

Wer mit Large Language Modellen arbeitet und gleichzeitig große Mengen an Dokumenten analysieren möchte, kennt das Problem: Einfache Chat-Interfaces reichen nicht aus, wenn es darum geht, spezifische Informationen aus PDFs, Word-Dokumenten oder anderen Dateiformaten zu extrahieren und zu verstehen. Für mich war die Lösung klar: Ich nutze RAGFlow auf meinem X86 Ubuntu Server mit zwei NVIDIA RTX A6000 GPUs als professionelles RAG-System (Retrieval-Augmented Generation) für die intelligente Dokumentenanalyse und Wissensverarbeitung.
In diesem Beitrag zeige ich euch, wie ich RAGFlow auf meinem Ubuntu Server installiert und konfiguriert habe, um ein vollständiges RAG-System für die Analyse von Dokumenten, PDFs, Word-Dateien und anderen Formaten einzurichten. RAGFlow kombiniert moderne RAG-Technologie mit Agent-Funktionen und bietet eine professionelle Lösung für Unternehmen jeder Größe. Das Beste daran: Die Installation erfolgt komplett über Docker und ist in etwa 30-45 Minuten erledigt.
Die Grundidee: Professionelles RAG-System für intelligente Dokumentenanalyse
Bevor ich in die technischen Details einsteige, ein wichtiger Punkt: RAGFlow ist eine führende Open-Source RAG-Engine (Retrieval-Augmented Generation), die modernste RAG-Technologie mit Agent-Funktionen kombiniert, um eine überlegene Kontextschicht für LLMs zu schaffen. Im Gegensatz zu einfachen Chat-Interfaces kann RAGFlow komplexe Dokumente verstehen, Informationen extrahieren und diese intelligent für LLM-Anfragen aufbereiten. Meine Erfahrung zeigt, dass RAGFlow besonders bei der Analyse von PDFs, Word-Dokumenten, Excel-Dateien und sogar gescannten Dokumenten brilliert.
Das Besondere daran: RAGFlow bietet eine template-basierte Chunking-Methode, die es ermöglicht, Dokumente intelligent zu segmentieren und dabei die semantische Bedeutung zu erhalten. Außerdem unterstützt RAGFlow gegroundete Zitate mit reduzierten Halluzinationen – das bedeutet, dass jede Antwort mit konkreten Quellenangaben versehen wird, sodass ihr genau wisst, aus welchem Dokument und welchem Abschnitt die Information stammt. Die Installation erfolgt über Docker Compose mit vorgefertigten Containern, die bereits alle notwendigen Komponenten wie Elasticsearch, MySQL, Redis und MinIO enthalten.
Was ihr dafür braucht:
-
Einen X86 Ubuntu Server (20.04 oder neuer) mit mindestens 4 CPU-Kernen
-
Mindestens 16 GB RAM (empfohlen: 32 GB oder mehr für größere Dokumentensammlungen)
-
Mindestens 50 GB freien Speicherplatz (empfohlen: 100 GB+ für Dokumente und Indizes)
-
Zwei NVIDIA RTX A6000 GPUs (oder andere CUDA-fähige GPUs) für GPU-beschleunigte Dokumentenverarbeitung
-
Docker >= 24.0.0 installiert und für GPU-Zugriff konfiguriert
-
Docker Compose >= v2.26.1 installiert
-
NVIDIA Container Toolkit installiert
-
Grundkenntnisse in Terminal-Befehlen, Docker und REST APIs
-
Optional: gVisor installiert, falls ihr die Code-Executor-Funktion (Sandbox) nutzen möchtet
-
Einen LLM API-Key (OpenAI, Anthropic, oder andere unterstützte LLM-Provider)
Phase 1: System-Voraussetzungen prüfen
Ich gehe jetzt bei meiner weiteren Anleitung davon aus, dass ihr direkt vor dem Server sitzt oder SSH-Zugriff habt. Zuerst prüfe ich, ob alle notwendigen System-Voraussetzungen erfüllt sind. Dazu öffne ich ein Terminal auf meinem Ubuntu Server und führe die folgenden Befehle aus.
Der nachfolgende Befehl zeigt euch, ob Docker installiert ist:
Befehl: docker --version
Ihr solltet Docker 24.0.0 oder neuer sehen. Als nächstes prüfe ich Docker Compose:
Befehl: docker compose version
Ihr solltet Docker Compose v2.26.1 oder neuer sehen.
Hinweis: Falls Docker oder Docker Compose nicht installiert ist, könnt ihr Docker wie folgt installieren:
Zuerst füge ich den Docker-GPG-Schlüssel hinzu:
Befehl: sudo apt-get update
Befehl: sudo apt-get install ca-certificates curl gnupg
Befehl: sudo install -m 0755 -d /etc/apt/keyrings
Befehl: curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
Befehl: sudo chmod a+r /etc/apt/keyrings/docker.gpg
Jetzt füge ich das Docker Repository zu den Apt-Quellen hinzu:
Befehl: echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
Jetzt installiere ich Docker Engine, Docker CLI und Docker Compose:
Befehl: sudo apt-get update
Befehl: sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Jetzt aktiviere ich den Docker-Service und füge meinen Benutzer zur Docker-Gruppe hinzu:
Befehl: sudo systemctl enable --now docker
Befehl: sudo usermod -aG docker $USER
Wichtig: Nach dem Hinzufügen zur Docker-Gruppe müsst ihr euch neu einloggen oder einen neuen Terminal öffnen, damit die Änderung wirksam wird.
Jetzt prüfe ich, ob die GPUs erkannt werden:
Befehl: nvidia-smi
Ihr solltet jetzt beide RTX A6000 GPUs sehen. Falls dieser Befehl fehlschlägt, müsst ihr die NVIDIA-Treiber zuerst installieren.
Ein wichtiger Schritt: Damit Docker auf die GPUs zugreifen kann, muss das NVIDIA Container Toolkit installiert sein. Falls der folgende Test-Befehl fehlschlägt, installiert das Toolkit wie unten beschrieben:
Befehl: docker run --rm --gpus all nvidia/cuda:12.0-base-ubuntu22.04 nvidia-smi
Falls dieser Befehl einen Fehler wie could not select device driver "" with capabilities: [[gpu]] zurückgibt, müsst ihr das NVIDIA Container Toolkit installieren. Ich verwende hier eine robuste Methode, die auch funktioniert, wenn die automatische Distribution-Erkennung Probleme macht:
Zuerst füge ich den GPG-Schlüssel hinzu:
Befehl: curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
Jetzt füge ich das Repository hinzu. Ich verwende hier die stabile Methode, die direkt von NVIDIA bereitgestellt wird und auch bei Ubuntu 24.04 funktioniert:
Befehl: curl -fsSL https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
Hinweis: Falls ihr bereits eine fehlerhafte Datei habt (z.B. mit HTML-Inhalt statt der Paketliste), könnt ihr sie zuerst löschen: sudo rm /etc/apt/sources.list.d/nvidia-container-toolkit.list und dann den obigen Befehl erneut ausführen.
Jetzt aktualisiere ich die Paketliste und installiere das Toolkit:
Befehl: sudo apt-get update
Befehl: sudo apt-get install -y nvidia-container-toolkit
Nach der Installation konfiguriere ich Docker für die GPU-Unterstützung. Ich verwende hier den empfohlenen Setup-Befehl:
Befehl: sudo nvidia-container-toolkit q --setup
Jetzt starte ich den Docker-Daemon neu:
Befehl: sudo systemctl restart docker
Jetzt sollte der GPU-Test funktionieren:
Befehl: docker run --rm --gpus all nvidia/cuda:12.0-base-ubuntu22.04 nvidia-smi
Dieser Befehl sollte jetzt beide RTX A6000 GPUs anzeigen. Falls es immer noch nicht funktioniert, prüft die Troubleshooting-Sektion weiter unten.
Ein wichtiger Schritt für RAGFlow: Ich prüfe den Wert von vm.max_map_count, der für Elasticsearch wichtig ist:
Befehl: sysctl vm.max_map_count
Der Wert sollte mindestens 262144 betragen. Falls nicht, setze ich ihn wie folgt:
Befehl: sudo sysctl -w vm.max_map_count=262144
Um diese Einstellung dauerhaft zu machen, füge ich sie zur /etc/sysctl.conf hinzu:
Befehl: echo "vm.max_map_count=262144" | sudo tee -a /etc/sysctl.conf

Ubuntu Server – NVIDIA-SMI RTX A6000
Phase 2: RAGFlow Repository klonen
RAGFlow läuft in Docker-Containern, die bereits alle notwendigen Komponenten enthalten. Das macht die Installation deutlich einfacher, da wir uns nicht um Python-Dependencies oder Build-Prozesse kümmern müssen. Ich klone einfach das RAGFlow Repository von GitHub:
Befehl: git clone https://github.com/infiniflow/ragflow.git
Nach dem Klonen wechsle ich in das Verzeichnis:
Befehl: cd ragflow
Optional: Falls ihr eine spezifische Version verwenden möchtet, könnt ihr zu einem stabilen Tag wechseln:
Befehl: git checkout v0.23.1
Dieser Schritt stellt sicher, dass die entrypoint.sh Datei im Code mit der Docker-Image-Version übereinstimmt. Für die neueste Version könnt ihr diesen Schritt überspringen.
Hinweis: RAGFlow Docker-Images sind für x86-Plattformen gebaut. Falls ihr auf einer ARM64-Plattform arbeitet, müsst ihr das Image selbst bauen – für meinen X86 Server ist das nicht notwendig.
Phase 3: RAGFlow Server starten (einfach)
Jetzt starte ich RAGFlow mit den Standard-Einstellungen, um die grundlegende Funktionalität zu überprüfen. Ich wechsle zuerst in das Docker-Verzeichnis:
Befehl: cd docker
Standardmäßig verwendet RAGFlow die CPU für DeepDoc-Aufgaben (Dokumentenverarbeitung). Für meinen Server mit zwei RTX A6000 GPUs möchte ich die GPU-Beschleunigung aktivieren. Dazu füge ich die GPU-Konfiguration zur .env Datei hinzu:
Befehl: echo "DEVICE=gpu" | sudo tee -a .env
Jetzt starte ich RAGFlow mit Docker Compose:
Befehl: docker compose -f docker-compose.yml up -d
Dieser Befehl lädt alle notwendigen Container-Images herunter und startet sie im Hintergrund. Je nach Internetgeschwindigkeit kann der Download einige Minuten dauern. RAGFlow verwendet mehrere Container:
-
RAGFlow Hauptcontainer (mit Web-Interface und API)
-
Elasticsearch (für Volltext- und Vektorsuche)
-
MySQL (für Metadaten)
-
Redis (für Caching)
-
MinIO (für Objektspeicher)
Ich prüfe den Status der Container:
Befehl: docker compose ps
Alle Container sollten den Status „running“ haben. Um die Logs des RAGFlow-Hauptcontainers zu sehen:
Befehl: docker logs -f docker-ragflow-cpu-1
Ihr solltet eine Ausgabe sehen, die folgende Informationen enthält:
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
Wichtiger Hinweis: Wenn ihr diese Bestätigung nicht seht und direkt versucht, auf RAGFlow zuzugreifen, könnte euer Browser einen „network abnormal“ Fehler anzeigen, da RAGFlow zu diesem Zeitpunkt möglicherweise noch nicht vollständig initialisiert ist. Wartet daher, bis die obige Ausgabe erscheint.
Jetzt kann ich RAGFlow im Browser öffnen. Mit den Standardeinstellungen ist RAGFlow auf Port 80 verfügbar:
URL: http://<IP-Adresse-Server>
Ersetzt dabei <IP-Adresse-Server> mit der IP-Adresse eures Servers. Ihr könnt die IP-Adresse mit folgendem Befehl herausfinden:
Befehl: hostname -I
Phase 4: LLM API-Key konfigurieren
RAGFlow benötigt einen LLM Service wie Ollama lokal oder einen LLM API-Key eines Service Providers wie Google oder OpenAI, um mit Sprachmodellen zu kommunizieren. Standardmäßig unterstützt RAGFlow verschiedene LLM-Provider wie OpenAI, Anthropic, Gemini und viele mehr aber auch die klassischen Open Source Frameworks wie vLLM oder Ollama. Ich konfiguriere bei mir Ollama da ich dieses laufen habe und meine LLMs und Embedding Modelle lokal betreibe.
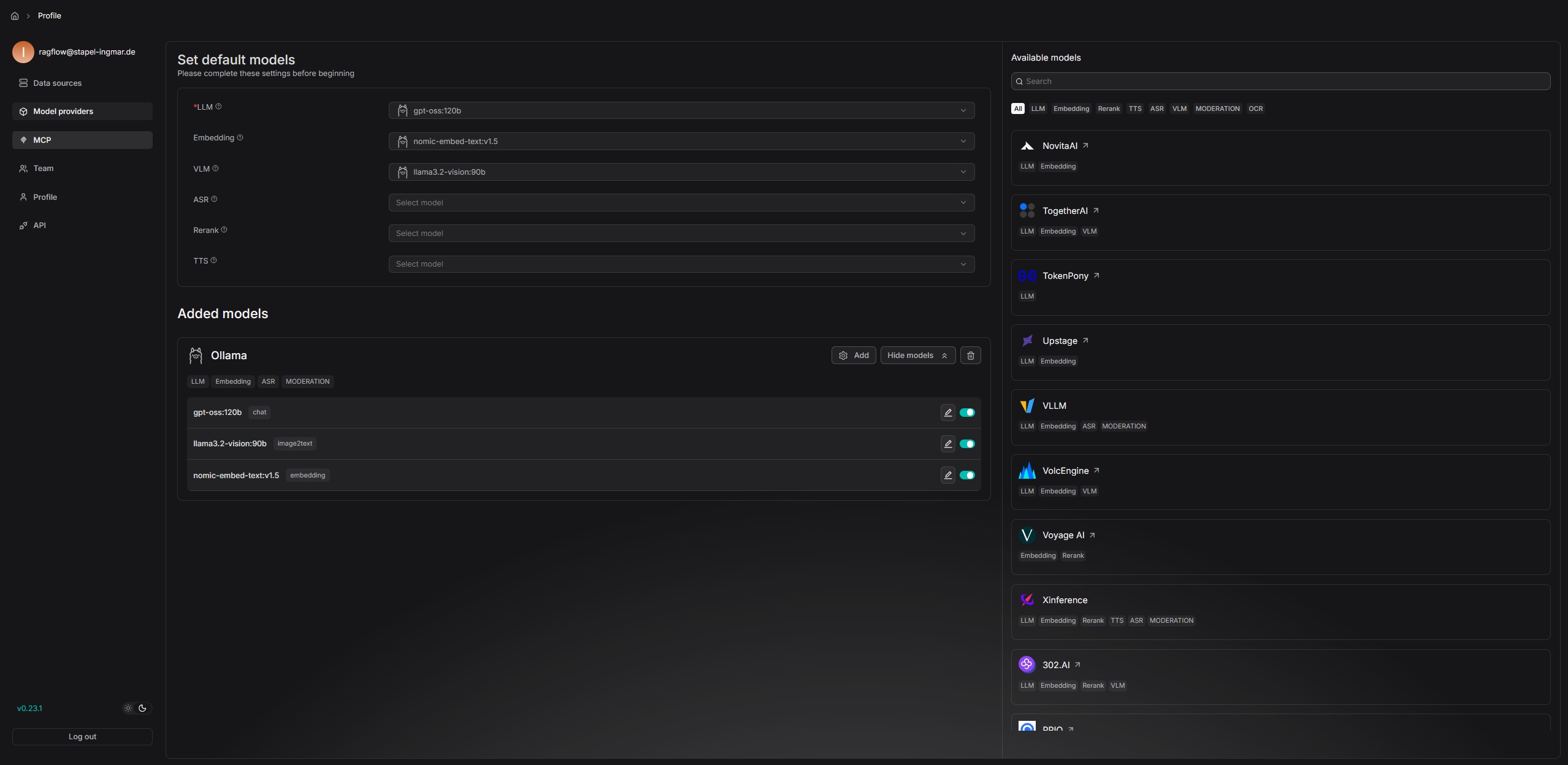
RAGFlow LLM Service setup
Hinweis: RAGFlow unterstützt auch lokale LLMs über Ollama oder vLLM. Falls ihr einen lokalen LLM-Server verwendet, müsst ihr die entsprechende Konfiguration in der service_conf.yaml.template anpassen. Weitere Informationen findet ihr in der offiziellen RAGFlow Dokumentation.
Phase 5: RAGFlow für Production-Deployment konfigurieren (komplexer)
Für einen Production-Einsatz möchte ich einige wichtige Konfigurationen anpassen. Zuerst prüfe ich die .env Datei im Docker-Verzeichnis:
Befehl: cat docker/.env
Hier könnt ihr wichtige Einstellungen wie den HTTP-Port, MySQL-Passwörter und MinIO-Passwörter konfigurieren. Standardmäßig läuft RAGFlow auf Port 80. Falls ihr einen anderen Port verwenden möchtet, könnt ihr die docker-compose.yml Datei bearbeiten:
Befehl: nano docker/docker-compose.yml
Sucht nach der Zeile 80:80 und ändert sie zu <EUREM_PORT>:80, z.B. 8080:80 für Port 8080.
Ein weiterer wichtiger Punkt: RAGFlow verwendet standardmäßig Elasticsearch als Dokumenten-Engine. Falls ihr stattdessen Infinity verwenden möchtet (eine schnellere Alternative), müsst ihr zuerst alle Container stoppen:
Befehl: docker compose -f docker-compose.yml down -v
Warnung: Der Parameter -v löscht die Docker-Container-Volumes, und alle vorhandenen Daten werden gelöscht. Stellt sicher, dass ihr wirklich alle Daten löschen möchtet, bevor ihr diesen Befehl ausführt.
Dann setzt ihr in der .env Datei:
Befehl: echo "DOC_ENGINE=infinity" | sudo tee -a docker/.env
Und startet die Container neu:
Befehl: docker compose -f docker-compose.yml up -d
Für meine zwei RTX A6000 GPUs habe ich die GPU-Beschleunigung bereits in Phase 3 aktiviert. Falls ihr das noch nicht gemacht habt, könnt ihr es jetzt nachholen:
Befehl: echo "DEVICE=gpu" | sudo tee -a docker/.env
Und die Container neu starten:
Befehl: docker compose -f docker-compose.yml restart
Phase 6: Erste Dokumente hochladen und analysieren
Nachdem RAGFlow erfolgreich gestartet wurde, kann ich jetzt die ersten Dokumente hochladen und analysieren. Ich öffne RAGFlow im Browser und logge mich ein (beim ersten Start müsst ihr ein Konto erstellen).
Die Benutzeroberfläche von RAGFlow ist sehr intuitiv:
-
Knowledge Bases: Hier erstellt ihr Wissensbasen für eure Dokumente
-
Upload Documents: Hier könnt ihr PDFs, Word-Dateien, Excel-Dateien, Bilder und mehr hochladen
-
Chat: Hier könnt ihr Fragen zu euren Dokumenten stellen
-
Settings: Hier konfiguriert ihr LLM-Einstellungen, Chunking-Templates und mehr
Für einen ersten Test erstelle ich eine neue Knowledge Base und lade ein PDF-Dokument hoch. RAGFlow verarbeitet das Dokument automatisch, erstellt Chunks und indiziert den Inhalt. Nach der Verarbeitung kann ich Fragen zum Dokument stellen und erhalte Antworten mit Quellenangaben.
Tipp: RAGFlow unterstützt verschiedene Chunking-Templates, die ihr je nach Dokumenttyp auswählen könnt. Für technische Dokumente empfehle ich das „Technical Document“ Template, für allgemeine Texte das „General“ Template.
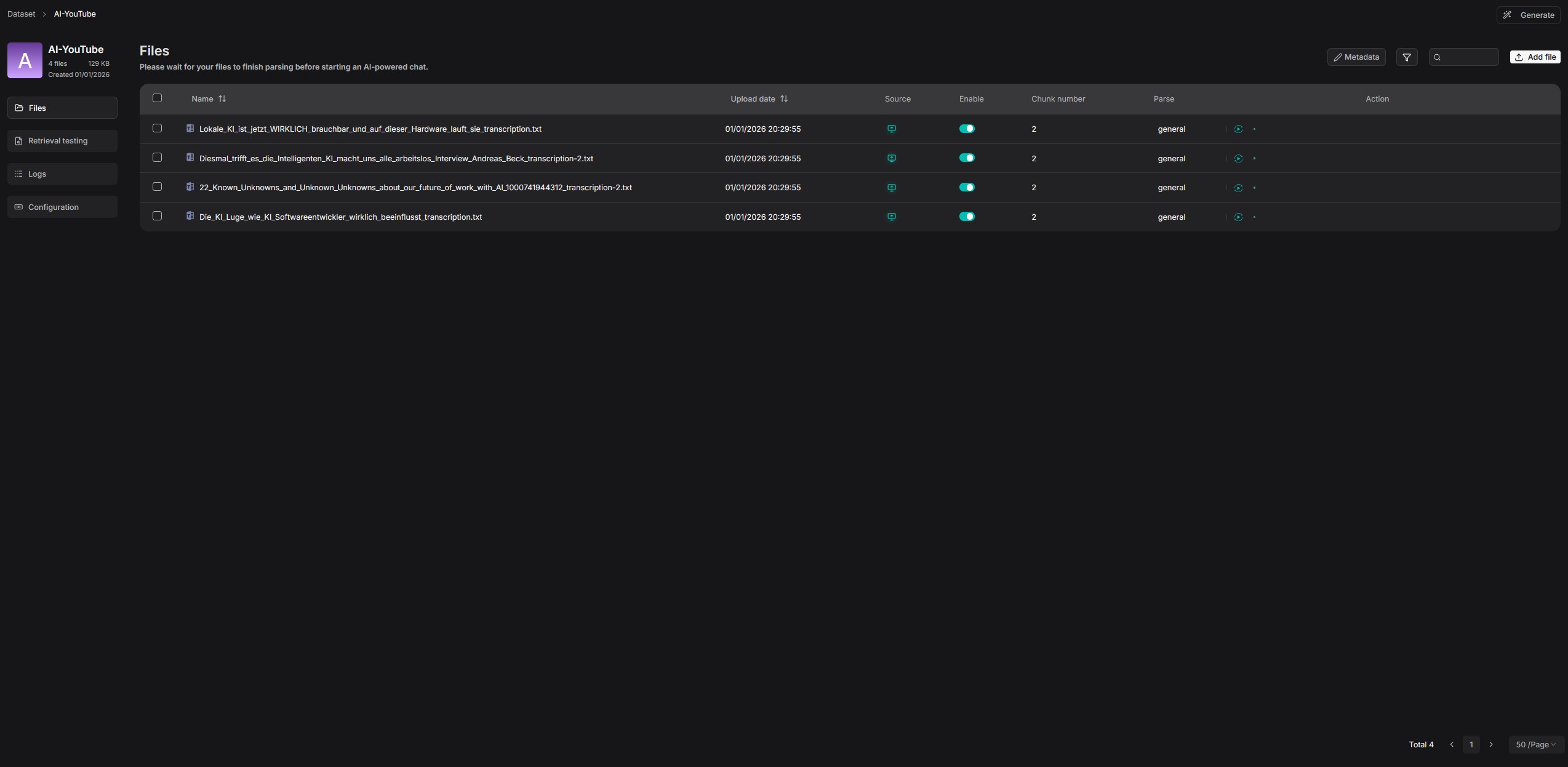
RAGFlow – dataset documents
Troubleshooting: Häufige Probleme und Lösungen
In meiner Zeit mit RAGFlow auf dem Ubuntu Server bin ich auf einige typische Probleme gestoßen. Hier sind die häufigsten und wie ich sie gelöst habe:
-
„vm.max_map_count“ Fehler: Elasticsearch benötigt einen erhöhten Wert für
vm.max_map_count. Setzt ihn auf mindestens 262144 mitsudo sysctl -w vm.max_map_count=262144und fügt ihn zur/etc/sysctl.confhinzu, damit die Einstellung nach einem Neustart erhalten bleibt. -
Container starten nicht: Prüft die Logs mit
docker compose logs. Häufig liegt das Problem an fehlenden Umgebungsvariablen oder Port-Konflikten. Prüft auch, ob Port 80 bereits von einem anderen Service verwendet wird. -
GPU wird nicht erkannt: Falls der Befehl
docker run --rm --gpus all nvidia/cuda:12.0-base-ubuntu22.04 nvidia-smieinen Fehler wiecould not select device driver "" with capabilities: [[gpu]]zurückgibt, obwohlnvidia-smiauf dem Host funktioniert, fehlt das NVIDIA Container Toolkit. Installiert es mit den Befehlen aus Phase 1 und führt danachsudo nvidia-container-toolkit q --setupundsudo systemctl restart dockeraus. Wichtig: Nach dem Neustart von Docker müsst ihr euch möglicherweise neu einloggen oder einen neuen Terminal öffnen. -
Fehler bei apt-get update nach NVIDIA Container Toolkit Installation: Falls
apt-get updateFehler wie „404 Not Found“ oder HTML-Inhalt in der Fehlermeldung zeigt, wurde die Repository-Liste nicht korrekt erstellt. Dies passiert häufig, wenn die Distribution-Variable nicht korrekt gesetzt wurde. Lösung: Löscht die fehlerhafte Datei mitsudo rm /etc/apt/sources.list.d/nvidia-container-toolkit.listund verwendet dann den stabilen Pfad aus Phase 1:curl -fsSL https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list. Danach solltesudo apt-get updatewieder funktionieren. -
LLM API-Key Fehler: Prüft die
service_conf.yaml.templateDatei und stellt sicher, dass der API-Key korrekt eingetragen ist. Nach Änderungen müsst ihr die Container neu starten. -
Speicherprobleme: RAGFlow benötigt ausreichend RAM für Elasticsearch. Bei größeren Dokumentensammlungen empfehle ich mindestens 32 GB RAM. Prüft die Speichernutzung mit
docker stats. -
Dokumente werden nicht verarbeitet: Prüft die Logs des RAGFlow-Containers mit
docker logs -f docker-ragflow-cpu-1. Häufig liegt das Problem an fehlenden LLM API-Keys oder Netzwerkproblemen beim Zugriff auf externe LLM-Services. -
Firewall blockiert den Zugriff: Falls eine Firewall aktiv ist, müsst ihr Port 80 (oder euren konfigurierten Port) freigeben:
sudo ufw allow 80oder entsprechenden iptables-Regeln.
Container verwalten
Um den Status aller Container zu prüfen:
Befehl: docker compose ps
Um alle Container zu stoppen (ohne sie zu löschen):
Befehl: docker compose -f docker-compose.yml stop
Um alle Container zu starten:
Befehl: docker compose -f docker-compose.yml start
Um alle Container zu entfernen (aber Volumes zu behalten):
Befehl: docker compose -f docker-compose.yml down
Um alle Container und Volumes zu entfernen (löscht alle Daten):
Befehl: docker compose -f docker-compose.yml down -v
Um die Logs eines bestimmten Containers anzuzeigen:
Befehl: docker logs -f docker-ragflow-cpu-1
Um die Ressourcennutzung aller Container zu sehen:
Befehl: docker stats
Rollback: RAGFlow wieder entfernen
Falls ihr RAGFlow komplett vom Server entfernen möchtet, führt auf dem System folgende Befehle aus:
Zuerst stoppt ihr alle Container:
Befehl: cd ragflow/docker
Befehl: docker compose -f docker-compose.yml down -v
Falls ihr auch die Container-Images entfernen möchtet:
Befehl: docker images | grep ragflow
Befehl: docker rmi <IMAGE_ID>
Um auch nicht verwendete Docker-Container und Images zu entfernen:
Befehl: docker system prune -a
Falls ihr auch das geklonte Repository entfernen möchtet:
Befehl: cd ~
Befehl: rm -rf ragflow
Wichtiger Hinweis: Diese Befehle entfernen alle RAGFlow Container, Images und Daten. Stellt sicher, dass ihr wirklich alles entfernen möchtet und wichtige Daten gesichert habt, bevor ihr diese Befehle ausführt.
Zusammenfassung & Fazit
Die Installation von RAGFlow auf meinem Ubuntu Server mit zwei NVIDIA RTX A6000 GPUs ist erstaunlich unkompliziert. In etwa 30-45 Minuten habe ich ein vollständiges RAG-System eingerichtet, das komplexe Dokumente analysieren und intelligente Fragen beantworten kann.
Was mich besonders begeistert: Die Performance der beiden RTX A6000 GPUs wird voll ausgenutzt, und die Docker-basierte Installation macht das Setup deutlich einfacher als eine manuelle Installation. RAGFlow bietet eine professionelle Lösung für die Dokumentenanalyse, die sowohl für kleine Teams als auch für größere Unternehmen geeignet ist.
Besonders praktisch finde ich auch, dass RAGFlow mit template-basiertem Chunking arbeitet, was die Qualität der Dokumentenverarbeitung deutlich verbessert und Betriebe hier über die Templates einen Art-Standard für sich etablieren können. Die gegroundeten Zitate mit Quellenangaben machen es einfach, nachzuvollziehen, aus welchem Dokument und welchem Abschnitt die Informationen stammen – das ist besonders wichtig für vertrauenswürdige AI-Anwendungen.
Für Teams oder Entwickler, die ein professionelles RAG-System benötigen, ist RAGFlow eine perfekte Lösung: Ein zentraler Server mit voller GPU-Power, auf dem Dokumente intelligent analysiert und durchsucht werden können. Die intuitive Web-Oberfläche macht es einfach, Dokumente hochzuladen und Fragen zu stellen, während die API eine nahtlose Integration in bestehende Anwendungen ermöglicht.
Falls ihr Fragen habt oder auf Probleme stoßt, schaut gerne in die offizielle RAGFlow Dokumentation oder die RAGFlow GitHub Repository. Die Community ist sehr hilfsbereit, und die meisten Probleme lassen sich schnell lösen.
Nächster Schritt: Erweiterte Konfiguration und Integration
Ihr habt jetzt RAGFlow erfolgreich installiert und die ersten Dokumente analysiert. Die Grundinstallation funktioniert, aber das ist erst der Anfang. Der nächste Schritt ist die Konfiguration für eure spezifischen Anforderungen.
RAGFlow bietet viele Konfigurationsmöglichkeiten für Production-Einsätze: Custom Chunking-Templates erstellen, verschiedene LLM-Provider lokal oder public konfigurieren, API-Integrationen einrichten oder mehrere Knowledge Bases für verschiedene Projekte verwalten. Die Dokumentation zeigt euch, wie ihr diese Einstellungen für eure Workloads optimiert.
Besonders interessant finde ich auch die Agent-Funktionen von RAGFlow, die es ermöglichen, komplexe Workflows zu erstellen und Dokumente automatisch zu verarbeiten. Mit der Unterstützung für Confluence, S3, Notion, Discord und Google Drive kann RAGFlow auch direkt mit bestehenden Datenquellen verbunden werden.
Viel Erfolg beim Experimentieren mit RAGFlow auf eurem Ubuntu Server. Ich bin gespannt, welche Anwendungen ihr damit entwickelt! Lasst es mich und meine Leser hier in den Kommentaren wissen.


{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…