


Nachdem ich in meinen vorherigen Beiträgen gezeigt habe, wie ihr Ollama, Open WebUI, ComfyUI und LLaMA Factory auf dem Gigabyte AI TOP ATOM installiert, kommt jetzt etwas für alle, die maximale Performance beim Ausführen von Large Language Models benötigen: vLLM – eine hochperformante Inference-Engine, die speziell darauf ausgelegt ist, LLMs mit maximalem Durchsatz und minimalem Speicherverbrauch zu betreiben.
In diesem Beitrag zeige ich euch, wie ich vLLM auf meinem Gigabyte AI TOP ATOM installiert und konfiguriert habe, um Sprachmodelle wie Qwen, LLaMA oder Mistral mit optimaler Performance auszuführen. vLLM nutzt ebenfalls die volle GPU-Performance der Blackwell-Architektur und bietet eine OpenAI-kompatible API, sodass bestehende Anwendungen nahtlos integriert werden können. Da das von mir genutzte AI TOP ATOM System auf der gleichen Plattform wie die NVIDIA DGX Spark basiert, funktionieren die offiziellen NVIDIA Playbooks hier genauso zuverlässig. Für meine Erfahrungsberichte hier auf meinem Blog habe ich den Gigabyte AI TOP ATOM von der Firma MIFCOM einen Spezialisten für Hochleistungs- und Gaming-Rechner aus München ausgeliehen bekommen.
Die Grundidee: Maximale Performance für LLM-Inference
Bevor ich in die technischen Details einsteige, ein wichtiger Punkt: vLLM ist eine Inference-Engine, die darauf ausgelegt ist, Large Language Models mit maximalem Durchsatz und minimalem Speicherverbrauch zu betreiben. Im Gegensatz zu Standard-Inference-Lösungen nutzt vLLM innovative Techniken wie PagedAttention für speichereffiziente Attention-Berechnungen und Continuous Batching, um neue Anfragen zu laufenden Batches hinzuzufügen und die GPU-Auslastung zu maximieren. Meine Erfahrung hier zeigt das vLLM deutlich schneller ist als Ollama wenn es darum geht hunderter ähnlicher Anfragen hintereinandert zu bearbeiten. Genau so wie wir es in industriellen Anwendungen häufig als Anforderung finden werden.
Das Besondere daran: vLLM bietet eine OpenAI-kompatible API, sodass Anwendungen, die für die OpenAI API entwickelt wurden, nahtlos auf einen vLLM-Backend umgestellt werden können – ohne Code-Änderungen. Das bedeutet, dass wir auch je nach Auslastung des Systems uns externe Power dazu holen können wenn diese benötigt wird. Die Installation erfolgt über Docker mit einem vorgefertigten NVIDIA Container, der bereits alle notwendigen Bibliotheken und Optimierungen für die Blackwell-Architektur enthält. Dieses Vorgehen haben wir jetzt schon bei den anderen Berichten wie LLaMA Factory kennen gelernt.
Was ihr dafür braucht:
-
Einen Gigabyte AI TOP ATOM, ASUS Ascent, MSI EdgeXpert (oder NVIDIA DGX Spark) der mit dem Netzwerk verbunden ist
-
Einen angeschlossenen Monitor oder Terminal-Zugriff auf den AI TOP ATOM
-
Docker installiert und für GPU-Zugriff konfiguriert
-
NVIDIA Container Toolkit installiert
-
Grundkenntnisse in Terminal-Befehlen, Docker und REST APIs
-
Mindestens 20 GB freien Speicherplatz für Container-Images und Modelle
-
Eine Internetverbindung zum Download von Modellen vom Hugging Face Hub
-
Optional: Ein Hugging Face Account für gated Models (Modelle mit Zugriffsbeschränkungen)
System-Voraussetzungen prüfen
Ich gehe jetzt bei meiner weiteren Anleitung davon aus, dass ihr direkt vor dem AI TOP ATOM oder der NVIDIA DGX Spark sitzt und einen Monitor, Keyboard und Maus angeschlossen habt. Zuerst prüfe ich, ob alle notwendigen System-Voraussetzungen erfüllt sind. Dazu öffne ich ein Terminal auf meinem AI TOP ATOM und führe die folgenden Befehle aus.
Der nachfolgende Befehl zeigt euch, ob das CUDA Toolkit installiert ist:
Befehl: nvcc --version
Ihr solltet CUDA 13.0 sehen. Als nächstes prüfe ich, ob Docker installiert ist:
Befehl: docker --version
Jetzt prüfe ich, ob Docker GPU-Zugriff hat:
Befehl: docker run --gpus all nvcr.io/nvidia/cuda:13.0.1-devel-ubuntu24.04 nvidia-smi
Dieser Befehl startet einen Test-Container und zeigt die GPU-Informationen an. Falls Docker noch nicht für GPU-Zugriff konfiguriert ist, müsst ihr das zuerst einrichten. Prüft auch Python und Git:
Befehl: python3 --version
Befehl: git --version
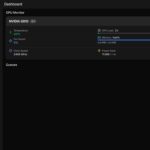
Und schließlich prüfe ich, ob die GPU erkannt wird:
Befehl: nvidia-smi
Ihr solltet jetzt die GPU-Informationen sehen. Falls einer dieser Befehle fehlschlägt, müsst ihr die entsprechenden Komponenten zuerst installieren.
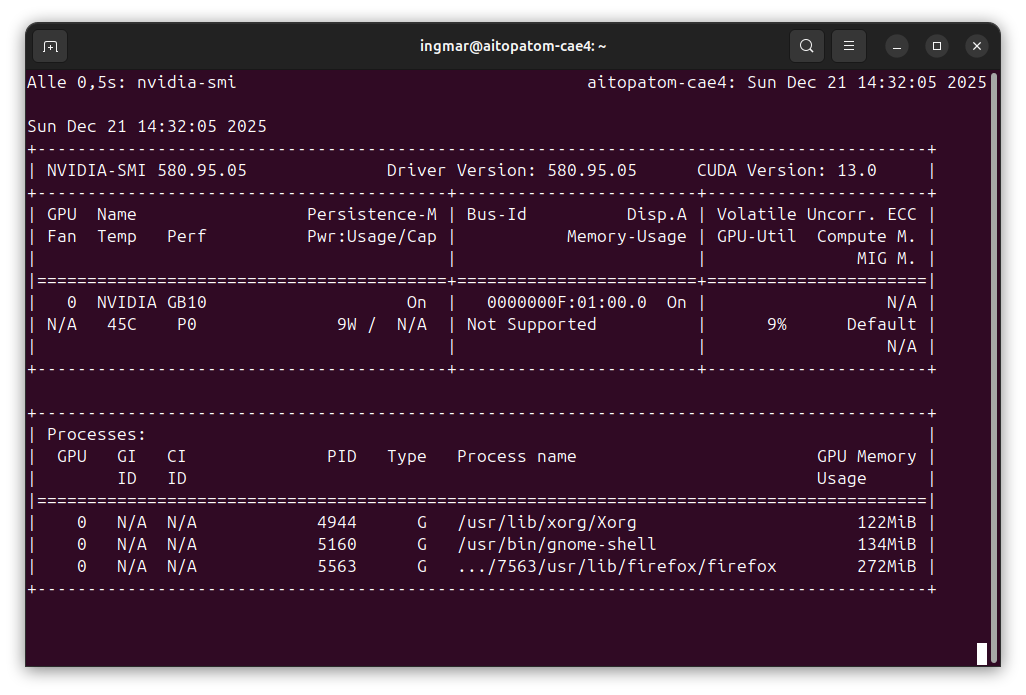
GIGABYTE AI TOP ATOM – NVIDIA-SMI
Das vLLM Container Image herunterladen
vLLM läuft in einem Docker-Container, der bereits alle notwendigen Bibliotheken und Optimierungen für die Blackwell-Architektur enthält. Das macht die Installation deutlich einfacher, da wir uns nicht um Python-Dependencies oder Build-Prozesse kümmern müssen. Ihr müsst hierfür keinen Ordner anlegen – Docker verwaltet das Container-Image automatisch. Ich lade einfach das vLLM Container-Image wie folgt von NVIDIA herunter:
Befehl: docker pull nvcr.io/nvidia/vllm:25.11-py3
Dieser Befehl lädt das neueste vLLM Container-Image herunter. Je nach Internetgeschwindigkeit kann der Download einige Minuten dauern. Das Image das jetzt herunter geladen wird ist etwa 10-15 GB groß. Docker speichert das Image automatisch in seinem eigenen Verzeichnis (normalerweise unter /var/lib/docker). Das Image enthält bereits alle notwendigen CUDA-Bibliotheken und Optimierungen für die Blackwell-GPU. Das heißt für uns wir müssen nichts weiter extra manuell installieren.
Hinweis: Falls ihr Probleme beim Download habt oder eine Authentifizierung benötigt, könnt ihr das Image auch direkt von der NVIDIA NGC Registry herunterladen.
Wichtig: Einen Ordner für die Modelle legen wir erst in Phase 4 an, wenn wir vLLM für Production konfigurieren. Für den ersten Test in Phase 3 ist das nicht notwendig. Der Ordner wird ~/models heißen.
vLLM Server starten und testen (einfach)
Jetzt starte ich den vLLM Server mit einem Test-Modell, um die grundlegende Funktionalität zu überprüfen. Ich verwende das kleine openai/gpt-oss-20b Modell für den ersten Test. Im Abschnitt Phase 4 gehe ich noch einmal viel tiefer auf die Docker Parameter und Konfigurationen ein.
Hinweis: Es gibt keine einzelne, vom vLLM Projekt gepflegte Liste von unterstützten LLMs, da vLLM fast jedes Modell unterstützt, das im „Safetensors“- oder „PyTorch“-Format auf Hugging Face veröffentlicht wurde. Da vLLM extrem schnell entwickelt wird, kommen ständig neue Architekturen hinzu. Hier könnt ihr euch bei vLLM informieren über die aktuellen Architekturen. vLLM custom models
Befehl: docker run -it --gpus all -p 8000:8000 nvcr.io/nvidia/vllm:25.11-py3 vllm serve "openai/gpt-oss-20b"
Hinweis: Bei mir ist es beim Ausführen zu Fehlern gekommen die darauf schließen ließen das vLLM die 90% des verfügbaren VRAMs nicht reservieren konnte da nur noch 82 GB RAM auf dem AI TOP ATOM verfügbar waren.
Die Fehlermeldung ist hier eindeutig:
ValueError: Free memory on device (82.11/119.7 GiB) on startup is less than desired GPU memory utilization (0.9, 107.73 GiB).
Jetzt können wir vLLM beim Starten einen Wert mitgeben wie viel VRAM reserviert werden darf mit dem folgenden Attribut --gpu-memory-utilization 0.6.
Befehl: docker run -it --gpus all -p 8000:8000 --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 nvcr.io/nvidia/vllm:25.11-py3 vllm serve "openai/gpt-oss-20b" --gpu-memory-utilization 0.6
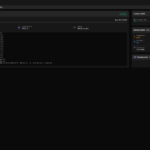
Anschließend konnte ich den Download erfolgreich starten wie ihr im folgenden Bild seht.
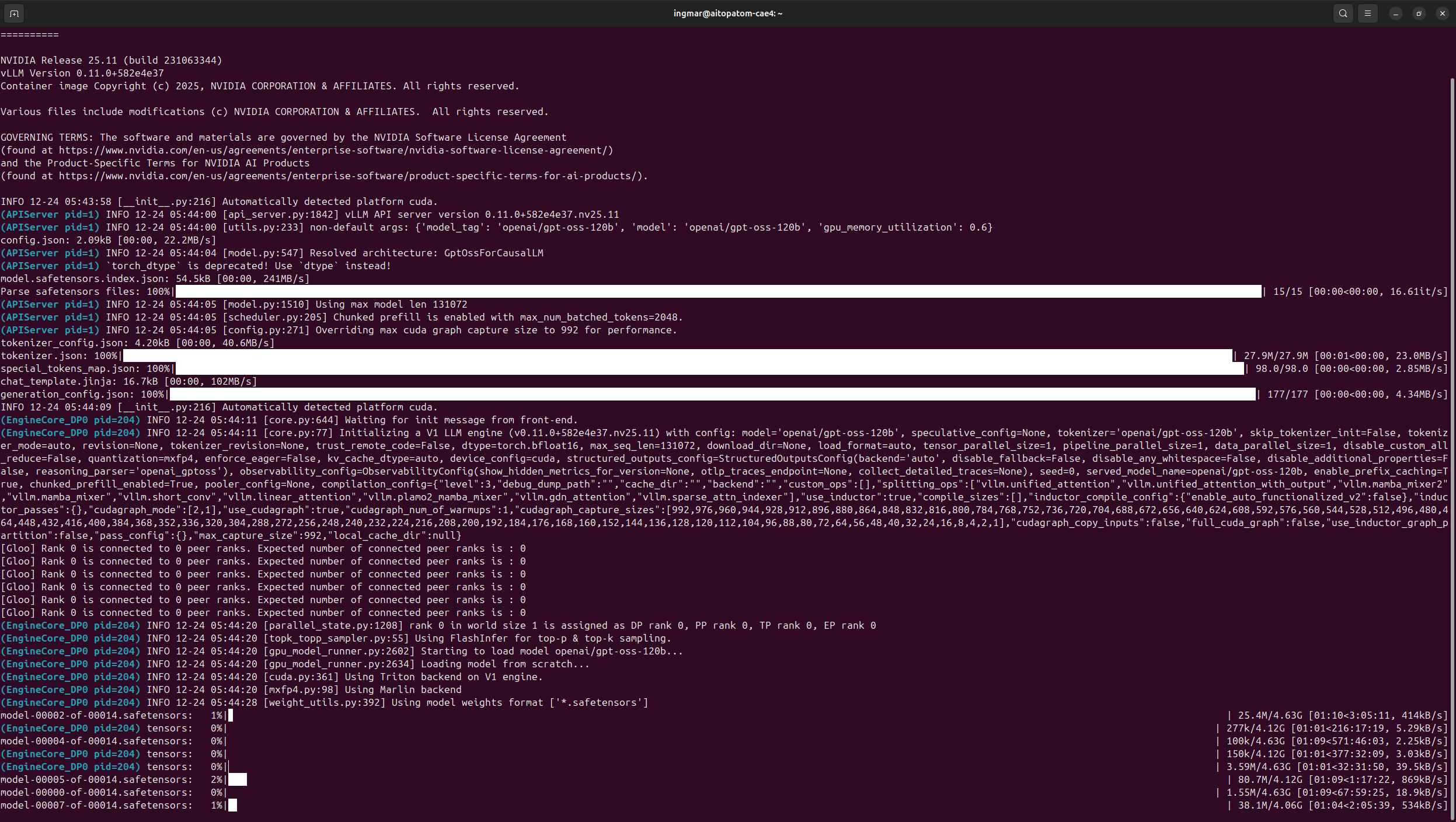
GIGABYTE AI TOP ATOM – vLLM gpt-oss-120b startup
Der Befehl docker run... startet den vLLM Server im interaktiven Modus und macht Port 8000 verfügbar. Der Server lädt das Modell automatisch vom Hugging Face Hub herunter. Ihr solltet eine Ausgabe sehen, die folgende Informationen enthält:
-
Modell-Ladebestätigung
-
Server-Start auf Port 8000
-
GPU-Speicher-Zuweisungsdetails
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Wichtiger Hinweis: Der Server läuft standardmäßig auf 0.0.0.0, was bedeutet, dass er bereits im Netzwerk erreichbar ist. Der Parameter --host 0.0.0.0 ist daher nicht zwingend notwendig, wird aber manchmal für explizite Konfiguration verwendet.
In einem zweiten Terminal-Fenster teste ich jetzt den Server mit einer einfachen CURL Anfrage ob das LLM-Modell auch antwortet:
Befehl: curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "openai/gpt-oss-20b", "messages": [{"role": "user", "content": "12*17"}], "max_tokens": 500}'
Die Antwort sollte eine Berechnung enthalten, etwa "content": "204" oder eine ähnliche mathematische Lösung. Falls die Antwort korrekt ist, funktioniert vLLM einwandfrei!
Hinweis: vLLM bietet auch einen /v1/completions Endpoint für einfache Prompt-basierte Anfragen. Für Chat-basierte Modelle wird jedoch der /v1/chat/completions Endpoint empfohlen.
Hier geht es zum 2. Teil der Installations- und Konfigurationsanleitung.




{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…