGS_SELECTOR -v ~/.cache/nim:/opt/nim/.cache nvcr.io/nim/nvidia/$CONTAINER_ID:latest
Den Cache-Ordner ~/.cache/nim aus Teil 2 kannst du weiterverwenden. Der erste Start dauert auch hier eine Weile (Modell-Download und TensorRT-Engine-Bau, je nach Netz und GPU bis zu ~30 Minuten). Bereit ist der Dienst, sobald in den Logs die „running“-Zeile bzw. „Application is ready to receive API requests“ erscheint.
Nach dem Absenden des docker run passiert beim allerersten Start einiges nacheinander und genau das scrollt im zugegeben sehr schwarzen Terminal vorbei. Der Reihe nach:
- Image-Download: Docker zieht den Canary-Container aus
nvcr.io(die vielen „Pull complete“-Zeilen). - Profil-Auswahl: Das NIM erkennt meine GPU (RTX 6000 Ada, Compute Capability 8.9) und wählt automatisch das passende Offline-Profil (
mode=ofl, RMIR-Format). - Modell-Download: Es lädt das eigentliche Modell
asr-canary-1b-flash-multi-offline-trtllm.rmir(rund 3,4 GB) in den Cache. - Engine-Bau: Aus dem RMIR baut der Container die optimierten Inferenz-Engines. Bei Canary läuft das über TensorRT-LLM (Encoder als TensorRT-Engine, Decoder über TensorRT-LLM) – das ist der Schritt, der am längsten dauert.
- Serverstart: Riva lädt die Modelle in Triton („…waiting for Triton server…“) und startet dann den gRPC-Server auf Port 50051 und den HTTP-Server auf Port 9000.
Bereit ist der Dienst, sobald die Zeile „Welcome! Application is ready to receive API requests.“ erscheint. Bei mir dauerte der komplette Erststart rund zehn Minuten (Download ~5 Min, Engine-Bau ~5 Min). Beim nächsten Start geht es deutlich schneller, weil das Modell bereits im Cache liegt.
Die vielen Warnungen, die dabei vorbeirauschen (z. B. zu pynvml, transformers/modelopt oder eine übersprungene TRT-Tactic), sind kosmetisch und entscheidend ist allein, dass am Ende die „ready“-Zeile kommt.
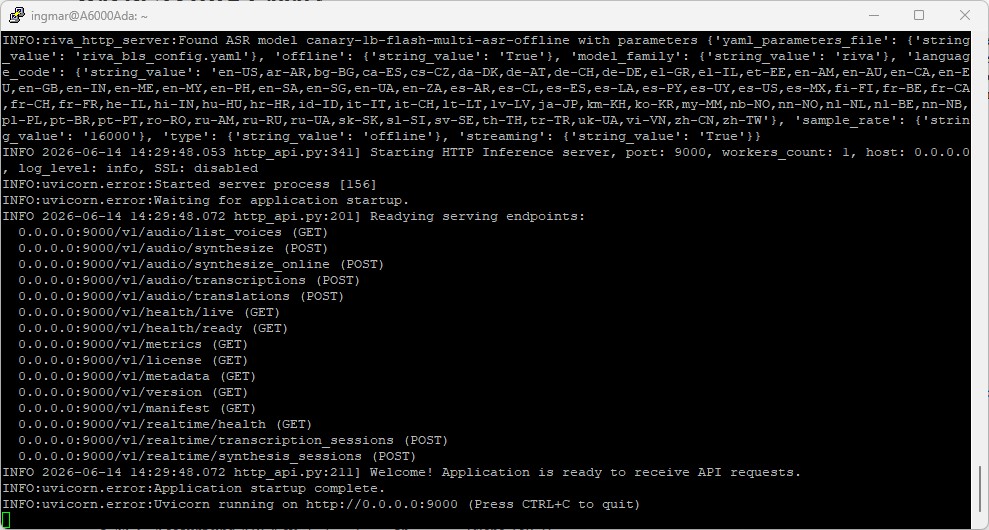
NVIDIA NIM Container Canary setup
Hinweis zu Container-ID und Profil:
Beide Container die wir bis jetzt kennen gelernt haben stammen aus der aktuellen NIM-ASR-Support-Matrix. Sollte NVIDIA das Modell umbenennen oder Profile ändern, findest du die gültigen Werte dort bzw. auf der Modellseite auf build.nvidia.com.
Schritt 2: Container-Status prüfen
In einem zweiten Terminal prüfst du wie gewohnt, ob der Dienst läuft.
Befehl: docker ps
Befehl: curl http://localhost:9000/v1/health/ready
Antwortet der Health-Check mit {"object":"health.response","message":"ready","status":"ready"}(riva-client), steht dein Canary-Microservice.
Schritt 3: Deutsch transkribieren (offline)
Weil Canary offline arbeitet, nutzen wir das Offline-Skript transcribe_file_offline.py also nicht das Streaming-Skript transcribe_file.py aus Teil 2. Zwei Besonderheiten von Canary: Die Eingabesprache muss explizit angegeben werden, und die Punktuation ist standardmäßig aktiv.
Aktiviere zuerst wieder die venv (falls nötig):
Befehl: source ~/venvs/riva-client/bin/activate
Dann transkribierst du deine deutsche WAV (Mono, 16 kHz):
Befehl: python python-clients/scripts/asr/transcribe_file_offline.py --server 0.0.0.0:50051 --language-code de-DE --input-file /home/ingmar/audio/audio.wav
Hinweis zum Sprach-Flag: Je nach Client-Version heißt das Flag --language-code oder --language. Im Zweifel zeigt dir python python-clients/scripts/asr/transcribe_file_offline.py --help die exakten Namen, und --list-models zeigt die geladenen Modelle und Sprachen.
Vergleich zu Parakeet: Jag dieselbe deutsche WAV einmal durch Parakeet (Teil 2) und einmal durch Canary und vergleiche die Transkripte. Bei sauberem Audio liegen beide nah beieinander – bei schwierigem Material (Fachbegriffe, Akzent, Nebengeräusche) liefert Canary in der Regel die sauberere Ausgabe.
Schritt 4: Übersetzen statt nur transkribieren (AST)
Jetzt das, was Canary besonders macht: Übersetzung. Canary übersetzt zwischen den unterstützten Nicht-Englisch-Sprachen und Englisch in beide Richtungen für uns also: deutsche Aufnahme rein, englischer Text raus, direkt und ohne separate Zwischentranskription.
Der bequemste Weg ist die OpenAI-kompatible HTTP-Schnittstelle des NIM. Neben /v1/audio/transcriptions stellt der Dienst auch /v1/audio/translations bereit und Letzteres übersetzt nach Englisch.
Zur Gegenprobe zunächst die reine Transkription über HTTP:
Befehl: curl -s http://0.0.0.0:9000/v1/audio/transcriptions -F language=de-DE -F file="@/home/ingmar/audio/audio.wav"
Und nun die Übersetzung der deutschen Aufnahme ins Englische:
Befehl: curl -s http://0.0.0.0:9000/v1/audio/translations -F language=de-DE -F file="@/home/ingmar/audio/audio.wav"
So bekommst du denselben gesprochenen Inhalt einmal als deutsches Transkript und einmal als englische Übersetzung zurück.
Hier das reine Transkript:
(riva-client) ingmar@A6000Ada:~$ curl -s http://0.0.0.0:9000/v1/audio/transcriptions -F language=de-DE -F file="@/home/ingmar/audio/audio.wav"
{"text":"ein Buch zu schreiben, ist gar nicht so eine leichte Aufgabe. Man muss sich das Thema gut überlegen, sich einen roten Faden ausdenken und die Kapitelstruktur aufsetzen. Dann beginnt die eigentliche Arbeit, die einzelnen Kapitel mit spannenden Inhalten zu befüllen, die den Leser auch wirklich mitreissen. Auf dem Weg durch das Abenteuer, durch die Geschichte, durch die Bastelanleitung oder auch super spannend und wichtig. Und ich finde dadurch, dass wenn ich Bücher schreibe, lerne ich auch für mich selbst sehr viel dazu. ","language_code":"de-DE"}Hier die Übersetzung:
(riva-client) ingmar@A6000Ada:~$ curl -s http://0.0.0.0:9000/v1/audio/translations -F language=de-DE -F file="@/home/ingmar/audio/audio.wav"
{"text":"Writing a book is not an easy task. You have to think about the subject, think about a red thread and put up the chapter structure. Then the actual work begins to fill the individual chapters with exciting content that really carry the reader along. I find that when I write books, I learn a lot about it for myself. ","language_code":"de-DE"}
(riva-client) ingmar@A6000Ada:~$
Ich spare mir hier ein Bild des Terminal-Fensters hier einzufügen da es so von der Ausgabe als Text viel besser zu lesen ist.
Tipps und Troubleshooting
- Port-Konflikt mit Parakeet: Beide NIMs belegen 9000/50051. Stoppe das jeweils andere Modell, bevor du dieses startest – oder weise im
docker runandere Ports zu. - Offline heißt höhere Latenz: Das Ergebnis kommt erst, nachdem die komplette Datei verarbeitet wurde. Das ist erwartetes Verhalten, kein Fehler.
- Eingabesprache ist Pflicht: Canary braucht die Quellsprache explizit (z. B.
de-DE). Ohne Angabe gibt es eine Fehlermeldung. - Audioformat: Mono, 16 kHz (WAV, OPUS oder FLAC). Die häufigste Fehlerquelle – im Zweifel vorher mit ffmpeg konvertieren.
- Falsches Flag: Wird ein Flag nicht erkannt, hilft
--helpdes jeweiligen Skripts mit den exakten Namen. - VRAM: Canary 1B ist klein; mit
nvidia-smiprüfst du die Belegung der GPU.
Fazit
Mit Parakeet (Streaming, Teil 2) und Canary (Genauigkeit plus Übersetzung, dieser Teil) ist die ASR-Seite meines Stacks NVIDIA-nativ abgedeckt: live und offline, Transkription und Übersetzung und alles lokal auf eigener Hardware. Die beiden Modelle ergänzen sich perfekt, statt sich zu ersetzen.
Im nächsten Teil kommt die Gegenrichtung: die Sprachausgabe über das deutsche Magpie-TTS-NIM. Danach habe ich ASR und TTS als NVIDIA-Microservices beisammen. Das bildet die Grundlage, um sie mit dem Orchestrator (NeMo Agent Toolkit) und Pipecat Stück für Stück zum vollständigen lokalen Sprach-Agenten zu verbinden.
Wenn du das Setup nachbaust: Schreib mir gern in die Kommentare, wie groß bei dir der Genauigkeits- und Qualitätsunterschied zwischen Parakeet und Canary auf deinem Audiomaterial ausfällt.







{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…