
Im ersten Teil habe ich cuFOLIO headless als Skript auf meinem Dual-A6000-Server zum Laufen gebracht. Ein kleines run_cvar.py, ein uv run, und die Ergebnisse liegen sauber im Ordner results/. Für Automatisierung und Versionierung ist das schon ordentlich. Eine kleine Datenbank für die einzelnen Läufe wäre der logische nächste Schritt. Darum geht es mir hier aber nicht. Mir geht es um den Einstieg in ein Finanzthema, die Portfolio-Optimierung. Und die Hürde liegt dabei nicht in der Kommandozeile. Als Techniker komme ich mit der Shell bestens zurecht. Was mich am Anfang ausgebremst hat, waren die Finanzbegriffe und vorallem den Einstieg zu finden. Genau hier setzt dieser zweite Teil meiner kleinen Serie an die ich in ihrem Umfang also Länge noch nicht abschätzen kann. Ich habe dem run_cvar.py Optimierer-Skript an diesem Wochenende eine grafische Oberfläche verpasst, die cuFOLIO Web-UI. Sie ist mehrsprachig, erklärt jeden Begriff per Tooltip, vergleicht zwei Läufe und fährt mit einem Sweep viele Szenarien über eine oder beide A6000.
Wer den ersten Teil noch nicht kennt, findet ihn hier: cuFOLIO ohne Jupyter: GPU-Portfolio-Optimierung per Skript auf Dual RTX A6000.
Der gesamte Code samt Oberfläche liegt hier in meinem Repository: cuFOLIO auf GitHub.
Kurz zur Erinnerung. cuFOLIO ist ein Blueprint von NVIDIA für Portfolio-Optimierung auf der GPU. Es verteilt Kapital risikooptimal über einen Korb von Wertpapieren. Als Risikomaß dient CVaR, der Conditional Value-at-Risk. CVaR schaut gezielt auf die schlechten Tage und fragt, wie groß der Verlust im Schnitt ist, wenn es richtig schlecht läuft. Den ganzen Hintergrund dazu habe ich im ersten Teil ausführlich erklärt.
Warum eine cuFOLIO Web-UI?
Das Skript ist mächtig, aber wortkarg. Jeder Parameter ist ein nackter Kommandozeilen-Schalter ohne Erklärung. Wer wissen will, was w_min oder die Konfidenz bewirken, muss in den Code schauen. Für mich ist nicht das Tippen das Problem, sondern die Bedeutung dahinter.
Die Oberfläche dreht das um. Jedes Feld trägt einen kurzen Tooltip, der den Begriff in einem Satz erklärt. Bei der Konfidenz steht zum Beispiel, dass 0,95 die schlimmsten 5 Prozent der Tage betrachtet. Beim Hebel, dass 1,6 ein Brutto-Engagement von 160 Prozent bedeutet. So kann auch jemand ohne Finanzhintergrund sinnvoll an den Reglern drehen bzw. deutlich einfacher habe ich mir gedacht.
Wichtig ist mir dabei: Die Oberfläche ersetzt das Skript nicht, sie sitzt obendrauf. Jeder Klick schreibt im Hintergrund eine Konfigurationsdatei und ruft dasselbe run_cvar.py auf wie zuvor. Die Reproduzierbarkeit aus Teil 1 bleibt also vollständig erhalten. Du bekommst nur einen bequemen Weg, das Python Skript run_cvar.py über eine Web-Oberfläche zu bedienen.
Gebaut ist das Ganze mit Gradio. Gradio ist ein Python-Framework, mit dem sich aus wenig Code eine Web-Oberfläche erzeugen lässt und ich mich damit eben auskenne. Alle sichtbaren Texte und Tooltips liegen ausgelagert in einer language.yml. YAML ist ein gut lesbares Format für Konfigurationsdateien. Dadurch lässt sich die cuFOLIO Web-UI zwischen Deutsch und Englisch umschalten, und eine weitere Sprache wäre nur ein zusätzlicher Block in dieser Datei. Das kann man sich recht einfach mit einem LLM übersetzen lassen wenn man mag.
Die cuFOLIO Web-UI starten
Die Oberfläche läuft im selben Container wie das Skript aus Teil 1. Neu ist nur, dass der Container jetzt einen Port nach außen reicht und dass im Container statt run_cvar.py die Datei app.py gestartet wird. Ein zweites Programm brauchst Du dafür nicht. app.py läuft im Container, im selben Terminal, in dem Du den Container startest. Ein zweites Terminal brauchst Du nur auf dem Host, um die Dateien abzulegen und die Firewall zu setzen.
Lege zuerst die drei Dateien auf dem Host in den Repo-Ordner, also dorthin, wo schon run_cvar.py aus Teil 1 liegt. Konkret kommen app.py und language.yml neben run_cvar.py nach ~/cufolio-projekt/cuFOLIO/. Durch das Mount tauchen sie im Container automatisch unter /workspace/host/cuFOLIO/ auf.
Läuft auf dem Host eine Firewall, gibst Du den Port frei. Das ist ein Host-Befehl, kein Container-Befehl. Mach das nur, wenn Du weißt, was Du tust.
Befehl: sudo ufw allow 7860/tcp
Jetzt wechselst Du auf dem Host in den Projektordner. Das ist wichtig, denn das gleich folgende -v "$PWD":/workspace/host hängt genau dieses Verzeichnis in den Container ein. Es muss derselbe Ordner sein wie in Teil 1.
Befehl: cd ~/cufolio-projekt
Dann startest Du den Container. Der einzige Unterschied zu Teil 1 ist das ergänzte -p 7860:7860, das den Port aus dem Container an den Host weiterreicht.
Befehl: docker run --gpus all -it --rm -p 7860:7860 -v "$PWD":/workspace/host --ipc=host nvcr.io/nvidia/pytorch:25.10-py3
Ab hier bist Du im Container. Wechsle in den Repo-Ordner.
Befehl: cd /workspace/host/cuFOLIO
Ist der Container frisch gestartet, fehlt darin noch uv. Du installierst es einmal und lädst es in die Shell. Die virtuelle Umgebung aus Teil 1 liegt durch das Mount schon auf dem Host und wird weiterverwendet.
Befehl: curl -LsSf https://astral.sh/uv/install.sh | sh
Befehl: source "$HOME/.local/bin/env"
Zuletzt startest Du die Oberfläche. Das --with zieht Gradio und den YAML-Parser nur für diesen Lauf dazu, ganz ohne feste Installation.
Befehl: uv run --with gradio --with pyyaml python app.py
Danach erreichst Du die cuFOLIO Web-UI im Browser unter der IP-Adresse Deines Servers auf Port 7860, bei mir also http://192.168.2.57:7860. Solange das Terminal mit dem Container offen bleibt, läuft die Oberfläche. Mit Strg+C beendest Du sie wieder.
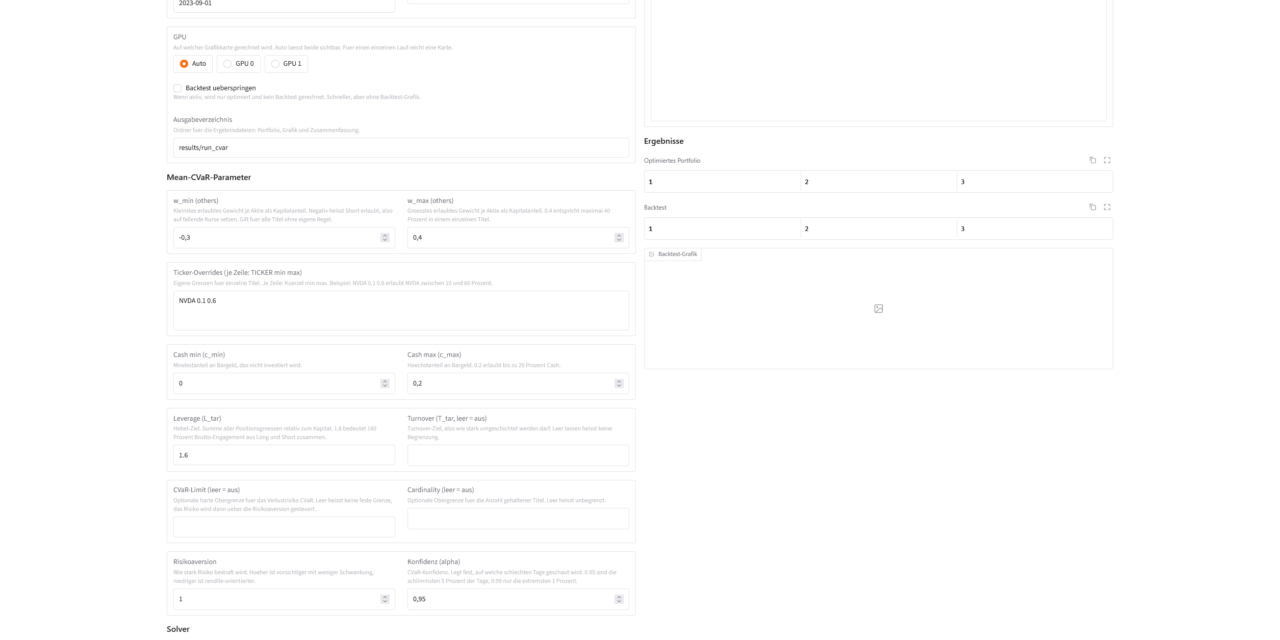
Hier ein Screenshot der Obefläche wie diese nach dem Start aussieht.
cuFOLIO Web-Interface
Reiter Einzellauf: die Steuerzentrale
Der erste Reiter mit dem Namen „Einzellauf“ ist die Oberfläche für die volle Konfiguration eines Laufes. Hier setzt Du alle Parameter, die das Skript auch über die Kommandozeile kennt. Den Datensatz, die Anzahl der KDE-Szenarien, den Optimierungs- und den Backtest-Zeitraum, die GPU, die Mean-CVaR-Parameter und die Solver-Einstellungen. Jedes Feld hat seine Beschreibung.
Ein paar Funktionen heben den Komfort über das reine Skript hinaus.
Config speichern und laden. Hast Du ein Setup eingestellt, sicherst Du es unter einem sprechenden Namen Deiner Wahl im YAML Format als Datei lokal. Über das DropDown „Gespeicherte Configs“ holst Du gespeicherte Konfigurationen mit wenigen Klicks zurück. So sammelst Du Dir nach und nach eine Bibliothek benannter Szenarien.
Fester Seed für reproduzierbare Läufe. Der Seed ist der Startwert für den Zufall bei der Szenarien-Erzeugung. Setzt Du ihn fest, liefert derselbe Lauf exakt dasselbe Ergebnis. Lässt Du das Feld leer, zieht sich jeder Lauf einen individuellen Seed als Zufallszahl. Aber genau dieser feste Seed den Du einstellen kannst macht einen Vergleich bei Änderungen der anderen Parameter erst vergleichbar und somit aussagekräftig.
GPU prüfen und Lauf starten. Ein Knopf führt den schnellen --check aus und zeigt, ob beide Karten und der Stack überhaupt sichtbar sind. Der Startknopf wiederum löst den eigentlichen Lauf aus. Das Log läuft live mit, während im Hintergrund run_cvar.py arbeitet.
Nach dem Lauf erscheinen rechts die Ergebnisse. Das optimierte Portfolio als Tabelle mit Titel, Richtung und Gewicht. Der Backtest mit Sortino-Ratio und Max Drawdown. Und die Backtest-Grafik. Die Sortino-Ratio misst die Rendite im Verhältnis zum Verlustrisiko, höher ist besser. Der Max Drawdown ist der größte zwischenzeitliche Verlust vom Höchststand aus, niedriger ist besser.
Zwei Läufe vergleichen
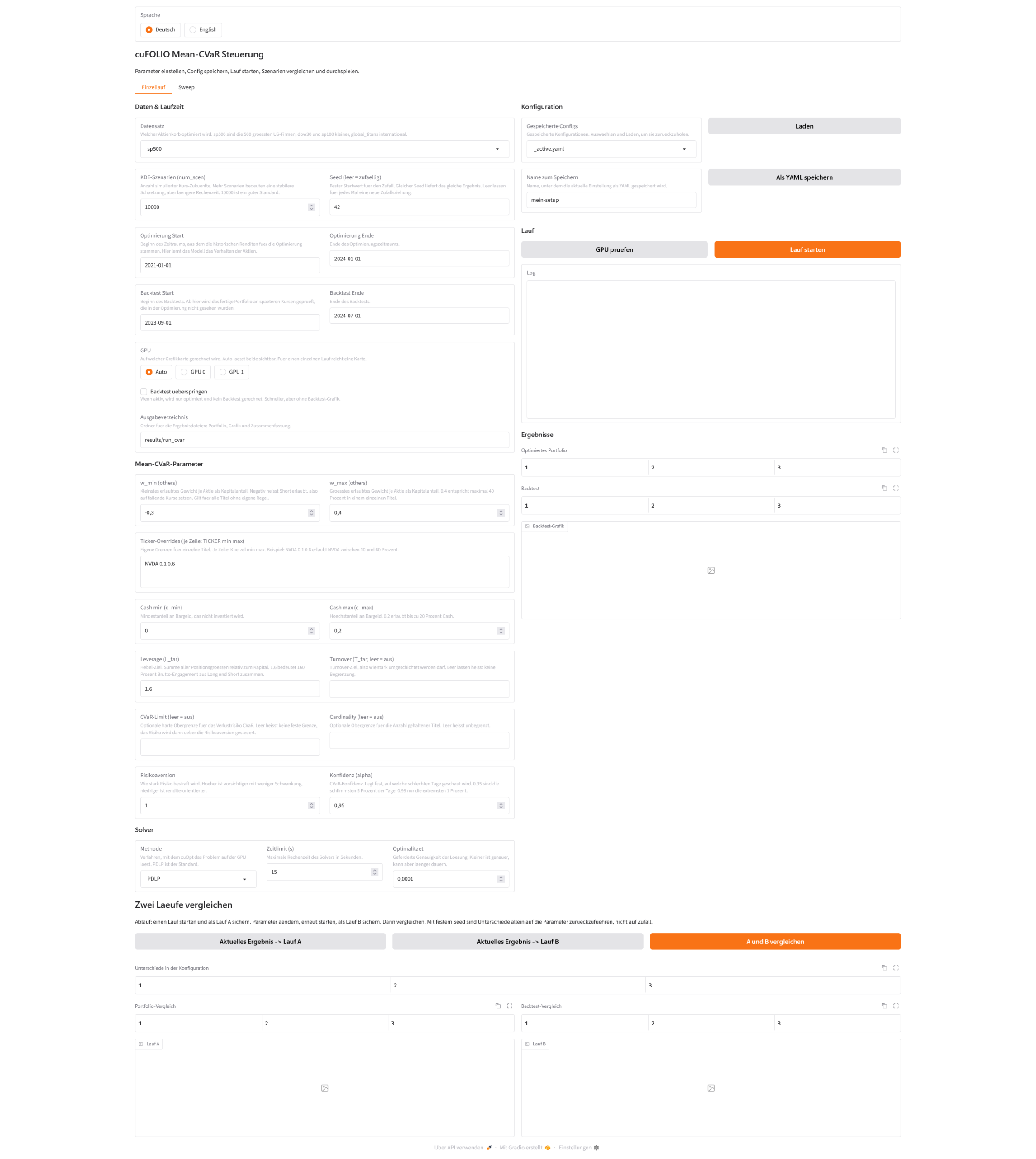
Unter all diesen Parametern und ihrern Konfigurationsmöglichktein sitzt das Menü für den Vergleich von zwei Läufen. Der Ablauf ist eigentlich ganz einfach gehalten. Du startest einen Lauf und sicherst ihn als Lauf A durch drücken auf den Button „Aktuelles Ergebnis -> Lauf A“. Dann änderst Du einen Parameter, startest erneut und sicherst als Lauf B. Ein Klick auf Vergleichen Butteon „A und B vergleichen“ stellt beide gegenüber.
Die Oberfläche zeigt dann die drei Ergebnisse nebeneinander. Welche Parameter sich unterschieden haben. Wie sich die Gewichte je Titel verschoben haben, inklusive der Differenz. Und wie sich Sortino und Drawdown verändert haben. Beide Backtest-Grafiken stehen daneben.
Der Clou steckt im festen Seed. Hältst Du ihn über beide Läufe gleich, sind alle Unterschiede allein auf den geänderten Parameter zurückzuführen und nicht auf den Zufall der Szenarien. Damit wird sichtbar, was ein einzelner Regler wirklich bewirkt.
Hier einmal der Vergleich von zwei Läufen bei denen ich nur den Seed-Wert verändert habe.
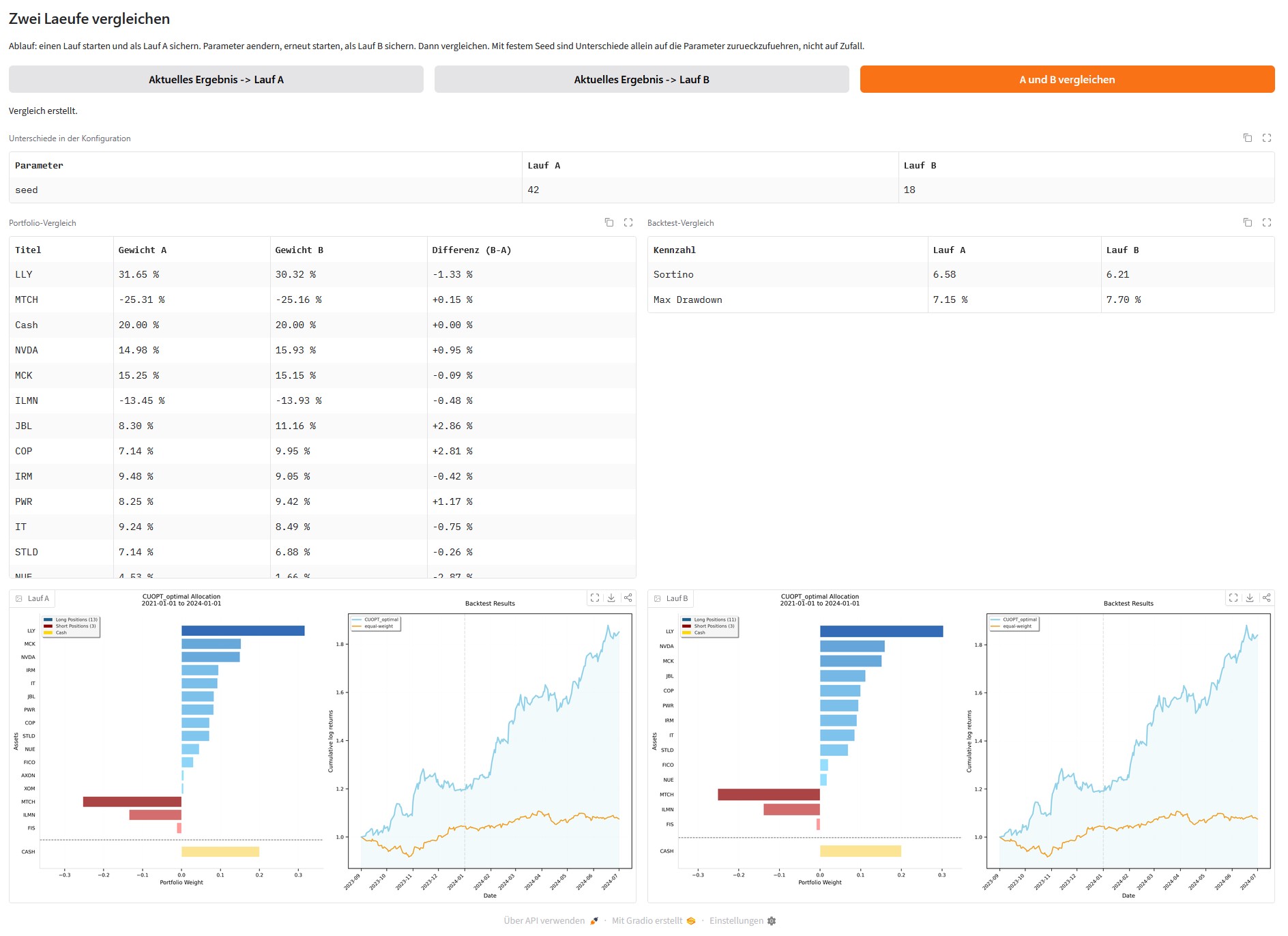
cuFOLIO web interface Vergleich
Reiter Sweep: ein Parameter, viele Werte
Der zweite Reiter beantwortet eine andere Frage. Nicht „wie sieht dieses eine Portfolio aus“, sondern „wie verändert sich das Ergebnis, wenn ich einen Regler über mehrere Werte durchspiele“. Das nennt sich Sweep, also das systematische Abfahren eines Parameters.
Die Bedienung ist bewusst schlank gehalten. Du wählst genau einen Parameter, der variiert werden soll. Du gibst die Werte mit Komma getrennt ein, etwa 0.90, 0.95, 0.99 für die Konfidenz. Und Du wählst, ob auf einer oder auf zwei Karten gerechnet wird. Sobald Du den Parameter im Auswahlfeld wechselst, trägt die Oberfläche automatisch eine sinnvolle Beispiel-Werteliste ein, die Du danach anpassen kannst. Als Basis dienen die Einstellungen aus dem Reiter Einzellauf. Nur der gewählte Parameter wird darüber gelegt. Soll heißen, Du kannst nicht mehrere Parameter gleichzeitig verändern.
Während der Sweep läuft, füllt sich eine Status-Tabelle live. Sie zeigt je Szenario die zugewiesene GPU und den Status von wartend über laufend bis fertig. Fertige Zeilen ergänzen Solve-Zeit, Sortino und Max Drawdown. Am Ende erscheint eine Galerie mit der Backtest-Grafik je Szenario, und die ganze Tabelle gibt es als CSV zum Download. Auch hier bleibt der Seed fest, damit die Unterschiede sauber auf den variierten Parameter zurückgehen.
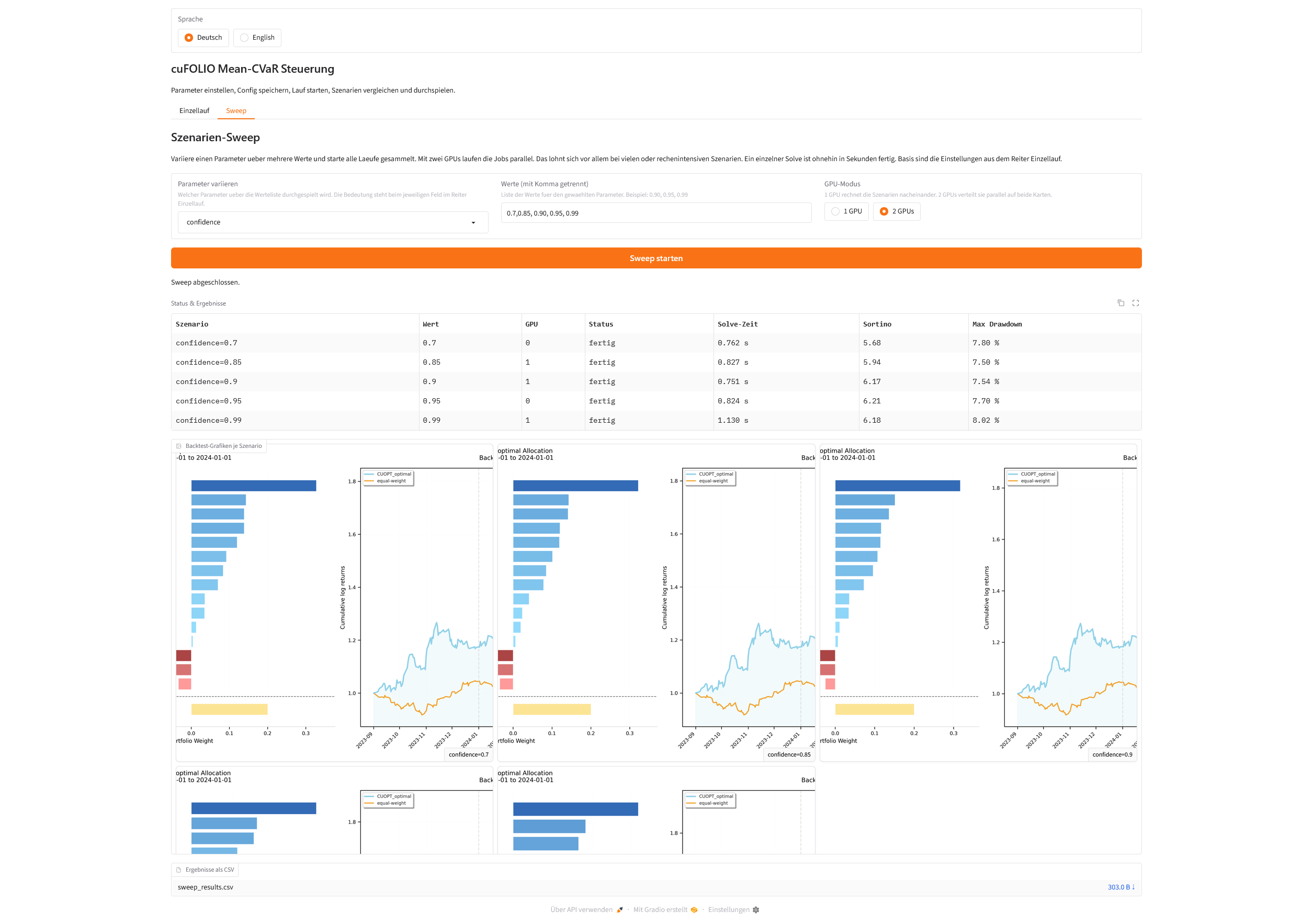
cuFOLIO sweep
Ein konkretes Beispiel ist ein Sweep über die Konfidenz mit fünf Werten von 0,7 bis 0,99, verteilt auf beide A6000:
| Szenario | Wert | GPU | Solve-Zeit | Sortino | Max Drawdown |
|---|---|---|---|---|---|
| confidence=0.7 | 0.7 | 0 | 0,762 s | 5,68 | 7,80 % |
| confidence=0.85 | 0.85 | 1 | 0,827 s | 5,94 | 7,50 % |
| confidence=0.9 | 0.9 | 1 | 0,751 s | 6,17 | 7,54 % |
| confidence=0.95 | 0.95 | 0 | 0,824 s | 6,21 | 7,70 % |
| confidence=0.99 | 0.99 | 1 | 1,130 s | 6,18 | 8,02 % |
cuFOLIO Web-UI · Sweep über confidence · fester Seed · 2026-06-30 · 2× RTX A6000 (Zwei-GPU-Modus)
Zwei Dinge lassen sich gut ablesen. Erstens die GPU-Spalte. Die fünf Jobs liefen abwechselnd auf Karte 0 und Karte 1. Genau so verteilt die Oberfläche im Zwei-GPU-Modus die Szenarien. Die Solve-Zeiten bleiben dabei durchweg im Bereich unter etwa einer Sekunde, nur der Lauf bei 0,99 fällt mit 1,13 Sekunden etwas heraus.
Zweitens das Ergebnis selbst. Die Sortino-Ratio steigt mit der Konfidenz zunächst klar an, von 5,68 bei 0,7 auf 6,21 bei 0,95, und gibt danach bei 0,99 leicht nach. Der maximale Drawdown ist im mittleren Bereich am niedrigsten, mit 7,50 % bei 0,85, und wächst zu den Rändern hin wieder an, bis auf 8,02 % bei 0,99. Es gibt also keinen einfachen „höher ist besser“-Zusammenhang. Stattdessen liegt der Sweet Spot hier rund um eine Konfidenz von 0,90 bis 0,95. Genau diese Art von Erkenntnis macht der Sweep auf einen Blick sichtbar, und mit festem Seed ist sie sauber auf die Konfidenz zurückzuführen.
Eine oder zwei A6000? Wann die zweite Karte zählt
Damit sind wir bei der Frage, die sich seit dem ersten Teil hartnäckig hält. Wenn ein einzelner Solve auf der A6000 in unter einer Sekunde fertig ist, warum empfiehlt NVIDIA dann eigentlich einen H100?
Der Schlüssel ist die Unterscheidung zwischen einem Lauf und vielen Läufen.
Ein einzelner Solve ist trivial. cuFOLIO verteilt diesen einen Solve auch gar nicht über zwei Karten. Die zweite GPU beschleunigt einen einzelnen Lauf also nicht. Sie zahlt sich beim Durchsatz aus, also dann, wenn viele unabhängige Optimierungen anstehen. Genau das ist der Sweep. Im Modus mit zwei GPUs verteilt die Oberfläche die Jobs parallel auf beide Karten. Bei vielen oder rechenintensiven Szenarien halbiert sich die Gesamtzeit dadurch spürbar. Bei nur einer Handvoll winziger Läufe ist der Effekt klein, weil dann Datenladen und Szenarien-Erzeugung dominieren. Der eine Solve war ohnehin schon in Sekunden vorbei.
Und genau hier wird auch die H100-Empfehlung verständlich. NVIDIA zielt mit cuFOLIO auf die obere Skala. Also auf institutionelle Setups mit tausenden Titeln, hunderttausenden Szenarien und großen Parameter-Studien, oft mehrmals am Tag. Dort werden zwei Dinge bei der Hardware wichtig. Erstens der VRAM also Speicher der GPU. Denn die Szenario-Matrix wächst mit Titeln mal Szenarien und kann die 80 GB eines H100 oder die 141 GB eines H200 sehr wohl belegen. Zweitens der Durchsatz über sehr viele parallele Jobs. Die plakativen Beschleunigungen von 100 bis 160 mal beziehen sich auf diese großen Läfuen mit vielen Titeln und hunderttausenden Szenarien im Vergleich zu einem CPU-Setup.
Für meine Homelab-Größe ist davon nichts bindend. Die 48 GB je A6000 sind reichlich, und mehr Durchsatz hole ich mir über die zweite Karte im Sweep. Die H100-Empfehlung ist damit eine Empfehlung für die obere Skala, keine harte Voraussetzung. Wer das selbst sehen will, treibt im Sweep einfach die Szenarienzahl nach oben und schaut, ab wann die eigene GPU ins Schwitzen kommt.
Reproduzierbarkeit geht nicht verloren
Eine grafische Oberfläche steht oft im Verdacht, Dinge zu verstecken. Hier ist das anders. Jeder Lauf schreibt seine Konfiguration als YAML Datei lokal persistent weg. Der feste Seed macht Ergebnisse exakt wiederholbar. Der Sweep legt pro Szenario eine eigene Config und ein eigenes Ergebnisverzeichnis an und exportiert die Sammlung als CSV. Damit lässt sich jeder Klick in der Oberfläche später wieder als sauberer Skript-Lauf nachstellen. Die Oberfläche ist also Komfort, nicht Magie.
Fazit
Aus dem kargen Skript ist mit der cuFOLIO Web-UI ein Werkzeug geworden, das man jemandem in die Hand geben kann der sich fachlich im Finanzbereich auskennt. Die Tooltips senken die Hürde der Finanzbegriffe etwas aber auskennen muss man sich dennoch. Der Sprachumschalter macht es zweisprachig. Der Vergleich zeigt transparent, was ein einzelner Parameter bewirkt. Und der Sweep verbindet beides mit der Hardware und vielen Szenarien. Er verwandelt die zweite A6000 von einer ungenutzter Reserve in einen Booster wenn man diesen braucht.
Die Erkenntnis aus Teil 1 bleibt bestehen und bekommt nun hoffentlich eine hands-on Option diese auszuprobieren. Für einen einzelnen Solve reicht eine A6000 mit Reserve mehr als aus. Die zweite Karte lohnt sich beim Durchsatz, und genau dort liegt auch der Grund, warum NVIDIA für große, institutionelle Setups zu H100 oder H200 rät. Für das Homelab ist das eine Empfehlung vielelicht zwei GPUs zu haben für die obere Skala falls man selber viele 10.000 Szenarien und Läufe erzeugen möchte aber kein Muss. Wenn Du in diese Richtung gehen möchtest brauchst Du auch eine Möglich des Reportings also eine Datenbank und Auswertungsmöglichkeiten. Dann muss auch alles automatisiert werden sonst ist man selber der Engpass in diesem Szenario. Probier es einfach selbst aus. Den Code samt Oberfläche findest Du im Repository auf GitHub.
Quelle: github.com/NVIDIA-AI-Blueprints/cuFOLIO (Apache-2.0)






{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…