

Wer mit Large Language Models experimentiert, kennt das Problem: Die lokale Hardware reicht oft nicht aus, um größere Modelle flüssig laufen zu lassen. Für mich war die Lösung klar: Ich nutze einen Gigabyte AI TOP ATOM mit seiner mächtigen Blackwell-GPU als dedizierten Ollama-Server im Netzwerk. So können alle Computer in meinem lokalen Netzwerk auf die Ollama API zugreifen und die volle GPU-Power nutzen ohne dass jeder einzelne Rechner die Modelle lokal installieren muss. Für meine Erfahrungsbericht hier auf meinem Blog habe ich den Gigabyte AI TOP ATOM von der Firma MIFCOM ausgeliehen bekommen.
In diesem Beitrag zeige ich euch, wie ich Ollama auf meinem Gigabyte AI TOP ATOM installiert und so konfiguriert habe, dass Ollama im gesamten Netzwerk erreichbar ist. Da das System auf der gleichen Plattform wie die NVIDIA DGX Spark basiert, funktionieren die offiziellen NVIDIA Playbooks hier genauso zuverlässig. Das Beste daran: Die Installation ist in 10-15 Minuten erledigt und komplett im Netzwerk nutzbar.
GIGABYTE AI TOP ATOM – OLLAMA logo
Die Grundidee: Zentraler Ollama-Server für das gesamte Netzwerk
Bevor ich in die technischen Details einsteige, ein wichtiger Punkt: Mit dieser Konfiguration läuft Ollama direkt auf dem Gigabyte AI TOP ATOM und nutzt die volle GPU-Performance der Blackwell-Architektur. Ich konfiguriere Ollama so, dass es auf allen Netzwerk-Interfaces lauscht und den Port 11434 im lokalen Netzwerk exponiert. So können alle Computer in meinem Netzwerk – ob Laptop, Desktop oder andere Geräte – direkt auf die Ollama API zugreifen und die Modelle nutzen, ohne dass jeder Rechner die Modelle lokal installieren muss was ja auch häufig von den Hardwarenaforderungen die so ein OpenSource LLM stellt nicht möglich ist.
Das ist besonders praktisch für Teams oder wenn ihr mehrere PC in eurem Haushalt oder eurer kleinen Firma im Eisnatz habt. Das Ziel ist es einen zentralen Server mit der vollen GPU-Power, auf den alle zugreifen können im eigenen Netzwerk aufzubauen. Da ich persönlich den größten Nutzen bei lokal betriebenen LLMs sehe lege ich damit auch als erstes los. Natürlich solltet ihr bei diesem Setup sicherstellen, dass euer Netzwerk vertrauenswürdig ist, da die Ollama API ohne Authentifizierung erreichbar ist. Für ein privates Heimnetzwerk oder ein kleines geschütztes Firmennetzwerk ist das aber dennoch eine perfekte Lösung für den Einstieg.
Was ihr dafür braucht:
-
Einen Gigabyte AI TOP ATOM, ASUS Ascent, MSI EdgeXpert (oder NVIDIA DGX Spark) der mit dem Netzwerk verbunden ist
-
Einen angeschlossenen Monitor oder Terminal-Zugriff auf den AI TOP ATOM
-
Einen Computer im gleichen Netzwerk für API-Tests
-
Grundkenntnisse in Terminal-Befehlen und cURL (für die API-Tests)
-
Die IP-Adresse eures AI TOP ATOM im Netzwerk (findet ihr mit
ip addroderhostname -I)
Phase 1: Installation von Ollama auf dem Gigabyte AI TOP ATOM
Ich gehe jetzt bei meiner weiteren Anleitung davon aus, dass ihr direkt vor dem AI TOP ATOM sitzt und einen Monitor, Keyboard und Maus angeschlossen habt. Zuerst prüfe ich, ob CUDA und eventuell auch shcon Ollama bereits installiert ist. Dazu öffne ich ein Terminal auf meinem AI TOP ATOM und führe die beiden folgenden Befehle einmal aus.
Der nachfolgende Befehl zeigt euch ob das CUDA Toolkit bereits installiert ist.
Befehl: nvidia-smi
Ihr solltet jetzt die folgende Sicht im Terminal fenster sehen.
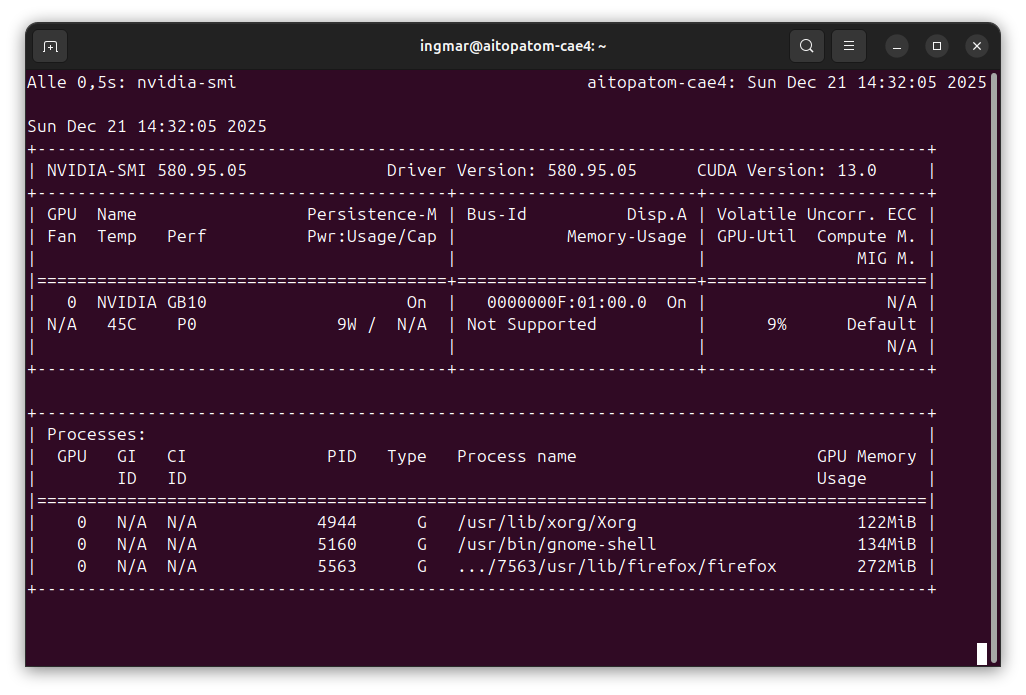
GIGABYTE AI TOP ATOM – NVIDIA-SMI
Mit diesem Befehl könnt ich prüfen ob eventuell ollama schon installiert ist.
Befehl: ollama --version
Wenn ihr eine Versionsnummer bei dem Ollama Befehl seht, könnt ihr direkt zu Phase 3 springen. Falls der Befehl „command not found“ zurückgibt, müsst ihr Ollama erst noch auf eurem System installieren.
Die Installation ist denkbar einfach. Ich nutze das offizielle Installationsskript von Ollama:
Befehl: curl -fsSL https://ollama.com/install.sh | sh
Das Skript lädt die neueste Version herunter und installiert sowohl das Ollama-Binary als auch die Service-Komponenten. Das schöne hierbei ist, dass Ollama extra für die NVIDIA Platform bereitgestellt wurde. Also der Befehl sowohl für die X86er-Welt als auch für die ARM-Welt der gleich ist. Ich warte einfach, bis die Installation abgeschlossen ist – das dauert meist nur wenige Minuten. Die Ausgabe zeigt euch dann, dass alles erfolgreich installiert wurde.
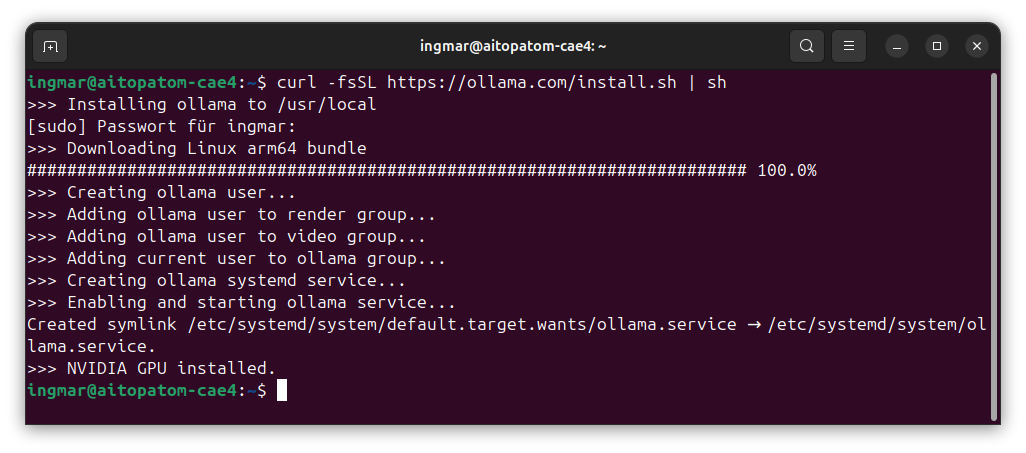
GIGABYTE AI TOP ATOM – Ollama installation
Phase 2: Das erste Sprachmodell herunterladen
Nach der Installation lade ich mir ein Sprachmodell herunter. Für die Blackwell-GPU auf dem AI TOP ATOM empfehle ich Qwen2.5 32B, da dieses Modell speziell für die Blackwell-Architektur optimiert ist und die GPU-Performance voll ausnutzt. Der jetzt folgende Befehl lädt das Modell herunter und stellt es im Anschluss in Ollama selber bereit.
Befehl: ollama pull qwen2.5:32b
Auch solltet ihr euch die drei folgenden Modelle installieren da ich diese sehr gut finde.
Befehl: ollama pull nemotron-3-nano
Befehl: ollama pull qwen3-vl
Befehl: ollama pull gpt-oss:120b
Je nach Internetgeschwindigkeit kann der Download der Modelle ein paar Minuten dauern. Die Modelle sind unterschiedlich groß und haben bei mir ca. XXX GB an Speicher belegt. Ihr seht einen Fortschrittsbalken während des Downloads. Wenn alles erfolgreich war, sollte die Ausgabe etwa so aussehen:
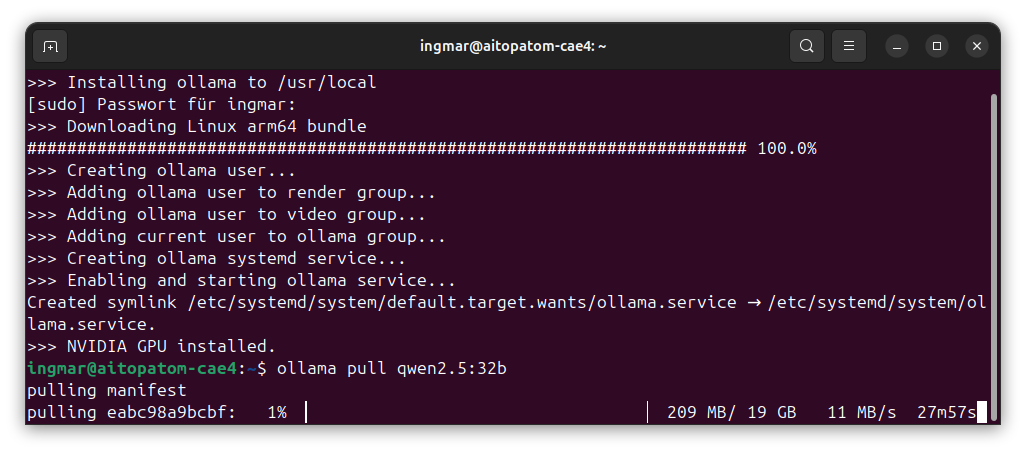
GIGABYTE AI TOP ATOM – Ollama pull qwen 2.5
Wichtiger Hinweis: Stellt sicher, dass genug Speicherplatz auf eurem AI TOP ATOM verfügbar ist. Falls der Download mit einem Speicherfehler abbricht, könnt ihr auch kleinere Modelle wie qwen2.5:7b verwenden, die deutlich weniger Platz benötigen.
Um alle herunter geladenen Modelle sich auflisten zu lassen steht euch folgender Befehl zur Verfügung:
Befehl: ollama list
Hier wie bei mir jetzt die Übersicht der von Ollama bereitgestellten Sprachenmodelle aussieht.
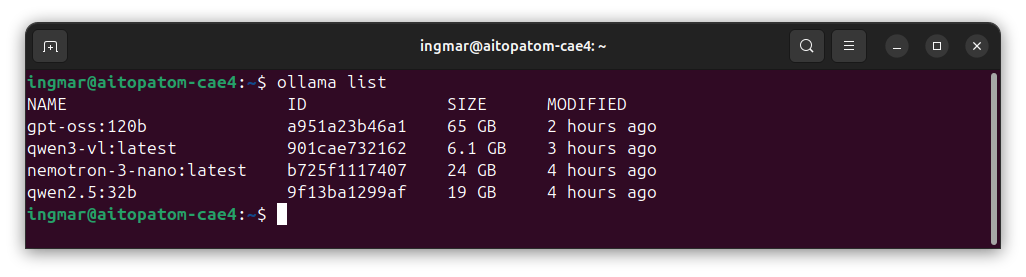
GIGABYTE AI TOP ATOM – Ollama list
Phase 3: Ollama für Netzwerk-Zugriff konfigurieren
Jetzt kommt der entscheidende Schritt: Ich konfiguriere Ollama so, dass es im gesamten Netzwerk erreichbar ist. Standardmäßig lauscht Ollama nur auf localhost, was bedeutet, dass nur Anfragen vom AI TOP ATOM selbst also der IP-Adresse 127.0.0.1 akzeptiert werden. Um den Zugriff aus dem gesamten Netzwerk also auch von anderen IP-Adressen zu ermöglichen, muss die Umgebungsvariable OLLAMA_HOST gesetzt werden.
Zuerst prüfe ich die aktuelle IP-Adresse meines AI TOP ATOM im Netzwerk:
Befehl: hostname -I
Oder alternativ:
Befehl: ip addr show | grep "inet "
Ich notiere mir die IP-Adresse (z.B. 192.168.2.100). Jetzt konfiguriere ich Ollama, damit es auf allen Netzwerk-Interfaces des Rechners lauscht. Dazu bearbeite ich die Systemd-Service-Datei:
Befehl: sudo systemctl edit ollama
Dieser Befehl öffnet einen Editor. Ich füge folgende Konfiguration ein:
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
Die Konfiguration sollte jetzt wie im folgenden Bild gezeigt aussehen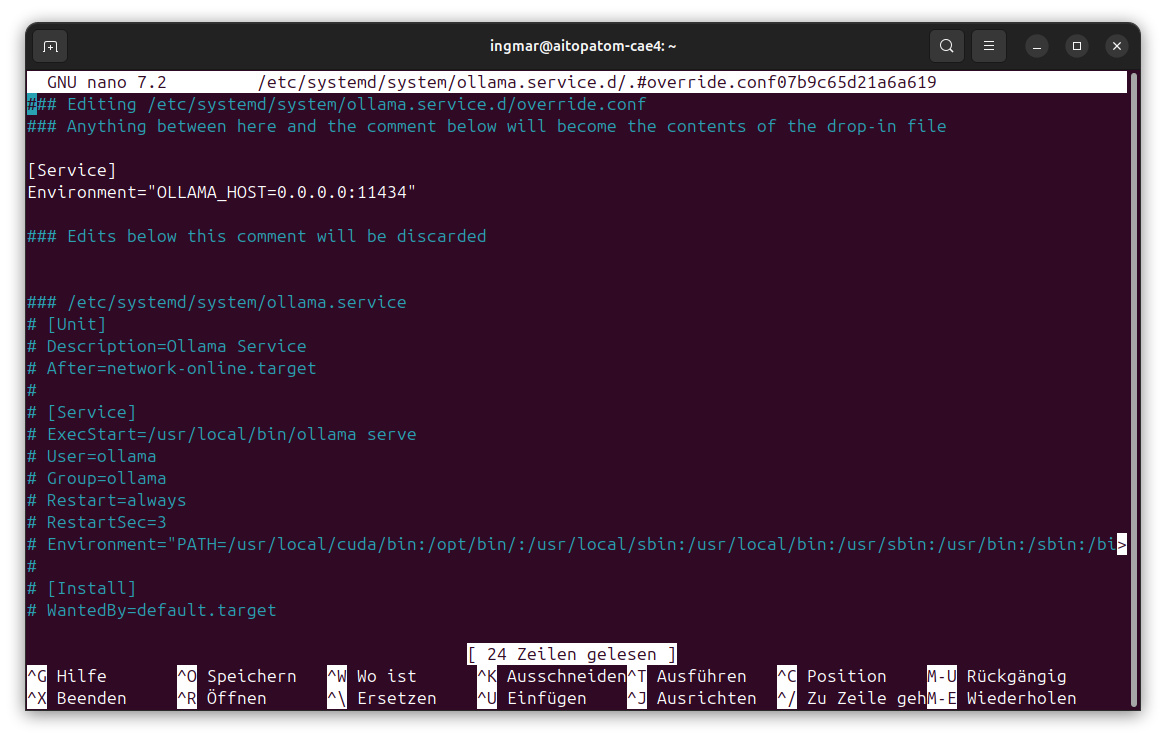
GIGABYTE AI TOP ATOM – Ollama network-access
Die Konfiguration OLLAMA_HOST=0.0.0.0:11434 bedeutet, dass Ollama auf allen Netzwerk-Interfaces auf Port 11434 lauscht. Ich speichere die Datei und starte den Ollama-Service neu:
Befehl: sudo systemctl daemon-reload
Befehl: sudo systemctl restart ollama
Um zu prüfen, ob Ollama jetzt im Netzwerk erreichbar ist, teste ich von einem anderen Computer im Netzwerk im Browser folgende URL aus:
Befehl: http://<IP-Adresse-AI-TOP-ATOM>:11434/api/tags
Ersetzt dabei <IP-Adresse-AI-TOP-ATOM> mit der IP-Adresse eures AI TOP ATOM. Wenn ihr eine Liste der verfügbaren Modelle zurückbekommt, funktioniert die Netzwerk-Konfiguration korrekt.
Phase 4: API-Zugriff aus dem Netzwerk testen
Jetzt kann ich von jedem Computer in meinem Netzwerk aus auf die Ollama API zugreifen. Um zu testen, ob alles funktioniert, führe ich von einem anderen Rechner im Netzwerk folgenden Befehl aus (wieder mit eurer IP-Adresse des Rechners auf dem Ollama läuft):
curl http://192.168.2.100:11434/api/chat -d '{
"model": "qwen2.5:32b",
"messages": [{
"role": "user",
"content": "Schreibe mir ein Haiku über GPUs und KI."
}],
"stream": false
}'Wenn alles korrekt konfiguriert ist, sollte ich eine JSON-Antwort zurückbekommen, die etwa so aussieht:
curl http://192.168.2.100:11434/api/chat -d '{
"model": "qwen2.5:32b",
"created_at": "2024-01-15T12:30:45.123Z",
"message": {
"role": "assistant",
"content": "Silizium fließt durch Schaltkreise\nTräume werden Realität\nKI erwacht zum Leben"
},
"done": true
}'Falls ihr eine Fehlermeldung wie „Connection refused“ bekommt, prüft folgendes:
-
Ist die IP-Adresse korrekt? Prüft mit
hostname -Iauf dem AI TOP ATOM -
Läuft Ollama? Prüft mit
sudo systemctl status ollama -
Ist die Firewall aktiv? Falls ja, müsst ihr Port 11434 freigeben:
sudo ufw allow 11434 -
Sind beide Computer im gleichen Netzwerk?
Phase 5: Weitere API-Endpunkte testen
Um sicherzustellen, dass alles vollständig funktioniert, teste ich noch weitere API-Funktionen. Zuerst liste ich alle verfügbaren Modelle auf (wieder mit eurer IP-Adresse):
Befehl: curl http://192.168.2.100:11434/api/tags
Das sollte mir alle heruntergeladenen Modelle anzeigen. Dann teste ich noch das Streaming, was besonders bei längeren Antworten nützlich ist:
curl -N http://192.168.1.100:11434/api/chat -d '{
"model": "qwen2.5:32b",
"messages": [{"role": "user", "content": "Warum sieht der Himmel wenn keine Wolken zu sehen sind blau aus?"}],
"stream": true
}'Mit stream: true seht ihr die Antwort in Echtzeit, während sie generiert wird. Das ist besonders praktisch, wenn ihr längere Texte generiert und nicht warten wollt, bis alles fertig ist.
Weitere Modelle ausprobieren
Das Schöne an Ollama ist die große Auswahl an verfügbaren Modellen. Nach der erfolgreichen Installation könnt ihr euch weitere Modelle aus der Ollama Library herunterladen. Ich habe zum Beispiel auch folgende Modelle getestet:
Befehl:ollama pull llama3.1:8b
Befehl:ollama pull codellama:13b
Befehl:ollama pull phi3.5:3.8b
Jedes Modell hat seine Stärken: Llama3.1 ist sehr vielseitig, CodeLlama brilliert bei Code-Generierung und Phi3.5 ist kompakt und schnell. Probiert einfach aus, welches Modell am besten zu euren Anforderungen passt. Das ist ja jetzt genau das schöne an dem Setup.
Troubleshooting: Häufige Probleme und Lösungen
In meiner Zeit mit Ollama auf dem AI TOP ATOM bin ich auf einige typische Probleme gestoßen. Hier sind die häufigsten und wie ich sie gelöst habe:
-
„Connection refused“ beim Zugriff aus dem Netzwerk: Prüft, ob Ollama auf allen Interfaces lauscht (
sudo systemctl status ollamazeigt die Umgebungsvariablen). Falls nicht, die Service-Konfiguration prüfen und Ollama neu starten. -
Firewall blockiert den Zugriff: Port 11434 muss in der Firewall freigegeben sein. Mit
sudo ufw allow 11434oder entsprechenden iptables-Regeln öffnen. -
Modell-Download schlägt mit Speicherfehler fehl: Nicht genug Speicherplatz auf dem AI TOP ATOM. Entweder Speicher freigeben oder ein kleineres Modell wie
qwen2.5:7bverwenden. -
Ollama-Befehl wird nach Installation nicht gefunden: Der Installationspfad ist nicht im PATH. Terminal-Session neu starten oder
source ~/.bashrcausführen bzw. den Rechner neustarten. -
API gibt „model not found“ Fehler zurück: Das Modell wurde nicht heruntergeladen oder der Name ist falsch. Mit
ollama listalle verfügbaren Modelle anzeigen. -
Langsame Inferenz auf dem AI TOP ATOM: Das Modell ist zu groß für den GPU-Speicher. Entweder ein kleineres Modell verwenden oder mit
nvidia-smiden GPU-Speicher prüfen.
Rollback: Netzwerk-Zugriff wieder deaktivieren
Falls ihr Ollama wieder nur lokal verfügbar machen möchtet (nur von localhost), entfernt die Service-Override-Datei:
Befehl: sudo rm /etc/systemd/system/ollama.service.d/override.conf
Befehl: sudo systemctl daemon-reload
Befehl: sudo systemctl restart ollama
Ollama läuft dann wieder nur auf localhost und ist nicht mehr aus dem Netzwerk erreichbar.
Rollback: Ollama wieder löschen
Falls ihr Ollama komplett vom AI TOP ATOM deinstallieren möchtet, führt auf dem System folgende Befehle aus:
Befehl: sudo systemctl stop ollama
Befehl:sudo systemctl disable ollama
Befehl:sudo rm /usr/local/bin/ollama
Befehl:sudo rm -rf /usr/share/ollama
Befehl:sudo userdel ollama
Wichtiger Hinweis: Diese Befehle entfernen alle Ollama-Dateien und auch alle heruntergeladenen Modelle. Stellt sicher, dass ihr wirklich alles entfernen möchtet, bevor ihr diese Befehle ausführt.
Zusammenfassung & Fazit
Die Installation von Ollama auf dem Gigabyte AI TOP ATOM ist dank der Kompatibilität mit den NVIDIA DGX Spark Playbooks erstaunlich unkompliziert. In weniger als 15 Minuten habe ich einen voll funktionsfähigen Ollama-Server laufen, der im gesamten Netzwerk erreichbar ist.
Was mich besonders begeistert: Die Performance der Blackwell-GPU wird voll ausgenutzt, und alle Computer in meinem Netzwerk können jetzt auf die gleiche GPU-Power zugreifen. Das ist besonders praktisch für Teams oder wenn ihr mehrere Geräte habt – jeder kann die Modelle nutzen, ohne sie lokal installieren zu müssen.
Besonders praktisch finde ich auch, dass ich die GPU- und System-Auslastung während der Inferenz über das DGX Dashboard überwachen kann. So sehe ich immer genau, wie die Ressourcen genutzt werden, wenn mehrere Clients gleichzeitig auf den Server zugreifen.
Für alle, die tiefer einsteigen möchten: Die Ollama API lässt sich problemlos in eigene Anwendungen integrieren. Egal ob Python, JavaScript oder eine andere Sprache – die REST API ist universell einsetzbar. Ich nutze sie zum Beispiel für automatisierte Textgenerierung, Code-Assistenz und sogar für Chatbots.
Falls ihr Fragen habt oder auf Probleme stoßt, schaut gerne in die offizielle NVIDIA DGX Spark Dokumentation oder in die Ollama Dokumentation. Die Community ist sehr hilfsbereit, und die meisten Probleme lassen sich schnell lösen.
Nächster Schritt: Open WebUI für eine benutzerfreundliche Chat-Oberfläche
Ihr habt jetzt Ollama erfolgreich installiert und im Netzwerk exponiert. Die API funktioniert, aber für viele Nutzer ist eine grafische Benutzeroberfläche deutlich praktischer als API-Aufrufe über cURL. Im nächsten Blogpost zeige ich euch, wie ihr Open WebUI auf eurem Gigabyte AI TOP ATOM installiert und konfiguriert.
Open WebUI ist eine selbst gehostete, erweiterbare KI-Oberfläche, die vollständig offline funktioniert. Zusammen mit Ollama habt ihr dann eine komplette Chat-Lösung für euer Netzwerk ähnlich wie ChatGPT, aber lokal gehostet und mit eurer eigenen GPU-Power. Die Installation erfolgt über Docker und ist so hoffe ich genauso unkompliziert wie die Ollama-Installation. Ihr könnt dann von jedem Computer im Netzwerk über den Browser auf eine schöne Chat-Oberfläche zugreifen, Modelle auswählen und direkt mit den LLMs chatten. Das tolle dabei ist, dass es in Open WebUI eine Benutzerverwaltung gibt. So könnt sind die Chat-Verläufe der einzelnen Nutzer voneinander getrennt und wenn ich es richtig in Erinnerung habe könnt ihr auch Teams anlegen um wieder in Gruppen auf die gleichen Chat-Verläufe und hochgeladenen Dokumente zugreifen zu können.
Bleibt gespannt auf den nächsten Beitrag – ich zeige euch auch in diesem wieder Schritt für Schritt, wie ihr Open WebUI einrichtet und mit eurem bereits laufenden Ollama-Server verbindet!
Viel Erfolg beim Experimentieren mit Ollama auf eurem Gigabyte AI TOP ATOM. Ich bin gespannt, welche Anwendungen ihr damit entwickelt! Last es mich und meine Leser hier in den Kommentaren wissen.








{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…