

In meinen letzten Beiträgen habe ich den Inferenz-Layer (Ollama, TensorRT-LLM) und den Orchestrator-Layer (NeMo Agent Toolkit) auf meinem Applikations-Server in Kombination mit meinem KI-Server aufgebaut. Was bisher gefehlt hat, ist eine sinnvolle Brücke zwischen diesen Server-Schichten und der Welt der Embedded-Geräte in meiner Werkstatt. Das war der Moment, an dem ich mir das Model Context Protocol (MCP) genauer angeschaut habe. Die Idee von mir ist, dass mein erster eigener MCP-Server etwas sein soll, das ich tatsächlich gebrauchen kann: GPU-Monitoring für meine beiden RTX A6000 Karten in meinem Inferenz-Server.
Konkret: Ich will von ganz verschiedenen Geräten wie z. B. meinem ESP-Claw mit LED-Ring wissen, wie ausgelastet meine GPUs gerade sind. Kein Grafana, kein Cloud-Service, sondern ein schlanker, lokal laufender MCP-Standard-Server, der genau die Metriken ausgibt, die ich brauche. Und am Ende soll mein ESP-Claw-basiertes Setup das per MCP-Client abfragen können. Ich bin gespannt ob das klappt und was ich wieder alles lernen werde.
In diesem Beitrag zeige ich Dir, wie ich den MCP-Server gebaut habe. Er wird in Python geschrieben, ich werde pynvml für die GPU-Auslatung verwenden und FastMCP, inklusive Multi-GPU-Unterstützung, EMA-Glättung für eine ruhigere Anzeige und einer optionalen Einrichtung als systemd-Service. damit der MCP-Server immer im Hintergrund läuft.
Wenn die kleinen Programme fertig sind werde ich diese im Text auf mein GitHub Repository verlinken.
Worum geht es eigentlich?
Bevor wir loslegen, kurz die Architektur, damit klar ist, was ich erreichen möchte:
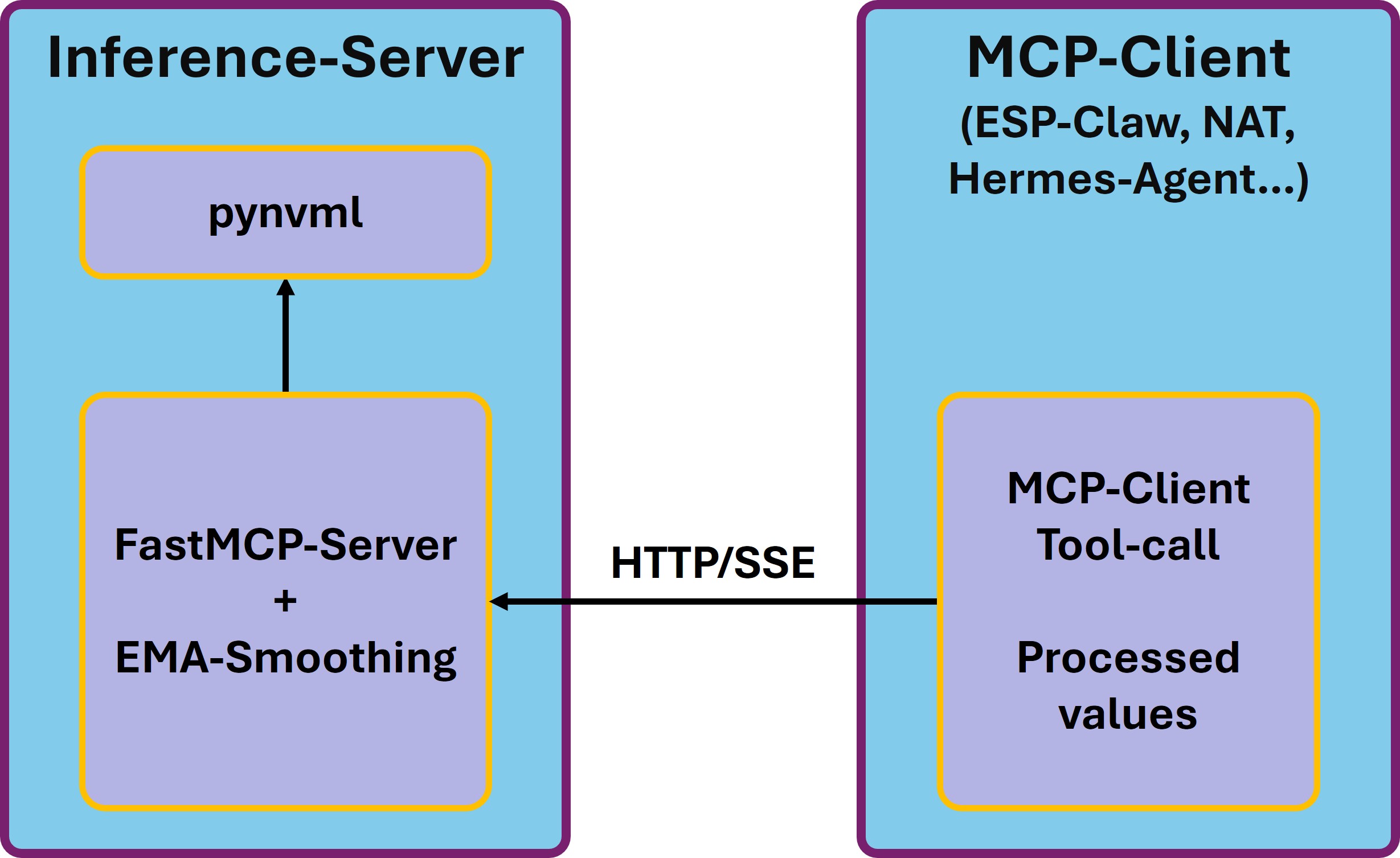
MCP Server – GPU load
Ein MCP-Server stellt Tools bereit, die ein MCP-Client über ein Standard-Protokoll aufrufen kann. Das Schöne: Solange der Client MCP spricht und das tun mittlerweile ziemlich viele ist es egal, was am anderen Ende dran ist. Mein Server wird also nicht nur für den ESP-Claw nützlich sein, sondern auch für meinen Hermes-Agent, das NeMo Agent Toolkit, jeden LangChain-Agent mit MCP-Anbindung oder eigene Python-Skripte. So können diese Clients nachsehen was gerade auf dem Inferenz-Server für eine Last anliegt.
pynvml ist die Python-Anbindung an die NVIDIA Management Library (NVML) also genau die Bibliothek, die wir jetzt brauchen um die Daten auszulesen. So erhalten wir strukturierte Werte direkt von dem Inferenz-Server.
FastMCP ist eine schlanke Python-Bibliothek, die das MCP-Protokoll für uns implementiert. NVIDIA selbst nutzt FastMCP im NeMo Agent Toolkit, um Workflows als MCP-Server zu publizieren – wir nutzen es hier in der Standalone-Variante.
EMA (Exponential Moving Average) brauchen wir, weil rohe GPU-Auslastung sprunghaft ist. Während einer Inferenz-Anfrage springt der Wert binnen Millisekunden von 0 auf 100 % und zurück. Wer das ungefiltert auf einen LED-Ring schickt, sieht ein nervöses Geflacker statt einer angenehmen Anzeige. EMA glättet das.
Voraussetzungen
Bevor wir loslegen, ein paar Dinge, die in Ordnung sein müssen:
- Ubuntu 24.04 LTS (oder vergleichbares Linux)
- Mindestens eine NVIDIA-GPU mit aktuellem Treiber (bei mir Dual RTX A6000 Ada, aber jede CUDA-fähige Karte funktioniert)
- Python 3.11, 3.12 oder 3.13 auf dem Host – Ubuntu 24.04 bringt 3.12 mit
uvals Paket-Manager – falls Du Dich an meinen NAT-Beitrag erinnerst, das hatten wir dort installiert. Falls nicht:curl -LsSf https://astral.sh/uv/install.sh | sh- Ein Netzwerk-Setup, in dem dein MCP-Client den Server erreichen kann (LAN reicht, kein Internet erforderlich)
Falls Du Deinen Server noch grundsätzlich für KI-Inferenz vorbereiten musst, schau Dir vorher meinen Foundation-Beitrag dazu an.
Schritt 1: pynvml installieren und GPU-Detection testen
Wir fangen mit der absoluten Basis an: kann Python überhaupt mit dem NVIDIA-Treiber reden? Dafür legen wir uns ein Projektverzeichnis an, eine eigene Python-Umgebung, und installieren pynvml.
Befehl: mkdir -p ~/gpu-monitor-mcp && cd ~/gpu-monitor-mcp
Befehl: uv venv --python 3.12 --seed .venv
Befehl: source .venv/bin/activate
Es gibt auf PyPI zwei Pakete, die fast gleich heißen, mit einer verwirrenden Historie. nvidia-ml-py ist das offizielle, von NVIDIA gepflegte Paket. Das ist genau das, was wir jetzt installieren wollen. Es gibt zusätzlich noch ein Paket namens pynvml, das früher eine eigenständige Drittanbieter-Bibliothek war, mittlerweile vom NVIDIA-RAPIDS-Team gepflegt wird und seit Version 13 (September 2025) offiziell deprecated ist. Es zieht sich heute nur noch nvidia-ml-py als Dependency, also funktioniert es technisch noch aber wir sollten es nicht mehr verwenden. Installiere direkt nvidia-ml-py.
Befehl: uv pip install nvidia-ml-py
Trotzdem heißt der Python-Import schlicht pynvml das offizielle Paket installiert das Modul unter diesem Namen. Verwirrend, aber so ist es historisch gewachsen.
Zum Testen legen wir jetzt ein kleines Skript an. Dazu im Terminal-Fenster den folgenden Befehl ausführen. Ich nutze nano:
Befehl: nano test_gpus.py
Jetzt fügt Du den folgenden Python Code in die noch leere test_gpus.py Datei ein.
import pynvml
pynvml.nvmlInit()
count = pynvml.nvmlDeviceGetCount()
print(f"Gefundene GPUs: {count}\n")
for i in range(count):
handle = pynvml.nvmlDeviceGetHandleByIndex(i)
name = pynvml.nvmlDeviceGetName(handle)
util = pynvml.nvmlDeviceGetUtilizationRates(handle)
mem = pynvml.nvmlDeviceGetMemoryInfo(handle)
temp = pynvml.nvmlDeviceGetTemperature(handle, pynvml.NVML_TEMPERATURE_GPU)
print(f"GPU {i}: {name}")
print(f" Auslastung: {util.gpu}%")
print(f" VRAM: {mem.used / 1024**3:.1f} / {mem.total / 1024**3:.1f} GB")
print(f" Temperatur: {temp} °C\n")
pynvml.nvmlShutdown()Mit STRG + X, dann Y und ENTER wird die Datei gespeichert. Jetzt können wir diese mit dem nachfolgenden Befehl ausführen:
Befehl: python test_gpus.py
Bei mir zeigt das kleine Python Programm jetzt folgendes an. Damit habe ich Gewissheit dass ich auf die Informationen meiner beiden GPUs zugreifen kann:
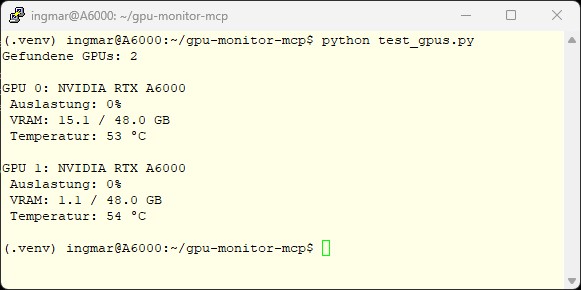
nvidia-ml-py – Server GPU load
Wenn das bei Dir auch funktioniert, sind die Treiber und pynvml in Ordnung. Wenn nicht, schau bitte in den Stolperfallen-Abschnitt am Ende.
Schritt 2: FastMCP installieren
Jetzt müssen wir noch die fastmcp-Bibliothek in unsere virtuelle Umgebung installieren:
Befehl: uv pip install fastmcp
Das zieht etwa 40 bis 50 Pakete und ging rasend schnell. Dazu gehören z. B. der HTTP-Stack, Pydantic, das MCP-SDK und ein bisschen mehr. Mit uv ist das in wenigen Sekunden durch.
Zum Verifizieren ob alles geklappt hatte bitte den folgenden Befehl einmal ausführen.
Befehl: python -c "from fastmcp import FastMCP; print('FastMCP bereit')"
Bei mir kam als Ausgabe „FastMCP bereit“. Wenn keine Fehler erscheinen, sind wir startklar und haben jetzt die Basis am Laufen um den MCP-Server zu bauen.
Schritt 3: Den minimalen MCP-Server schreiben
Wir starten mit einem absolut minimalen Server, der nur ein einziges Tool bereitstellt – nämlich die Anzahl der verbauten GPUs. Erst wenn das läuft, bauen wir den MCP-Server Stück für Stück aus.
Befehl: nano gpu_monitor.py
"""
GPU Monitor MCP Server – Schritt 1: Minimaler Test
"""
import pynvml
from fastmcp import FastMCP
# NVML einmalig beim Start initialisieren
pynvml.nvmlInit()
GPU_COUNT = pynvml.nvmlDeviceGetCount()
# Den MCP-Server anlegen, mit einem sprechenden Namen
mcp = FastMCP(name="GPU Monitor")
@mcp.tool()
def get_gpu_count() -> int:
"""Gibt die Anzahl der verfügbaren GPUs zurück."""
return GPU_COUNT
if __name__ == "__main__":
# Auf allen Interfaces lauschen, damit auch Clients aus dem LAN
# zugreifen können. Port 8765 – Du kannst auch einen anderen wählen.
mcp.run(transport="sse", host="0.0.0.0", port=8765)Was passiert jetzt genau in diesem kleinen Skript das uns einen MCP-Server bereitstellt?
pynvml.nvmlInit()läuft genau einmal beim Server-Start wir wollen die NVML-Initialisierung nicht bei jeder Tool-Anfrage wiederholen, das wäre Verschwendung.FastMCP(name="GPU Monitor")legt den Server an.- Der
@mcp.tool()-Dekorator markiert eine Python-Funktion als MCP-Tool. FastMCP nutzt automatisch die Type Hints (-> int) und den Docstring, um Clients zu erklären, was das Tool tut. Genau die Beschreibung, die ein LLM später lesen wird, um zu entscheiden, wann es das Tool aufruft. mcp.run(transport="sse", ...)startet den Server mit Server-Sent Events (SSE) als Transport. Das ist HTTP-basiert und funktioniert sauber über Netzwerk im Gegensatz zum Standard-Transportstdio, der nur lokal über Pipes läuft.
Wenn Du das kleine Python-Skript bzw. unseren MCP-Server noch nicht gespeichert hast dann mach das jetzt. Mit STRG + X, dann Y und ENTER wird die Datei gespeichert.
Mit dem jetzt folgenden Befehl führen wir das Python Skript aus und starten den Fast-MCP Server.
Befehl: python gpu_monitor.py
Jetzt sollte bei Dir der FastMCP Server starten und im Terminal-Fenster folgendes angezeigt werden.
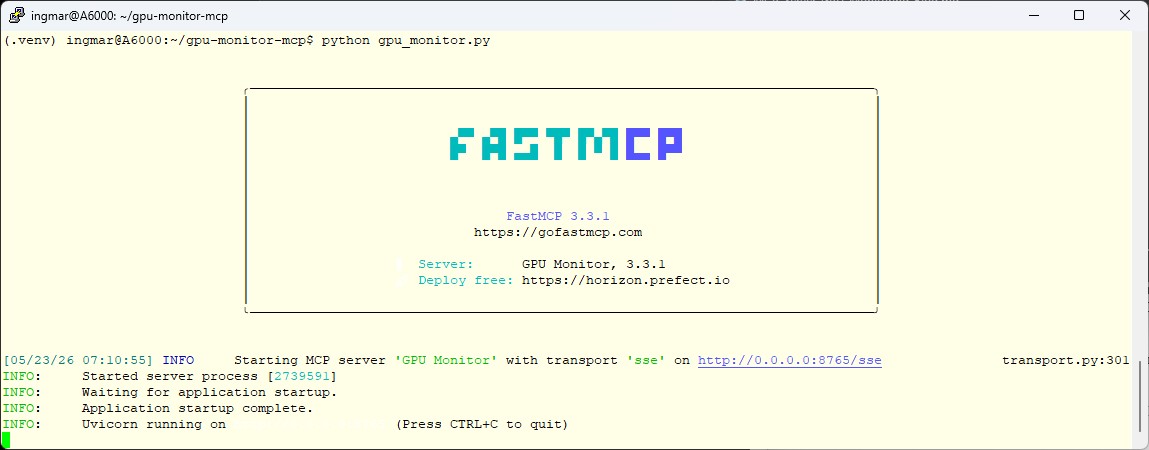
Fast-MCP Server – Server GPU load
Damit läuft Dein erster eigener MCP-Server und wir können diesen jetzt weiter ausbauen.
Wenn Du jetzt den MCP-Server testen möchtest, kann Du nicht einfach im Browser die URL aufrufen zu Deinem MCP Server. Wenn Du jetzt also versucht bist, einfach http://192.168.2.57:8765/ im Browser zu öffnen, dann wird Du nur ein ‚Not Found‘ sehen. Das ist kein Fehler. MCP-Server sind keine Webseiten und exponieren nichts an der Wurzel-URL. Wir brauchen einen richtigen MCP-Client zum Testen.
Um etwas zu sehen brauchst Du also einen MCP-Inspektor bei Dir auf dem Rechner. Da ich unter Windows als Client unterwegs bin, habe ich mir von Anthropic genau solch einen MCP Inspektor mit dem folgenden Befehl in meiner PowerShell installiert.
Befehl: npx @modelcontextprotocol/inspector
Nach der Installation, wenn Du diesen noch nicht installiert hattest, öffnet sich ein Browser-Fenster. Dort links oben unbedingt den TransportType auf SSE (*1) umstellen. Dann die IP-Adresse zu Deinem Fast-MCP Server eingeben mit Port und /sse am Ende (*2). Bei mir lautet diese:
URL: http://192.168.2.57:8765/sse
Im nachfolgenden Bild siehst Du dann bei (*3) das die Verbindung geklappt hat und der Name „GPU Monitor“ von unserem MCP-Server angezeigt wird.
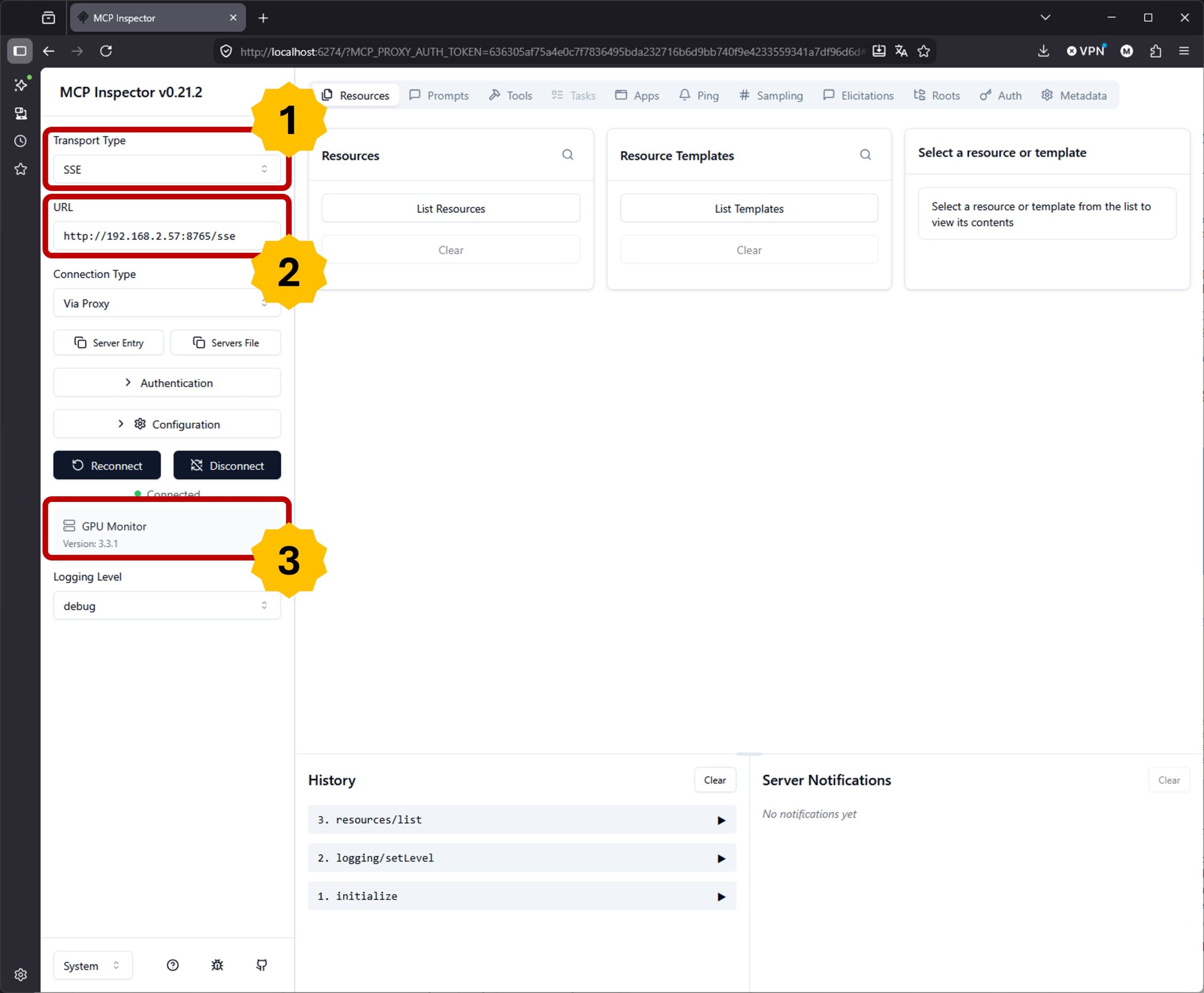
MCP-Inspector
Mit STRG + C kannst Du jetzt den MCP-Server im Terminal-Fenster beenden, dann gehen wir an die eigentliche Funktionalität und entwicklen jetzt den MCP-Server zu einem richtigen GPU-Monitor-Service weiter.
Schritt 4: Multi-GPU-Auslastung und Speicherbelegung
Jetzt erweitern wir den MCP-Server bzw. unser kleines Skript um die eigentlich interessanten Tools. Dazu passen wir jetzt die gpu_monitor.py Python-Datei an und ersetzen den bisherigen Inhalt mit dem folgenden Coding das ich auf GitHub bereitgestellt habe da es hier zu lang wäre und auch nicht schön formatiert.
URL: gpu_monitor.py
Drei wichtige Dinge zu diesem Code:
- Jedes Tool hat einen
gpu_id-Parameter mit Default0. Damit funktionieren Single-GPU- und Multi-GPU-Systeme transparent. Mit der ID 0 kann ein Client, der nur eine GPU kennt, den Parameter weglassen. Multi-GPU-Clients können explizit jede einzelne GPU abfragen. Das habe ich implementiert, da ich meinen ESP-Claw auf einem 24 LED Ring beide GPUs anzeigen lassen möchte. - Jedes Tool gibt ein Dictionary zurück, kein Tupel oder eine Liste. Das macht die Antwort-Struktur selbsterklärend. Der LLM-Client sieht später Schlüssel wie
"temperature_c", nicht eine namenlose Zahl. - Die Docstrings sind sorgfältig formuliert. FastMCP gibt sie dem Client weiter, und ein LLM-Agent entscheidet anhand dieser Beschreibung, wann es Dein Tool aufruft. Bessere Docstrings → bessere Tool-Auswahl. Hier muss ich aber noch selber Erfahrung sammeln was mit welchem Modell als Erklärungs-Text gut zusammen funktioniert.
Wenn Du den kleinen MCP-Server nach den Anpassungen neugestartet hast und jetzt wieder den MCP-Inspector aktualisierst solltest Du die neu hinzugefügten Tools sehen. Bei mir sieht das jetzt wie folgt aus.
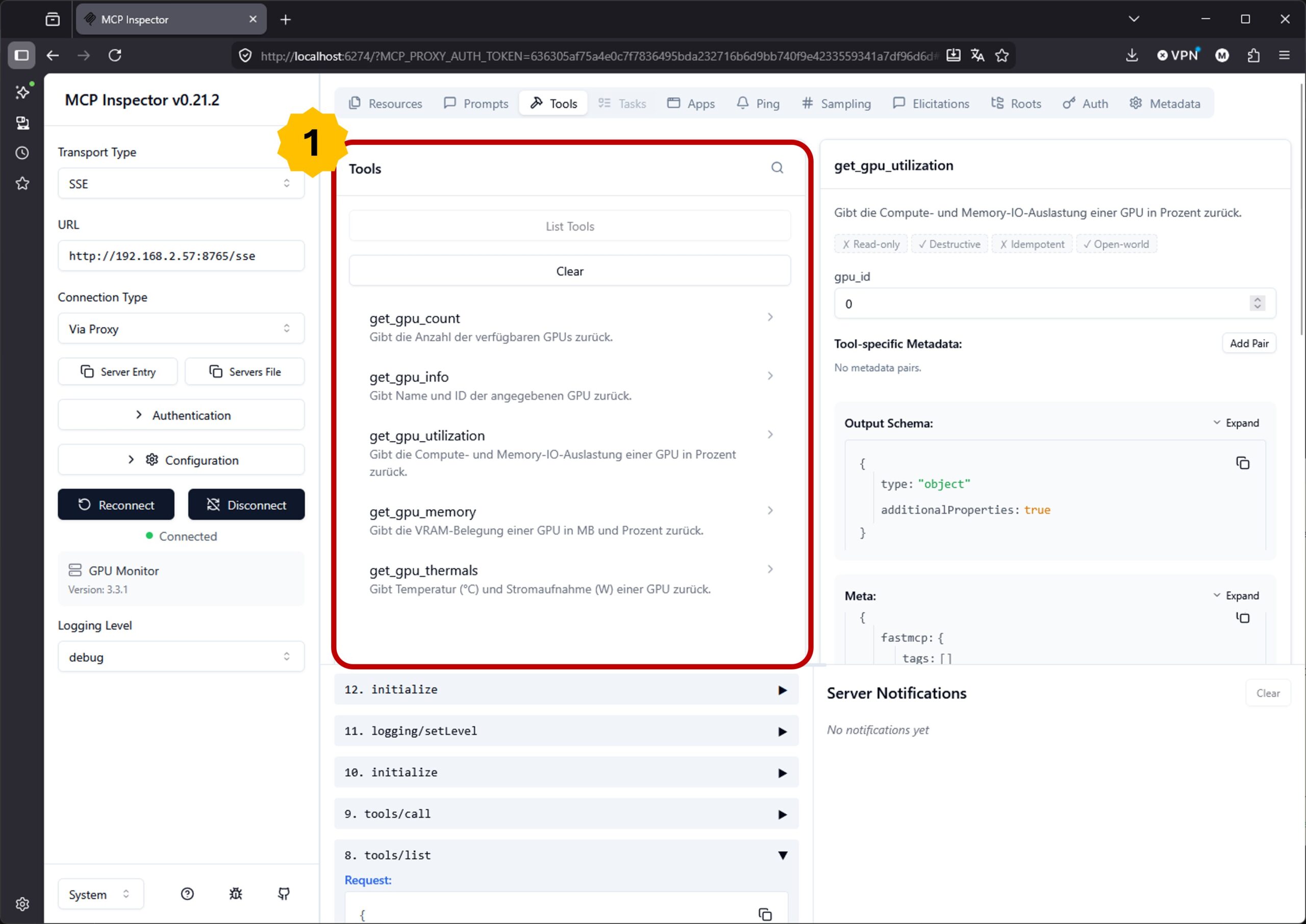
MCP inspector tools overview
Jetzt kannst Du schon einmal die Anzahl der GPUs auflisten lassen wenn Du möchtest. Also die Tools deines MCP-Servers ausführen.
Schritt 5: EMA-Glättung integrieren
Jetzt kommt das eigentliche Kernstück: die Exponential Moving Average. Idee in einer Zeile:
neuer_geglätteter_wert = alpha × neuer_rohwert + (1 - alpha) × alter_geglätteter_wertalpha ist der Glättungsfaktor zwischen 0 und 1. Hoher Wert (z. B. 0,7) heißt: der Server reagiert schnell auf Änderungen, Glättung gering. Niedriger Wert (z. B. 0,1) heißt: stark geglättet, langsamer in der Reaktion. Für GPU-Anzeigen am LED-Ring habe ich mit alpha = 0,3 sehr gute Ergebnisse erzielt. Das ist schnell genug, um Spitzen sichtbar zu machen, ruhig genug, um nicht zu flackern und es funktioniert auch über die lange WAN-Strecke.
Wir bauen die Glättung in eine kleine Klasse, damit sie über mehrere Tool-Aufrufe hinweg den State behält. Dazu passen wir jetzt die gpu_monitor.py Python-Datei ein weiteres Mal an und ersetzen den bisherigen Inhalt mit dem folgenden Coding das ich auf GitHub bereitgestellt habe da es hier zu lang wäre und auch nicht schön formatiert.
URL: gpu_monitor_EMA.py
Was hat sich gegenüber Schritt 4 geändert?
- Die
EMASmoother-Klasse ist neu. Sie hält pro Schlüssel (etwagpu0_compute,gpu1_compute) einen separaten geglätteten Wert. So vermischen sich die GPUs nicht. get_gpu_utilization()hat einen neuen Parametersmoothed=True. Default ist EIN, weil das in 95 % der Fälle gewünscht ist. Wer den Rohwert braucht (z. B. für Logging), setztsmoothed=False.- Neu ist
get_all_gpus_summary()Das ist die Idee eines Aggregator-Tools, das in einem einzigen Aufruf den Status aller GPUs liefert. Genau das, was ein ESP32-Client braucht: ein Request alle 1 bis 2 Sekunden, alle Daten auf einen Schlag. Spart Netzwerk-Round-Trips.
Schritt 6: Den Server starten und testen
Jetzt starte wieder den Server mit all seinen Anpassungen.
Befehl: python gpu_monitor_EMA.py
Du siehst die Startmeldung deines FastMCP-Servers im Terminal-Fenster. Jetzt der Test ob noch alles funktioniert wie bereits mehrfach beschrieben.
Ich möchte das bei mir der MCP-Server immer läuft wenn der Server hochfährt und daher plane ich diesen als Hintergrundjob wie im folgenden Abschnitt beschrieben ein.
Schritt 7 (optional): Als systemd-Service einrichten
Wenn der MCP-Server permanent laufen soll und das soll er bei mir, denn mein ESP32-Claw soll ihn jederzeit fragen können soll, richte ich mir einen systemd-Service ein.
Service-Datei anlegen:
Befehl: sudo nano /etc/systemd/system/gpu-monitor-mcp.service
Der Service muss von Dir angepasst werden das er zu Deinen verwendeten Verzeichnissen passt und Dateinamen. Also lese Dir die Beschreibung genau durch und passe die Stellen an die bei Dir anders sind.
[Unit]
Description=GPU Monitor MCP Server
After=network.target
[Service]
Type=simple
User=ingmar
WorkingDirectory=/home/ingmar/gpu-monitor-mcp
ExecStart=/home/ingmar/gpu-monitor-mcp/.venv/bin/python /home/ingmar/gpu-monitor-mcp/gpu_monitor.py
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.targetPfade und Username (ingmar) entsprechend bei Dir anpassen.
Aktivieren und starten:
Befehl: sudo systemctl daemon-reload
Befehl: sudo systemctl enable --now gpu-monitor-mcp
Befehl: sudo systemctl status gpu-monitor-mcp
Wenn alles richtig konfiguriert ist, läuft der Server jetzt automatisch beim Neustarten des Servers auch hoch. Die Logs schaust Du Dir mit journalctl -u gpu-monitor-mcp -f an, für den Fall das es zu Problemen kommt.
Stolperfallen, die ich hier einmal erwähnen möchte
1. nvidia-ml-py vs. pynvml – verwirrende Namen
Auf PyPI gibt es beide Bibliotheken. Das offizielle, von NVIDIA gepflegte Paket heißt nvidia-ml-py, importiert aber als pynvml. Es gibt auch ein älteres Paket namens pynvml von einem Drittanbieter das nicht mehr weiter gepflegt wird und daher wollen wir das nicht installieren. Wenn was nicht klappt: uv pip uninstall pynvml nvidia-ml-py und dann sauber nur nvidia-ml-py neu installieren.
2. NVML-Initialisierung schlägt fehl
Wenn pynvml.nvmlInit() einen NVMLError_LibraryNotFound wirft, ist meist der Treiber nicht korrekt installiert oder die Treiberversion passt nicht zur CUDA-Version. Prüfen mit dem folgenden Befehl ob Du Deine GPU(s) siehst:
Befehl: nvidia-smi
Wenn das schon nicht funktioniert, ist das ein Treiber-Thema und nicht eines von pynvml.
3. FastMCP-Version und Transport-Namen
FastMCP entwickelt sich aktuell schnell weiter. Die Bezeichnung transport="sse" kann in zukünftigen Versionen durch transport="streamable-http" oder ähnliche Namen ersetzt werden. Falls Du beim Starten einen ValueError zum Transport siehst, schau in die aktuelle FastMCP-Doku.
URL: https://gofastmcp.com/getting-started/welcome
4. EMA-Werte aktualisieren sich nicht
Beim ersten Tool-Aufruf hat der Smoother noch keinen Vorgängerwert und übernimmt direkt den Rohwert. Das ist gewollt und stört nur, wenn Du beim ersten Aufruf ohnehin einen unrealistischen Wert ziehst (z. B. weil gerade keine Last anliegt). Falls Du das vermeiden willst, kannst Du den Smoother beim Server-Start mit einem Dummy-Wert (etwa 0) vorladen.
5. Was Du NICHT machen solltest
pynvml.nvmlInit()bei jedem Tool-Aufruf neu – das kostet unnötig Zeit und ist nicht thread-safe.pynvml.nvmlShutdown()am Ende eines Tool-Aufrufs – damit zerschießt Du den State zwischen den Anfragen. Der Shutdown gehört in einen Server-Shutdown-Handler, falls überhaupt.- Den Server ungeschützt ins offene Internet exponieren. MCP hat keine eingebaute Authentifizierung. Für den LAN-Betrieb in der eigenen Werkstatt ist das okay, alles darüber hinaus mindestens hinter Tailscale, WireGuard oder einem Reverse Proxy mit Token-Auth.
Was kommt als Nächstes?
Mit diesem Server hast Du den Datenlieferanten. Was jetzt fehlt, ist der Konsument. In den nächsten Beiträgen baue ich das in zwei Richtungen aus:
- NeMo Agent Toolkit als MCP-Client: Ich hänge den Server an meinen NAT-Workflow aus dem letzten Beitrag. Damit kann mein Agent in Antworten echte Hardware-Werte einbauen etwa wenn ich frage „Sind meine GPUs gerade frei für ein Fine-Tuning?“, und der Agent ruft das Tool, sieht 5 % Last und sagt klar Ja.
- ESP-Claw als MCP-Client mit LED-Ring: Das ist das eigentliche Ziel dieser Serie. Mein ESP32-P4 mit dem ESP-Claw-Framework hat eine MCP-Client-Capability eingebaut. Ein Custom-Skill ruft alle zwei Sekunden
get_all_gpus_summaryab und visualisiert die Compute-Auslastung als gefüllten Ring, die Temperatur als Farbgradient und den Power-Draw als Helligkeit.
Beides sind eigenständige, spannende Bausteine, die ich in den nächsten Beiträgen Stück für Stück plane zu bauen.
Mein persönliches Fazit
Was mich an diesem kleinen Projekt am meisten überrascht hat: wie wenig Code es eigentlich braucht, um eine sinnvolle Infrastruktur-Brücke zu bauen. Knapp 100 Zeilen Python, eine sehr fokussierte Bibliothek (FastMCP) und eine sehr alte, sehr stabile NVIDIA-API (NVML) und schon habe ich eine Datenquelle, die jedes MCP-kompatible Tool anzapfen kann. Vom kleinen ESP32-Mikrocontroller bis zum Claude Desktop auf meinem Laptop. Ohne Cloud, ohne SaaS-Abo, ohne API-Key bei einem Drittanbieter.
Genau diese Konstellation – Standard-Protokoll plus eigene Hardware plus minimale Software ist für mich der praktische Kern dessen, was ich mit „souveräner KI“ meine. Es geht nicht darum, dass man jedes Stück selbst neu erfindet. Es geht darum, dass man die Bausteine kennt, sie kombinieren kann und keine Abhängigkeiten eingeht, die man nicht braucht.
Der MCP-Server für meine GPUs ist klein. Aber er ist meiner. Und das macht den Unterschied.
Viel Erfolg beim Nachbauen!









{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…