


Nous Research hat seinem quelloffenen Hermes Agent mit dem „Surface Release“ (Version 0.16.0, Juni 2026) etwas spendiert, auf das ich lange gewartet habe: eine echte native Desktop-App für macOS, Linux und Windows. Bisher war Hermes Agent ein Kommandozeilen- und Gateway-Werkzeug. Aber jetzt gibt es mit dem neuen Release eine vollwertige grafische Oberfläche mit Ein-Klick-Installer und Selbstaktualisierung. Grund genug, die App auf meinem Windows-Rechner zu installieren und dabei eine ganz konkrete These aus meinem kommenden Buch praktisch zu überprüfen.
Die These, die ich testen will
Die Desktop-App lässt sich in zwei Betriebsarten nutzen. Entweder verbindet sie sich als schlanker Client mit einem Hermes Agent, der zentral auf einem Server läuft oder Ihr installiert sie vollständig lokal, sodass der Agent samt Gedächtnis, Skills und Konfiguration im eigenen Benutzerkontext arbeitet. Meine Behauptung: Für den Unternehmenseinsatz ist die volle lokale Installation mit angebundenem zentralem Inferenzserver aus Governance-Sicht der sauberste Weg. Der Grund liegt in der Architektur von Hermes Agent: Gedächtnis und Benutzerprofil gibt es genau einmal pro Instanz. Teilen sich mehrere Anwender eine gemeinsame Server-Instanz, teilen sie sich damit zwangsläufig auch dasselbe Langzeitgedächtnis, dieselben gelernten Skills und dieselben hinterlegten Zugangsdaten. Bei der vollen lokalen Installation entfällt dieses Problem denn jeder Anwender hat von Haus aus durch das Betriebssystem und dessen Konfiguration sein eigenes, isoliertes Benutzerprofil.
Genau das will ich mit diesem Test belegen und gleichzeitig zwei offene Fragen klären, die ich vorab nicht sicher beantworten konnte:
- Läuft der Agent jetzt wirklich nativ unter Windows, oder zieht die App im Hintergrund weiterhin WSL2 heran?
- Liegen die Benutzerdaten tatsächlich sauber getrennt im Windows-Benutzerprofil?
Hermes Agent Desktop-App
Schritt 1: Die Desktop-App installieren
Den Installer ladet Ihr direkt von der offiziellen Projektseite herunter. Schaut dort bitte nach der jeweils aktuellen Version, da sich der Download-Pfad im Laufe der Zeit ändern kann:
Download: https://hermes-agent.nousresearch.com/desktop
Unter Windows startet Ihr anschließend die heruntergeladene Hermes-Setup.exe und folgt dem Installationsassistenten. Die App installiert sich wie jedes andere Windows-Programm und aktualisiert sich später aus der Anwendung heraus selbst.
Und damit ist die erste offene Frage schon beantwortet: Die Installation lief vollständig nativ unter Windows durch. Der Installer richtet in 16 Schritten einen eigenen Toolchain ein – uv als Paketmanager, Python 3.11, Git, Node.js, ripgrep und ffmpeg, klont das Hermes-Repository, legt ein Python-Virtual-Environment an und baut daraus die Desktop-App. An keiner Stelle war WSL2 nötig oder wurde es im Hintergrund eingerichtet. Anders als beim bisherigen reinen Kommandozeilen-Hermes läuft die Desktop-App also nativ unter Windows.
Schritt 2: Den eigenen Inferenzserver anbinden
Jetzt kommt der entscheidende Teil für die Datensouveränität: Die App rechnet nicht selbst, sondern holt sich die Modell-Leistung über das Netzwerk von meinem eigenen Inferenzserver. Auf diesem stellt Ollama (oder alternativ vLLM) die Modelle über eine OpenAI-kompatible Schnittstelle bereit. Die Workstation selbst braucht dafür keine eigene GPU.
Im Einrichtungsassistenten der App wählt Ihr unter den Anbietern die Kachel „Local / custom endpoint (self-hosted)“ und tragt die Adresse Eures Servers ein, bei einem Ollama-Server also http://<Server-IP>:11434/v1. Schön zu sehen: Der lokale, souveräne Weg ist hier eine vollwertige, gleichberechtigte Anbieter-Kachel und kein versteckter Config-Hack. Die Auswahl steht nur nicht als „RECOMMENDED“ ganz oben. Souveränität ist eben eine bewusste Entscheidung.
Die Stolperstelle: leere Modell-Liste trotz verbundenem Endpunkt
An dieser Stelle bin ich in ein kleines Problem gelaufen, das ich Euch ersparen möchte, denn sie kostet sonst unnötig Nerven. Die App meldete zwar „Local / custom endpoint connected“, verlangte aber gleichzeitig „Custom endpoint needs an API key – set it up to choose a model“, ohne ein sichtbares Feld für genau diesen Key anzubieten. Die Folge: Die Modell-Liste blieb leer, und das Hauptmodell ließ sich nicht setzen sondern es wurde das letzte eingerichtete Modell von meinem Ollama Inferenz-Server geladen.
Der Hintergrund ist schnell erklärt: Hermes spricht Ollama über die OpenAI-kompatible Schnittstelle an, und dieser Standard verlangt formal immer einen API-Key-Wert, auch dann, wenn Ollama gar keine Authentifizierung prüft. Solange das Feld leer bleibt, kann Hermes die Modell-Liste nicht abrufen, und ohne Modell-Liste gibt es nichts auszuwählen. Im Issue-Tracker des Projekts finden sich dazu bereits verwandte Meldungen (etwa die Issues #20815 und #16730), die genau diese Verwechslung zwischen einem keylosen lokalen Endpunkt und einem vermeintlich fehlenden Credential beschreiben. Der grafische Einrichtungsweg ist hier also (Stand v0.16.0) schlicht noch nicht ganz Perfekt.
Die Lösung: das Modell über die PowerShell setzen
Der zuverlässige Weg führt an der grafischen Oberfläche vorbei über die mitinstallierte Kommandozeile. Praktischerweise teilen sich CLI und Desktop-App dieselbe Konfiguration. Öffnet eine Windows PowerShell und startet den Modell-Assistenten:
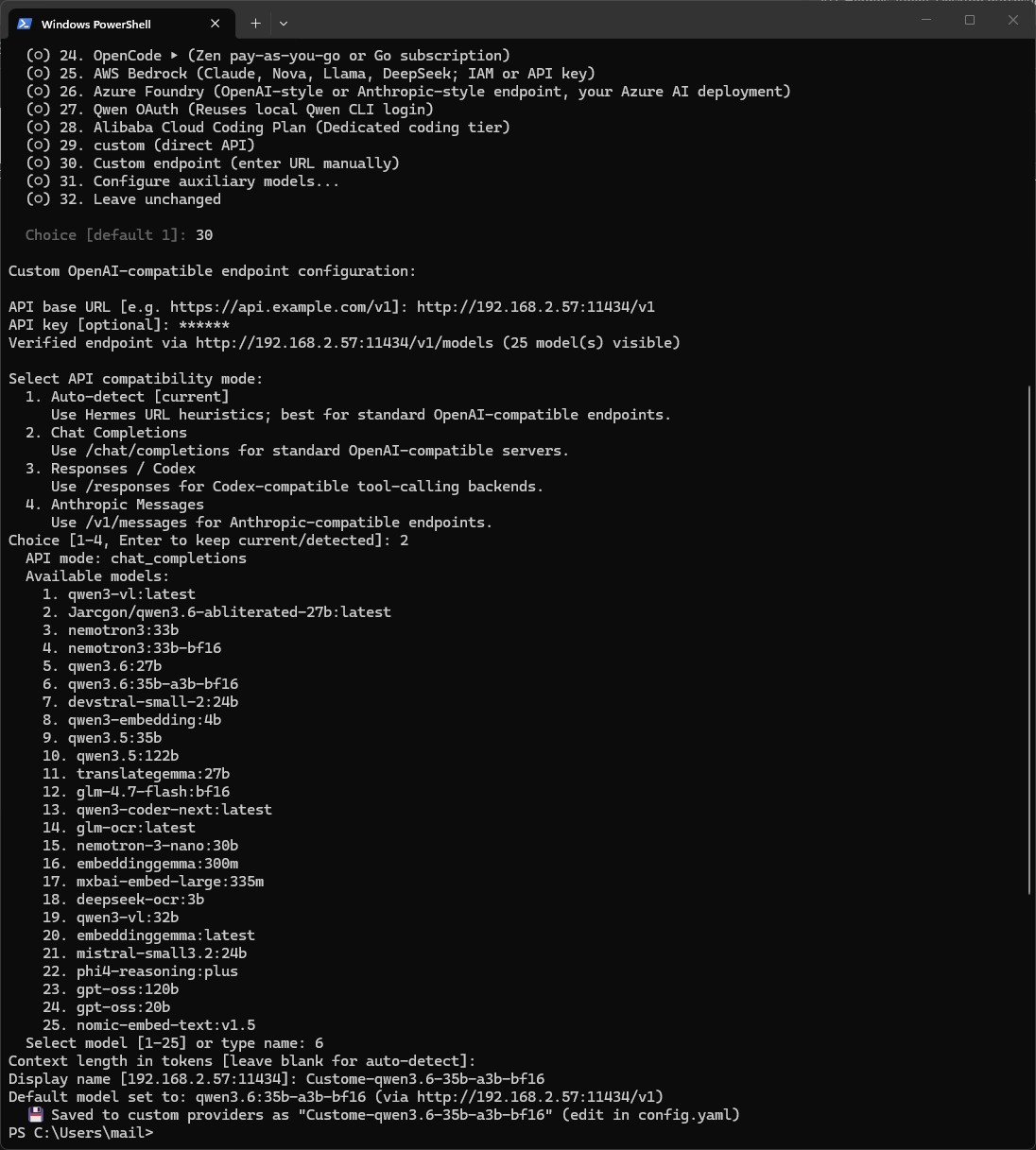
Befehl: hermes model
In der Anbieter-Liste wählt Ihr den Eintrag „Custom endpoint (enter URL manually)“ (bei mir war das Nummer 30). Achtet darauf, nicht versehentlich „Ollama Cloud“ zu erwischen. Das ist der cloudgehostete Dienst auf ollama.com und nicht Euer eigener Server. Anschließend führt Euch der Assistent durch die Eingaben:
- Als API base URL tragt Ihr
http://<Server-IP>:11434/v1ein, bei mirhttp://192.168.2.57:11434/v1. - Beim API key genügt der Platzhalter
ollama. Ollama prüft ihn nicht, aber das Feld will einen Wert. Dieser Platzhalter ist kein Bruch der Souveränität, er wird nirgends validiert und verlässt Euer Netzwerk nicht. - Als API compatibility mode wählt Ihr „Chat Completions“, denn Ollama bedient den Endpunkt
/v1/chat/completions. - Danach zeigt der Assistent alle auf dem Server verfügbaren Modelle an und Ihr wählt Euer gewünschtes aus – in meinem Fall
qwen3.6:35b-a3b-bf16.
Hermes Agent Desktop-App – PowerShell
Der Assistent verifiziert den Endpunkt sofort. Bei mir quittierte er das mit „Verified endpoint via http://192.168.2.57:11434/v1/models (25 model(s) visible)“ und speicherte einen vollständigen Custom-Provider-Eintrag in die config.yaml. Zur Kontrolle prüft Ihr mit einem weiteren Befehl Endpunkt, Zugangsdaten und Modell in einem Rutsch:
Befehl: hermes doctor
Nach einem Neustart der Desktop-App ist die Sperre verschwunden: Das Modell steht in der Statusleiste, lässt sich dort umschalten, und der Agent antwortet über meinen eigenen Server. Genau dieser kleine Umweg über die PowerShell ist aktuell der entscheidende Kniff, an dem die rein grafische Einrichtung noch scheitert.
Warum diese Aufstellung aus Governance-Sicht die beste ist
Mit diesem Aufbau bekommt Ihr zwei Dinge gleichzeitig: strikte Trennung der Benutzerkontexte und zentrale, GPU-gestützte Modellbereitstellung. Das Gedächtnis bleibt das Modell genau eines Menschen, die Skills und Konversationen verschiedener Anwender vermischen sich nicht, und die API-Schlüssel jedes Anwenders liegen ausschließlich in seinem eigenen Benutzerkontext. Diese findet ihr typischerweise im Windows-Benutzerprofil unter C:\Users\<EuerName>\.hermes. Die Isolation ist damit der Normalzustand und muss nicht erst über separate Profile oder Container pro Mitarbeiter hergestellt werden.
Über das Netzwerk wandern ausschließlich die Inferenz-Anfragen an meinen eigenen Ollama- bzw. vLLM-Endpunkt – also an Infrastruktur, die ich vollständig kontrolliere. Weder Prompts noch Gesprächsinhalte noch das Gedächtnis verlassen mein Netzwerk in Richtung eines kommerziellen KI-Anbieters. Auch die Verantwortlichkeit ist sauber zugeordnet: Die Agentendaten jedes Anwenders unterliegen denselben Richtlinien wie sein übriges Benutzerkonto, sodass Festplattenverschlüsselung, Datensicherung und das Offboarding beim Ausscheiden eines Mitarbeiters automatisch mitgreifen.
Zur Einordnung der Gegenrichtung: Sobald sich mehrere Anwender denselben Hermes Agent auf einem Server teilen, verschwimmt die Trennung ihrer Daten auf Profilebene, denn Gedächtnis, Skills und Zugangsdaten gehören der Instanz, nicht dem einzelnen verbundenen Benutzer. Wer bewusst ein über alle Anwender hinweg geteiltes „Team-Gedächtnis“ möchte, ist mit der Server-Instanz richtig beraten – aber eben im klaren Wissen, dass es dort keine Trennung der Benutzerdaten gibt.
Und noch ein praktischer Hinweis aus der Erfahrung: Wenn viele lokal installierte Agenten gleichzeitig auf einen zentralen Inferenzserver zugreifen, entsteht echter Parallelbetrieb. Genau hier ist Ollama nicht in seinem Element – für viele gleichzeitige Sitzungen ist vLLM die deutlich leistungsstärkere Wahl auf dem zentralen Endpunkt.
Das Ergebnis
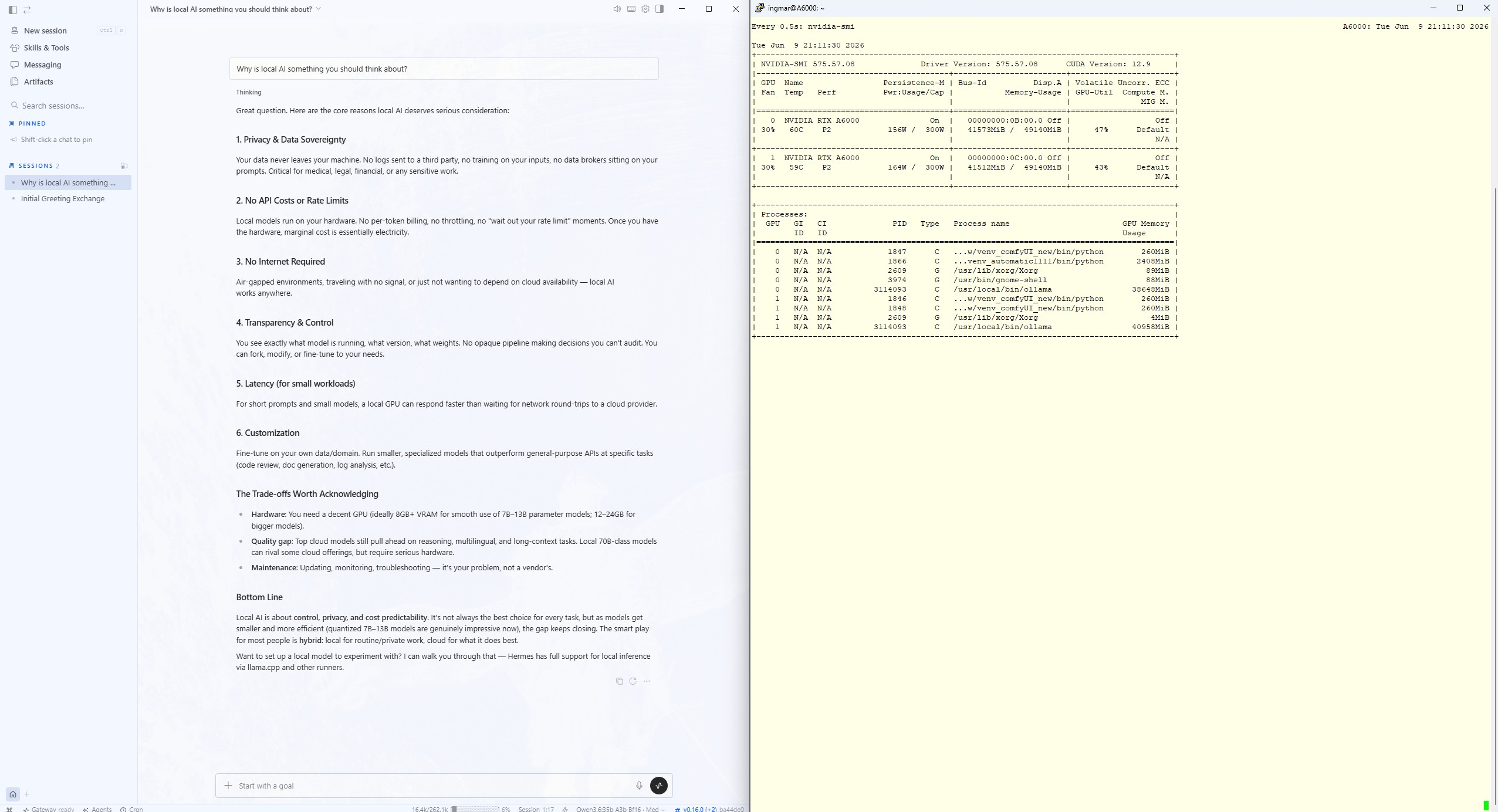
Links die native Hermes-Desktop-App unter Windows, die über mein lokales Modell antwortet; rechts zeigt nvidia-smi auf dem A6000-Server die laufenden Ollama-Prozesse mit belegtem VRAM.
Hermes Agent Desktop-App – Lokale Inferenz
C:\Users\<EuerName>\.hermes, und der Agent antwortet über mein lokales Modell qwen3.6:35b-a3b-bf16. Dass die Inferenz tatsächlich auf meinem eigenen Server stattfindet, belegt der Blick auf die beiden RTX A6000: Während der Agent antwortet, laufen dort die Ollama-Prozesse und belegen den VRAM – kein Byte geht an einen Cloud-Anbieter. Der einzige Wermutstropfen war die grafische Einrichtung des lokalen Modells, die sich erst über den oben gezeigten PowerShell-Umweg lösen ließ.Fazit
Die neue Desktop-App macht Hermes Agent für den Alltag deutlich zugänglicher, ohne die Souveränität aufzugeben – vorausgesetzt, Ihr behaltet die Architektur im Blick. Der Test bestätigt meine These: Volle lokale Installation pro Arbeitsplatz, Inferenz zentral auf dem eigenen Server. Das ist die saubere Kombination aus Komfort, Datentrennung und Kontrolle. Den einzigen Stolperstein, die grafische Modellauswahl, umgeht Ihr aktuell zuverlässig über die PowerShell. Wie handhabt Ihr die Trennung der Benutzerkontexte bei Euren lokalen Agenten? Schreibt es mir gerne in die Kommentare.







{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…