
Alle Bausteine liegen jetzt lokal vor: ASR (Parakeet, Canary), TTS (Magpie), ein LLM über meinen Ollama-Server und der Orchestrator (NAT, Teil 5). Jetzt verbinde ich sie zu einem durchgängigen, unterbrechbaren Sprach-Loop. Das wird mein erster kleine lokale Voice-Agent. Mein Zielbild ist eine Art General-Agent: Ich spreche, er versteht, erledigt Dinge und antwortet mir in natürlicher Sprache. Die Dinge die er erledigt werden erst einmal klein sein aber es geht ja auch um das Prinzip wie es überhaupt funktioniert.
In diesem Teil baue ich nach Pfad A: Das LLM hängt direkt im Loop (mein Ollama-Server), damit wir zuerst einen sauber laufenden Voice-to-Voice-Loop bekommen. Das „echte Gehirn“ also der NAT-Agenten mit Tool-Calling (Zeitansage & Co.) den wir bereits in Teil 5 kennen gelernt haben hänge ich in Teil 7 ein. Das Wake-Word folgt in Teil 8.
NVIDIA NIM Voice Assistant Web Frontend
Was ist NVIDIA Pipecat?
Um den Loop zu verstehen, lohnt sich ein Blick auf die zwei Ebenen, die hier zusammenkommen.
Pipecat ist ein quelloffenes Framework für echtzeitfähige Sprach- und Multimodal-Agenten. Sein Kern ist eine Pipeline-Architektur: Audio und Text fließen als kleine „Frames“ durch eine Kette von Stufen (Eingang → ASR → LLM → TTS → Ausgang). Genau die kniffligen Echtzeit-Themen, die man sonst mühsam selbst bauen müsste, nimmt Pipecat einem ab. Das kontinuierliche Streamen der Audio-Chunks, die Turn-Detection (wann habe ich zu Ende gesprochen?) und die Unterbrechbarkeit (dem Agenten ins Wort fallen). Das Framework ist bewusst anbieter-neutral; man kann offene, kommerzielle oder eigene Modelle einhängen.
NVIDIA Pipecat ist die NVIDIA-native Erweiterung davon und Teil des ACE-Controller-Projekts. Sie bringt fertige Bausteine für genau die Modelle mit, die ich in dieser Serie lokal betreibe:
- Riva-ASR-Service: spricht meine Spracherkennung an (Parakeet bzw. Canary).
- Riva-TTS-Service: spricht meine Sprachausgabe an (Magpie).
- LLM-Service: bindet ein LLM als „Denk“-Stufe ein; bei mir mein Ollama-Server über die OpenAI-kompatible Schnittstelle.
Dazu kommen NVIDIA-spezifische Helfer wie den FastAPI-WebSocket-Transport (ein WebSocket-basierter Audio-Transport inklusive kleiner Browser-Test-UI), das Synchronisieren der Transkripte mit der Audio-Wiedergabe und Latenz-Optimierungen wie Speculative Speech Processing, das schon mit der Verarbeitung beginnt, während ich noch spreche.
Der entscheidende Punkt für meinen souveränen Ansatz: Die Riva-Services zeigen per Default zwar auf die NVIDIA-Cloud, lassen sich aber genauso auf lokale Endpunkte richten. Damit wird Pipecat zum Bindeglied, das aus meinen einzelnen, lokal laufenden NIMs einen echten, zusammenhängenden Dialog macht. Bei dieser lokalen Konfiguration ist dann auch wieder sicher gestellt, das kein einziges Audio-Paket meine Maschine also mein Netzwerk verlässt.
Die Architektur im Überblick
[Diagramm: Mikrofon (Browser) → ASR (Parakeet-NIM) → LLM (Ollama) → TTS (Magpie-NIM) → Lautsprecher, mit Rückkopplung und Unterbrechbarkeit. Hier die Architektur-Grafik einbauen.]
Der Loop selbst ist eine Pipeline in dieser Reihenfolge:
transport.input() → STT → context.user() → LLM → TTS → transport.output() → context.assistant()Voraussetzungen
- Das Parakeet-ASR-NIM (Teil 2) und das Magpie-TTS-NIM (Teil 4) müssen jetzt gleichzeitig laufen.
- Mein Ollama-Server (auf der zweiten Maschine) als LLM-Backend.
- Eine Python-3.12-venv – nvidia-pipecat verlangt Python 3.12 (also eine eigene Umgebung, getrennt von den 3.11-venvs der anderen Teile).
- Ein Browser zum Testen (Mikrofon-Zugriff), wie schon bei der Gradio-Demo in Teil 1.
Schritt 1: nvidia-pipecat installieren
nvidia-pipecat verlangt ausdrücklich Python 3.12 und leider nicht neuer was ein kleines Problem darstellt auf meinem Ubuntu-Server. Das ist auf aktuellen Distributionen ein Stolperstein: Ubuntu 25.10 etwa bringt nur noch Python 3.13 (und 3.14) mit, und ein python3.12 -m venv quittiert das prompt mit Command 'python3.12' not found. Die neueren Versionen würde ich hier nicht erzwingen, weil einige Abhängigkeiten (Pipecat selbst, die ONNX-/Silero-Komponenten für die VAD usw.) für 3.13/3.14 oft noch keine fertigen Wheels haben und wir uns so hoffentlich eventuelle Probleme aus dem Weg gehen können. Nehmen wir eine aktuelle Python-Version endet der Build vermutlich mit Fehlern. Wir brauchen also gezielt ein Python 3.12 zumindest zu dem Zeitpunkt als ich diesen Artikel verfasst habe war das mein Weg.
Prüfe zuerst, ob du es überhaupt hast:
Befehl: python3.12 --version
Fall A – Python 3.12 ist vorhanden. Dann reicht die klassische venv:
Befehl: python3.12 -m venv ~/venvs/pipecat
Befehl: source ~/venvs/pipecat/bin/activate
Befehl: pip install --upgrade pip setuptools wheel
Fall B – Python 3.12 fehlt (z. B. auf Ubuntu 25.10). Hier ist uv der sauberste Weg: Das Tool holt sich ein isoliertes Python 3.12 selbst – ganz ohne sudo und ohne dein System-Python anzufassen.
Zuerst uv installieren (falls noch nicht vorhanden) und auf den PATH bringen:
Befehl: curl -LsSf https://astral.sh/uv/install.sh | sh
Befehl: source $HOME/.local/bin/env
Dann die venv mit Python 3.12 anlegen (uv lädt 3.12 bei Bedarf automatisch herunter) und aktivieren:
Befehl: uv venv --python 3.12 ~/venvs/pipecat
Befehl: source ~/venvs/pipecat/bin/activate
Hinweis: In einer uv-venv installierst du Pakete mit uv pip install … statt mit pip install ….
Jetzt das Paket installieren: Je nachdem, welchen Weg du genommen hast musst Du dich jetzt wieder für A oder B entscheiden. Bei mir ist es nach wie vor die B-Variante:
Befehl (Fall A): pip install nvidia-pipecat
Befehl (Fall B): uv pip install nvidia-pipecat
Gut zu wissen die wichtigen Extras kommen schon mit:
Ein Blick in die Installationsausgabe zeigt, dass nvidia-pipecat (bei mir war es die Version 0.4.0 auf Basis von pipecat-ai 0.0.98) die Bausteine, die wir gleich brauchen, bereits als Abhängigkeiten mitzieht: onnxruntime (Laufzeit für die Silero-VAD), aiortc samt pipecat-ai-small-webrtc-prebuilt (WebRTC-Transport inklusive fertigem Browser-Client), nvidia-riva-client (ASR/TTS) und openai (für die OpenAI-kompatible LLM-Anbindung an Ollama). Du musst hier also voraussichtlich nichts nachinstallieren. Sollte beim ersten Lauf doch ein ModuleNotFoundError auftauchen, installierst du gezielt das passende Extra nach, z. B. uv pip install "pipecat-ai[silero]".
Schritt 2: Beide NIMs gleichzeitig starten und dabei auf die Ports achten
Bis hierher haben wir die NIMs immer einzeln betrieben. Für den Loop ist das anders: ASR und TTS müssen jetzt gleichzeitig laufen und während der ganzen Sitzung gestartet bleiben. Jedes NIM ist ein eigener Vordergrund-Container, also starten wir sie in zwei getrennten Terminals (ein drittes Terminal nutzen wir später für den Pipecat-Bot).
Und ja hier müssen wir auf die Ports aufpassen.
Beide NIMs wollen standardmäßig die Ports 9000 (HTTP) und 50051 (gRPC). Würden wir beide so starten, gäbe es einen Port-Konflikt und der zweite Container käme gar nicht erst hoch. Die Lösung: Parakeet bleibt auf den Standard-Ports, Magpie biegen wir auf 9001/50052 um. Wichtig zum Merken: Die gRPC-Ports (50051 für ASR, 50052 für TTS) sind genau die Adressen, auf die wir die Pipecat-Services in Schritt 3 zeigen lassen.
Öffne jetzt zwei Terminal-Fenster zu Deinem Applikations-Server.
Hinweis: In einem frisch geöffneten Terminal ist der API-Key meist nicht mehr gesetzt. Daher sollten wir jetzt jeweils vorher den folgenden bekannten Befehl ausführen (wie in Teil 2).
Befehl: export NGC_API_KEY="nvapi-xxxxxxxxxxxxxxxxxxxxx"
Terminal 1 – Parakeet (ASR) auf den Standard-Ports 9000/50051:
Befehl: docker run -it --rm --name=parakeet-1-1b-rnnt-multilingual --runtime=nvidia --gpus '"device=0"' --shm-size=8GB -e NGC_API_KEY -e NIM_HTTP_API_PORT=9000 -e NIM_GRPC_API_PORT=50051 -p 9000:9000 -p 50051:50051 -e NIM_TAGS_SELECTOR="mode=str" -v ~/.cache/nim:/opt/nim/.cache nvcr.io/nim/nvidia/parakeet-1-1b-rnnt-multilingual:latest
Terminal 2 – Magpie (TTS), umgebogen auf 9001/50052. Wichtig: Ich erzwinge hier gezielt batch_size=8 – warum, steht gleich in der VRAM-Box darunter.
Befehl: docker run -it --rm --name=magpie-tts-multilingual --runtime=nvidia --gpus '"device=0"' --shm-size=8GB -e NGC_API_KEY -e NIM_HTTP_API_PORT=9001 -e NIM_GRPC_API_PORT=50052 -p 9001:9001 -p 50052:50052 -e NIM_TAGS_SELECTOR="name=magpie-tts-multilingual,batch_size=8" -v ~/.cache/nim:/opt/nim/.cache nvcr.io/nim/nvidia/magpie-tts-multilingual:latest
Beide Container bleiben laufen soll heißen Du darfst die beiden Terminal-Fenster nicht schließen. Das ist nicht ideal aber später wenn alles läuft können wir die Container auch automatisch im Hintergrund starten wenn wir das möchten. In einem dritten Terminal kurz prüfen, dass beide Dienste activ sind und funktionieren also sagen wir mal gesund sind. Dabei müssen wir jetzt wieder auf die unterschiedlichen Ports achten.
Befehl: curl http://localhost:9000/v1/health/ready (ASR, Parakeet)
Als Ergbnis habe ich folgendes zurück erhalten und damit die Bestätigung das der Container und Service läuft.
{"object":"health.response","message":"ready","status":"ready"}
Befehl: curl http://localhost:9001/v1/health/ready (TTS, Magpie)
Auch hier habe ich ein positives Ergbnis zurück erhalten und damit die Bestätigung das der Container und Service läuft.
{"object":"health.response","message":"ready","status":"ready"}
Hinweis: VRAM und warum batch_size=8: Anders als in Teil 4, wo Magpie allein lief, teilen sich jetzt ASR und TTS dieselbe GPU (und falls auf der Karte noch weitere Dienste laufen, erst recht). Der Profil-Selektor griff bei mir zunächst zum großen Profil batch_size=32 . Das hat bei mir rund 31 GB VRAM belegt, während batch_size=8 mit ~11 GB auskommt. Zusammen mit Parakeet (und allem anderen) lief die 48-GB-Karte damit voll, und der Container brach beim Laden ab. Im Log sah das so aus:
[TRT] [E] Error Code 2: OutOfMemory (Requested size was 10786262016 bytes.)
... Failed to create an execution context!
> Triton server died before reaching ready state.
Deshalb hänge ich oben im NIM_TAGS_SELECTOR gezielt batch_size=8 an. Prüfe vorher mit nvidia-smi, wie viel VRAM noch frei ist. Laufen dort noch andere GPU-Dienste, stoppe sie für die Loop-Session oder gib ihnen eine andere Karte.
Hinweis: Den Modell-Build persistieren (kein 28-Minuten-Rebuild mehr):
Dir ist sicher aufgefallen, dass Magpie beim Start den TensorRT-Codec-Decoder mehrere Minuten lang baut. Das liegt daran, dass Magpie als RMIR-Modell ausgeliefert wird und es für die Ada-GPU keine fertige Engine zum Download gibt (im Log steht model_type: rmir). Der gemountete ~/.cache/nim spart nur den Download, nicht den Build. Die fertige Engine landet im container-internen /data/models und wird mit --rm jedes Mal verworfen. NVIDIA löst das über einen einmaligen Export: Engine einmal bauen, in einen gemounteten Ordner schreiben und bei späteren Starts von dort laden.
Schritt A
Die fertige Engine einmalig exportieren (der Container baut die Engine, schreibt sie in den Export-Ordner und beendet sich):
Befehl: export NIM_EXPORT_PATH=~/nim_export
Befehl: mkdir -p $NIM_EXPORT_PATH && chmod 777 $NIM_EXPORT_PATH
Einen Port müssen wir jetzt bei diesem Befehl nicht mit angeben. Denn der Container wird gebaut, nach dem Bau sofort exportiert und anschließend direkt beendet wenn der Export abgeschlossen ist.
Befehl: docker run -it --rm --name=magpie-tts-multilingual --runtime=nvidia --gpus '"device=0"' --shm-size=8GB -e NGC_API_KEY -e NIM_TAGS_SELECTOR="name=magpie-tts-multilingual,batch_size=8" -v ~/.cache/nim:/opt/nim/.cache -v $NIM_EXPORT_PATH:/opt/nim/export -e NIM_EXPORT_PATH=/opt/nim/export nvcr.io/nim/nvidia/magpie-tts-multilingual:latest
Jetzt sollte im Pfad ~/nim_export eine Datei mit dem Namen tts-MagpieTTS_21hz_codec_trtllm_Multilingual.tar.gz liegen. Um das zu prüfen bitte einmal den folgenden Befehl ausführen.
Befehl: ls ~/nim_export
In dieser Datei ist dann das erstellte modell enthalten. Jetzt bitte wie im Schritt B beschrieben dieses Modell laden.
Schritt B
Die fertige Engine aus dem persistenten Speicher laden: Bei den folgenden Starts mountest du denselben Export-Ordner und setzt zusätzlich NIM_DISABLE_MODEL_DOWNLOAD=true. Der Container überspringt dann sowohl den Download als auch den Neubau und ist in Sekunden statt Minuten bereit.
Die exakten Flags und Pfade für deine NIM-Version nimmst du am besten aus NVIDIAs Doku „Model Caching for Speech NIM Containers“. Dort ist der Export-Workflow für RMIR-Modelle Schritt für Schritt beschrieben.
Bei mir sah der Befehl wie folgt aus.
Befehl: docker run -it --rm --name=magpie-tts-multilingual --runtime=nvidia --gpus '"device=0"' --shm-size=8GB -e NGC_API_KEY -e NIM_TAGS_SELECTOR="name=magpie-tts-multilingual,batch_size=8" -e NIM_DISABLE_MODEL_DOWNLOAD=true -e NIM_HTTP_API_PORT=9001 -e NIM_GRPC_API_PORT=50052 -p 9001:9001 -p 50052:50052 -v ~/.cache/nim:/opt/nim/.cache -v $NIM_EXPORT_PATH:/opt/nim/export -e NIM_EXPORT_PATH=/opt/nim/export nvcr.io/nim/nvidia/magpie-tts-multilingual:latest
Hinweis: Bitte daran denken wenn es zu einem Fehler kommt wie docker: invalid spec: :/opt/nim/export: empty section between colons, dass die beiden Variablen gesetzt sind nach einem Neustart des Servers:
Befehl: export NGC_API_KEY="nvapi-xxxxxxxxxxxxxxxxxxxxx"
Befehl: export NIM_EXPORT_PATH=~/nim_export
Befehl: curl http://localhost:9001/v1/health/ready (TTS, Magpie)
Auch hier habe ich ein positives Ergbnis zurück erhalten und damit die Bestätigung das der Container und Service läuft.
{"object":"health.response","message":"ready","status":"ready"}
Mit dem folgenden Befehl kannst Du Dir eine Liste aller im Modell vorhandenen Stimmen und ihre Sprachen ausgeben lassen.
Befehl: curl http://localhost:9001/v1/audio/list_voices
Für die Deutsche Sprachen stehen die folgenden Stimmen zur Verfügung und diese sind dann für den Abschnitt 4 interessant denn dort werden diese hinterlegt.
# Mia (weiblich)
Magpie-Multilingual.DE-DE.Mia
Magpie-Multilingual.DE-DE.Mia.Neutral
Magpie-Multilingual.DE-DE.Mia.Calm
Magpie-Multilingual.DE-DE.Mia.Angry
Magpie-Multilingual.DE-DE.Mia.Happy
Magpie-Multilingual.DE-DE.Mia.Sad# Sofia (weiblich)
Magpie-Multilingual.DE-DE.Sofia
Magpie-Multilingual.DE-DE.Sofia.Neutral
Magpie-Multilingual.DE-DE.Sofia.Calm
Magpie-Multilingual.DE-DE.Sofia.Angry
Magpie-Multilingual.DE-DE.Sofia.Happy
Magpie-Multilingual.DE-DE.Sofia.Fearful# Pascal (männlich)
Magpie-Multilingual.DE-DE.Pascal
Magpie-Multilingual.DE-DE.Pascal.Neutral
Magpie-Multilingual.DE-DE.Pascal.Calm
Magpie-Multilingual.DE-DE.Pascal.Angry
Magpie-Multilingual.DE-DE.Pascal.Happy
Magpie-Multilingual.DE-DE.Pascal.Disgust
Magpie-Multilingual.DE-DE.Pascal.Sad# Diego (männlich)
Magpie-Multilingual.DE-DE.Diego
Magpie-Multilingual.DE-DE.Diego.Neutral
Magpie-Multilingual.DE-DE.Diego.Calm
Magpie-Multilingual.DE-DE.Diego.Angry
Magpie-Multilingual.DE-DE.Diego.Happy
Magpie-Multilingual.DE-DE.Diego.PleasantSurprised
Magpie-Multilingual.DE-DE.Diego.Disgust
Schritt 3: Das offizielle nvidia-pipecat-Beispiel als Grundgerüst holen
Statt die FastAPI- und Runner-Mechanik von Hand zu bauen, nehmen wir das offizielle „speech-to-speech“-Beispiel von NVIDIA als Basis. Es bringt den ACETransport, den Pipeline-Runner und eine kleine Web-Test-UI bereits mit. Das Beste an dieser Lösung ist: ASR, LLM und TTS lassen sich komplett über Umgebungsvariablen umstellen, ohne den Python-Code anzufassen.
Befehl: git clone https://github.com/NVIDIA/voice-agent-examples.git
Befehl: cd ~/voice-agent-examples/examples/voice_agent_websocket
Das Beispiel bringt seine eigene, uv-verwaltete Umgebung mit. Wir legen sie an und installieren die Abhängigkeiten – ab hier arbeiten wir in dieser Projekt-venv (die venv aus Schritt 1 diente vor allem dazu, Python 3.12 und die Installation zu prüfen):
Befehl: uv venv
Befehl: source .venv/bin/activate
Befehl: uv sync
Wichtig: Das Beispiel kann per docker compose auch eigene ASR-/TTS-/LLM-Container hochfahren. Das wollen wir hier aber nicht. Unsere NIMs (Schritt 2) und der Ollama-Server laufen ja schon. Wir gehen deshalb den reinen Python-Weg und zeigen das Beispiel über die .env einfach auf unsere bereits laufenden Dienste.
Schritt 4: Auf lokal, Ollama und Deutsch konfigurieren (.env)
Jetzt kommt der Clou: Wir kopieren die Beispiel-Umgebungsdatei und richten sie auf unsere lokalen Dienste und auf Deutsch aus.
Befehl: cp env.example .env
Befehl: nano .env
Die mitgelieferte env.example zeigt standardmäßig auf die NVIDIA-Cloud und steht auf Englisch. Wir biegen sie auf unsere lokalen NIM-gRPC-Ports (denk an die Umbiegung von Magpie auf 50052 aus Schritt 2) und auf den Ollama-Server um. So sieht meine .env aus:
NVIDIA_API_KEY=dummy
ENABLE_SPECULATIVE_SPEECH=true
CHAT_HISTORY_LIMIT=20
# ASR – lokales Parakeet-NIM (Standard-gRPC-Port aus Schritt 2)
ASR_SERVER_URL=localhost:50051
ASR_LANGUAGE=de-DE
# ASR_MODEL_NAME leer lassen = Standardmodell des lokalen NIMs (Details im Hinweis unten)
ASR_MODEL_NAME=
# TTS – lokales Magpie-NIM (in Schritt 2 auf 50052 umgebogen)
TTS_SERVER_URL=localhost:50052
TTS_LANGUAGE=de-DE
TTS_VOICE_ID=Magpie-Multilingual.DE-DE.Mia.Calm
TTS_MODEL_NAME=magpie_tts_ensemble-Magpie-Multilingual
# LLM – mein Ollama-Server (OpenAI-kompatibel)
NVIDIA_LLM_URL=http://<OLLAMA-IP>:11434/v1
NVIDIA_LLM_MODEL=<dein-ollama-modell> # z. B. qwen3:8bEin paar Worte dazu, warum genau diese Werte:
- NVIDIA_API_KEY=dummy: Für die lokalen Dienste wird der Key nicht gebraucht. Der OpenAI-kompatible Client für Ollama besteht aber auf einem nicht-leeren Wert, daher der Platzhalter.
- ASR_SERVER_URL / TTS_SERVER_URL: zeigen auf die gRPC-Ports unserer beiden NIMs (50051 für Parakeet, 50052 für Magpie). In der
env.examplesind diese Zeilen auskommentiert – wir aktivieren sie und tragen unsere lokalen Adressen ein. - ASR_LANGUAGE / TTS_LANGUAGE / TTS_VOICE_ID: Diese drei stehen nicht in der
env.example, werden von derbot.pyaber ausgewertet (sonst greift der Default en-US bzw. die Stimme „Aria“). Wir ergänzen sie also von Hand, um auf Deutsch und die Magpie-Stimme aus Teil 4 umzustellen. - TTS_MODEL_NAME: ist bereits der Default und passt exakt zu unserem Magpie-Export (
magpie_tts_ensemble-Magpie-Multilingual) – hier ist nichts zu tun.
Hinweis zu ASR_MODEL_NAME: Der Default im Beispiel (parakeet-1.1b-en-US-asr-streaming-silero-vad-sortformer) ist ein englisches Modell mit einem anderen Namen, als ihn unser lokales parakeet-1-1b-rnnt-multilingual ausliefert. Den exakten Namen verrät dir der Parakeet-Container beim Start: Suche in seinem Log nach der Zeile Successfully registered: <name> for ASR und trage diesen <name> ein. Wer es schnell will, lässt ASR_MODEL_NAME= leer – dann nutzt der lokale Endpunkt sein Standardmodell.
Wichtig: die Zeile nicht auskommentieren denn ein auskommentiertes ASR_MODEL_NAME lässt die bot.py auf den englischen Default zurückfallen.
Den System-Prompt – die Rolle des General-Assistenten – setzt du direkt in der bot.py, dort wo die messages mit der system-Rolle definiert sind. Ich ersetze den englischen Default durch:
messages = [
{
"role": "system",
"content": "Du bist ein hilfsbereiter Sprachassistent der in allen Lebenslagen des Benutzers von Dir bereitwillig hilft."
"Antworte freundlich, höflich und in höchstens einem kurzen Satz auf Deutsch."
"Keine Aufzählungen oder Listen.",
},
]Ein paar Zeilen tiefer steht im on_client_connected-Handler die Begrüßung, mit der der Bot das Gespräch eröffnet. Die biege ich ebenfalls auf Deutsch um, sonst stellt er sich unter Umständen auf Englisch vor:
messages.append({"role": "system", "content": "Bitte stell dich dem Nutzer kurz auf Deutsch vor."})Schritt 5: Den Voice-Loop starten und im Browser testen
Jetzt läuft alles zusammen. Bevor du den Bot startest, vergewissere dich, dass die beiden NIMs aus Schritt 2 noch laufen – durch den einmaligen Export oder geschlossene Terminals kann es sein, dass sie zwischendurch gestoppt wurden. Falls nötig, starte sie neu:
- Parakeet (ASR) wie in Schritt 2 (Ports 9000/50051).
- Magpie (TTS) über den schnellen Schritt-B-Befehl (lädt die exportierte Engine, Ports 9001/50052) – kein Neubau mehr.
Kurz gegenprüfen, dass beide gesund sind:
Befehl: curl http://localhost:9000/v1/health/ready
Befehl: curl http://localhost:9001/v1/health/ready
Melden beide ready, startest du in einem dritten Terminal – im Projektordner und mit aktiver Projekt-venv – den Bot:
Befehl: cd ~/voice-agent-examples/examples/voice_agent_websocket
Befehl: source .venv/bin/activate
Befehl: python bot.py
Das hostet die kleine Test-UI zusammen mit dem Voice-Agent-Server. Am Ende sollte Uvicorn auf 0.0.0.0:8100 lauschen. Im Browser öffnest du dann:
URL: http://<SERVER-IP>:8100/static/index.html
Mikrofon-Zugriff ohne HTTPS: Da mein A6000-Ada-Server headless ist und keine HTTPS-Verschlüsselung hat, lässt der Browser das Mikrofon zunächst nicht zu. Bei mir hat der SSH-Tunnel zuverlässig funktioniert:
Befehl: ssh -L 8100:localhost:8100 ingmar@192.168.2.119
Danach rufst du http://localhost:8100/static/index.html auf – über localhost erlaubt der Browser das Mikrofon. (Alternativ in Chrome unter chrome://flags/ die Adresse http://<SERVER-IP>:8100 unter „Insecure origins treated as secure“ eintragen.)
In der Oberfläche klickst du auf Start Audio – und der Loop steht: Ich spreche einen deutschen Satz, Parakeet transkribiert, das Ollama-LLM antwortet, und Magpie liest die Antwort mit der Stimme Mia vor. Komplett auf Deutsch und auf eigener Hardware.
[Platzhalter: ein, zwei eigene Beispielsätze und die gesprochene Antwort beschreiben; Screenshot der Oberfläche einbauen.]
Hinweis Port: Willst du den Port ändern, passt du ihn in der uvicorn.run-Zeile in der bot.py und im wsUrl in static/index.html an.
Schritt 6: Turn-Detection, Unterbrechbarkeit und Speculative Speech
Dass sich das Ganze wie ein Gespräch und nicht wie ein Walkie-Talkie anfühlt, steckt in drei Mechanismen und das Schöne ist: Alle drei sind im Beispiel schon eingebaut und werden über die .env bzw. die bot.py gesteuert, ohne dass man die Pipeline selbst umbauen muss.
1. Unterbrechbarkeit. In der bot.py ist die Pipeline mit allow_interruptions=True konfiguriert. Dadurch kann ich dem Agenten ins Wort fallen – er stoppt die Ausgabe und hört wieder zu. Gerade im Auto-Szenario ist das wichtig: Man will korrigieren können, ohne das Ende der Antwort abzuwarten.
2. Turn-Detection über das VAD-Profil. Wann habe ich zu Ende gesprochen? Das steuert die Umgebungsvariable VAD_PROFILE in der bot.py:
- ASR (Default): Die Nemotron-ASR liefert die Sprech-Ende- und Interruption-Signale gleich selbst mit – ein separater VAD ist nicht nötig.
- Silero: Mit
VAD_PROFILE=Silerobekommt der WebSocket-Transport stattdessen einenSileroVADAnalyzervorgeschaltet.
3. Speculative Speech Processing. Schon in Schritt 4 über ENABLE_SPECULATIVE_SPEECH=true aktiviert. Statt auf das finale Transkript zu warten, arbeitet der Agent bereits auf den frühen, vorläufigen ASR-Transkripten – das drückt die Antwortlatenz spürbar. Das funktioniert nur mit der Nemotron-ASR und wird im Beispiel automatisch zugeschaltet; ein Code-Edit ist nicht nötig.
Schritt 7: Die Latenzkette messen
Damit sich das Gespräch natürlich anfühlt, zählt die Gesamtlatenz vom Ende meiner Äußerung bis zum ersten Ton der Antwort. Die gute Nachricht: Pipecat misst diese Werte für jede Stufe bereits selbst und wir müssen hier nichts selber entwerfen oder programmieren. Pipecat schreibt sie nur standardmäßig nicht raus und daher sehen wir im Terminal keine Messungen. Die Messwerte fließen als kleine MetricsFrames durch die Pipeline und werden am Ende einfach verworfen, solange ihnen niemand zuhört bzw. diese abgreift. Wir müssen also zwei Dinge tun: die Metriken einschalten und einen Observer anhängen, der sie ins Log schreibt.
Metriken aktivieren und mitloggen. Pipecat bringt dafür einen fertigen MetricsLogObserver mit. Du musst also wie eingangs geschrieben nichts selbst bauen. Such in der bot.py die Stelle, an der das PipelineTask erzeugt wird, und ergänze die beiden Metrik-Schalter sowie den Observer.
Die nachfolgende import Zeile ganz oben bei den Importen des Python-Programmes bitte einfügen:
from pipecat.observers.loggers.metrics_log_observer import MetricsLogObserverDie nachfolgende Anpassung bitte in "task = PipelineTask(..." vornhemen.
task = PipelineTask(
pipeline,
params=PipelineParams(
allow_interruptions=True,
enable_metrics=True,
enable_usage_metrics=True,
send_initial_empty_metrics=True,
report_only_initial_ttfb=True,
start_metadata={"stream_id": stream_id},
),
observers=[MetricsLogObserver()],
)
Jetzt bitte die Anpassungen an dem Pyhton-Programm speichern.
Was du danach im Log siehst. Sobald du den Bot neu startest und einen Satz sprichst, erscheinen pro Gesprächsrunde Zeilen wie diese (mit den Service-Namen aus unserem lokalen Setup):
NvidiaLLMService#0 TTFB: 0.837
NemotronTTSService#0 TTFB: 0.171
NemotronTTSService#0 processing time: 0.0005
Die Werte sind in Sekunden angegeben. So ordnest du sie meinen drei Stufen zu:
- ASR (Parakeet): die
processing timedesNemotronASRService– grob die Zeit bis zum finalen Transkript. - LLM (Ollama) – TTFT: der
TTFB-Wert desNvidiaLLMService– vom fertigen Transkript bis zum ersten Token meines Ollama-Modells. - TTS (Magpie) – TTFA: der
TTFB-Wert desNemotronTTSService– vom ersten LLM-Text bis zum ersten Audio-Sample.
Die ungefähre Voice-to-Voice-Latenz ist dann die Summe aus ASR + LLM-TTFB + TTS-TTFB – plus die Netzwerk-Hops, die bei mir durch den separaten Ollama-Server auf der zweiten Maschine dazukommen.
Die Kür: die echte End-to-End-Zeit messen. Wer „vom Ende meiner Äußerung bis zum ersten Ton“ als eine einzige Zahl will, hängt sich an die Frames, die die Turn-Grenzen markieren: VADUserStoppedSpeakingFrame (ich bin fertig – Uhr starten) und BotStartedSpeakingFrame (der Bot fängt an zu sprechen – Uhr stoppen). Ein kompakter eigener Observer reicht dafür:
import time
from loguru import logger
from pipecat.observers.base_observer import BaseObserver, FramePushed
from pipecat.frames.frames import VADUserStoppedSpeakingFrame, BotStartedSpeakingFrame
class VoiceLatencyObserver(BaseObserver):
def __init__(self):
super().__init__()
self._t_user_stopped = None
async def on_push_frame(self, data: FramePushed) -> None:
frame = data.frame
if isinstance(frame, VADUserStoppedSpeakingFrame):
self._t_user_stopped = time.time()
elif isinstance(frame, BotStartedSpeakingFrame) and self._t_user_stopped:
ms = (time.time() - self._t_user_stopped) * 1000
logger.info(f"Voice-to-Voice-Latenz: {ms:.0f} ms")
self._t_user_stopped = NoneDen hängst du einfach zusätzlich in die observers=[...]-Liste:
observers=[MetricsLogObserver(), VoiceLatencyObserver()],Hinweis: Mit VAD_PROFILE=ASR (unser Default) liefert die Nemotron-ASR die Sprech-Ende-Signale selbst – je nach Pipecat-Version kann der Start-Frame dann leicht anders heißen. Der MetricsLogObserver funktioniert in jedem Fall, deshalb ist er der verlässliche Einstieg; den eigenen Observer nimm als Sahnehäubchen.
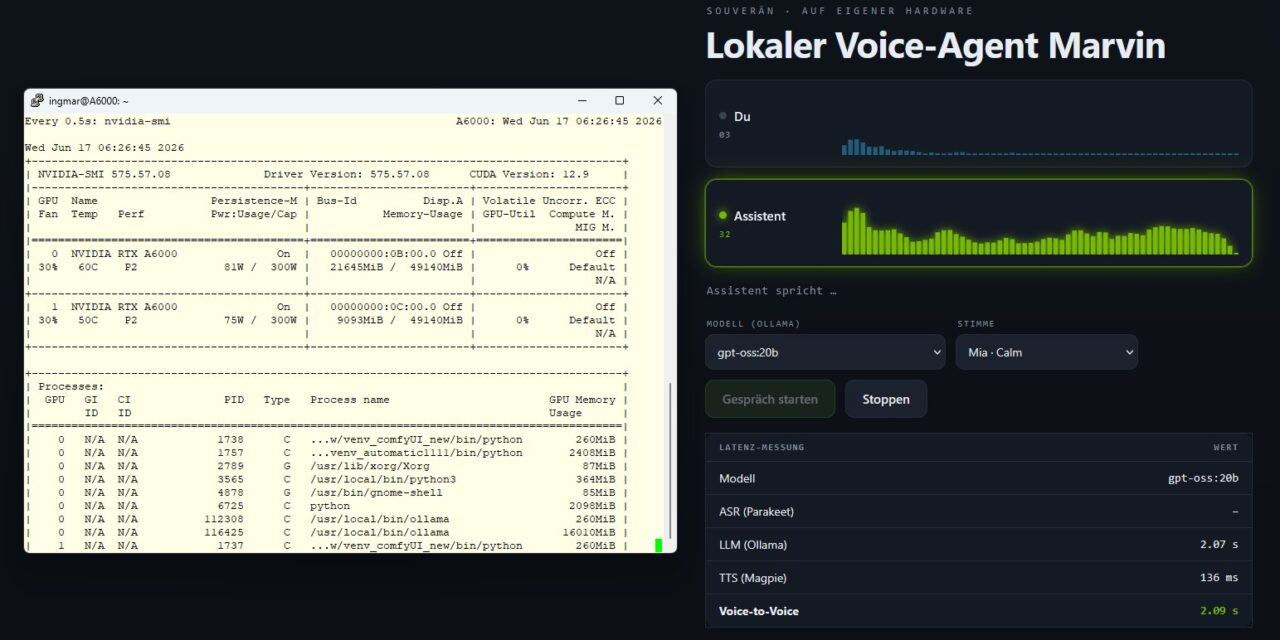
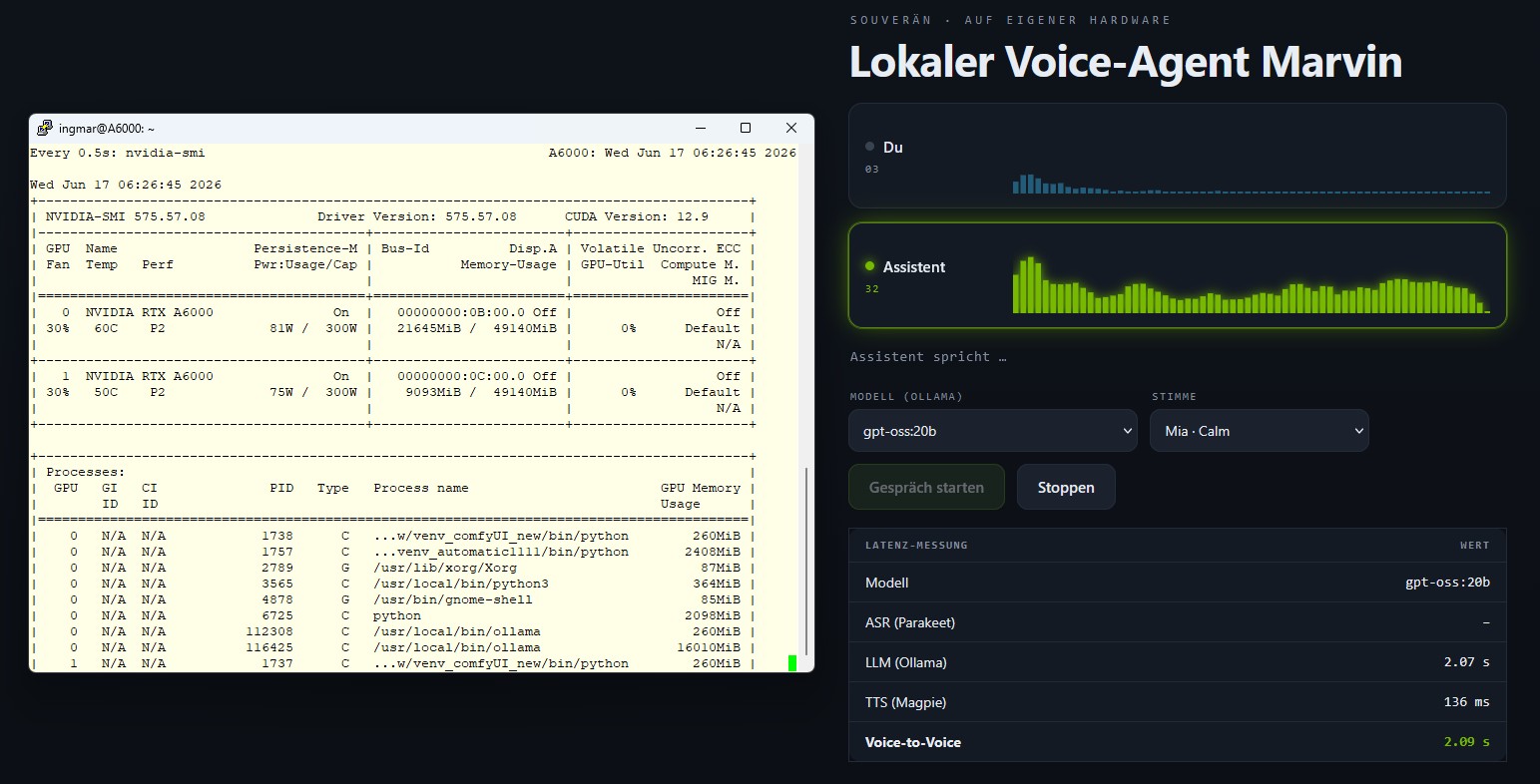
Meine Messwerte. So sah die Latenzkette bei meinem ersten Durchlauf aus. Meinen Assistenten gefragt habe ich „Kannst du mir sagen, wie du dich heute fühlst?“, als LLM lief das große gemma4:26b auf dem separaten em Dual RTX A6000 Inferenz Ollama-Server, ASR (Parakeet) und TTS (Magpie) auf der RTX A6000 Ada:
| Stufe | Gemessen wird | Mein Wert (gemma4:26b) |
|---|---|---|
| ASR (Parakeet) | Compute-Latenz bis zum finalen Transkript | ≈ 32 ms |
| LLM (Ollama) | bis zum ersten fertigen Satz (das gibt TTS frei) | ≈ 7,05 s |
| TTS (Magpie) | Time-to-First-Audio (TTFB) | ≈ 73 ms |
| Voice-to-Voice (gesamt) | Ende der Äußerung → erster Ton | ≈ 7,1 s |
Die Zahlen sprechen eine klare Sprache: ASR und TTS sind mit zusammen rund 100 ms praktisch geschenkt. Aber die komplette Latenz steckt im LLM. Bei mir lief das große gemma4:26b, und es hat für meine kurze Frage satte 423 Completion-Tokens erzeugt, obwohl der System-Prompt nur einen kurzen Satz verlangt. Dazu kommt eine Feinheit der Pipeline: Die TTS-Stufe wartet nicht auf das erste Token, sondern auf den ersten vollständigen Satz. Ein schnelles erstes Token (meine Begrüßung kam in 0,49 s) hilft also wenig, wenn das Modell vor dem ersten Satzende erst lange ausholt.
Ein Wort zum oft vermuteten „Modell-Laden“: Ja, beim allerersten Aufruf zieht Ollama das Modell in den VRAM, das kann einmalig Zeit kosten. In meiner Messung war das Modell aber bereits warm und die Begrüßung kam ja schon in 0,49 s. Die sieben Sekunden stammen hier also fast vollständig aus der reinen Generierung eines so großen Modells, nicht aus dem Laden.
Die Konsequenz ist eindeutig: Für ein flüssiges Gespräch ist ein 26B-Modell an dieser Stelle schlicht zu schwer. Wer die Zielmarke von grob unter ~700–800 ms erreichen will, nimmt fürs Reasoning im Loop ein kleineres, schnelleres Modell. Genau dafür ist das Modell-Dropdown aus meiner aufgewerteten Oberfläche praktisch: einmal auf ein 7–8B-Instruct-Modell umstellen, denselben Satz sprechen und die Latenz fällt deutlich. Spannend ist hier auch die Zwei-Maschinen-Aufteilung: Das LLM auf dem separaten Ollama-Server entlastet die GPU der A6000 Ada (auf der ASR und TTS laufen), kostet aber einen Netzwerk-Hop. Erst das Messen zeigt schwarz auf weiß, dass dieser Hop hier völlig nebensächlich ist denn der Flaschenhals ist allein die Modellgröße.
NVIDIA NIM Voice Assistant web frontend inference server
Tipps und Troubleshooting
- Port-Konflikt: Der häufigste Stolperstein – ASR und TTS wollen beide 9000/50051. Genau dafür haben wir Magpie auf 9001/50052 umgebogen (Schritt 2).
- Sample-Rates zwischen den Stufen: Durchgängig 16 kHz Mono halten; Unstimmigkeiten zwischen ASR-Ausgabe und TTS-Eingabe sind eine typische Fehlerquelle.
- Zwei Maschinen: Das LLM läuft separat – Netzwerk-Latenz und Erreichbarkeit der
base_urlprüfen. - Python 3.12: nvidia-pipecat läuft nicht in den 3.11-venvs der anderen Teile – eigene Umgebung nutzen.
- Service-Umbenennung ab nvidia-pipecat 0.4.0: Wer eigenen Pipeline-Code schreibt, importiert
NemotronASRServicebzw.NemotronTTSService(ausnvidia_pipecat.services.riva_speech). Die alten NamenRivaASRService/RivaTTSServicefunktionieren nur noch als veraltete Aliase mit Warnung. - Stimm-Name exakt: Den deutschen Magpie-
voice_idgenau wie aus--list-voicesübernehmen.
Fazit
Damit steht der erste vollständige lokale Voice-Loop: Ich spreche, Parakeet transkribiert, mein Ollama-LLM antwortet, Magpie spricht. So habe ich das komplette Setup durchgängig auf meiner eigenen Hardware, unterbrechbar, auf Deutsch umgesetzt. Das Grundgerüst meines Agenten lebt.
Noch „denkt“ der Agent aber nur frei drauflos. Im nächsten Teil ersetze ich das nackte LLM durch den NAT-Agenten aus Teil 5 (Pfad B). Das ist noch einmal ein großer Schritt für das Setup, denn dann kann der Agent echte Aktionen auslösen, etwa die Zeitansage umsetzen, und wird vom Gesprächspartner zum Assistenten. In Teil 8 kommt schließlich das Wake-Word als Türsteher davdor.
Wenn du den Loop nachbaust: Schreib mir gern in die Kommentare, welche Gesamtlatenz du auf deiner Hardware erreichst.








{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…