
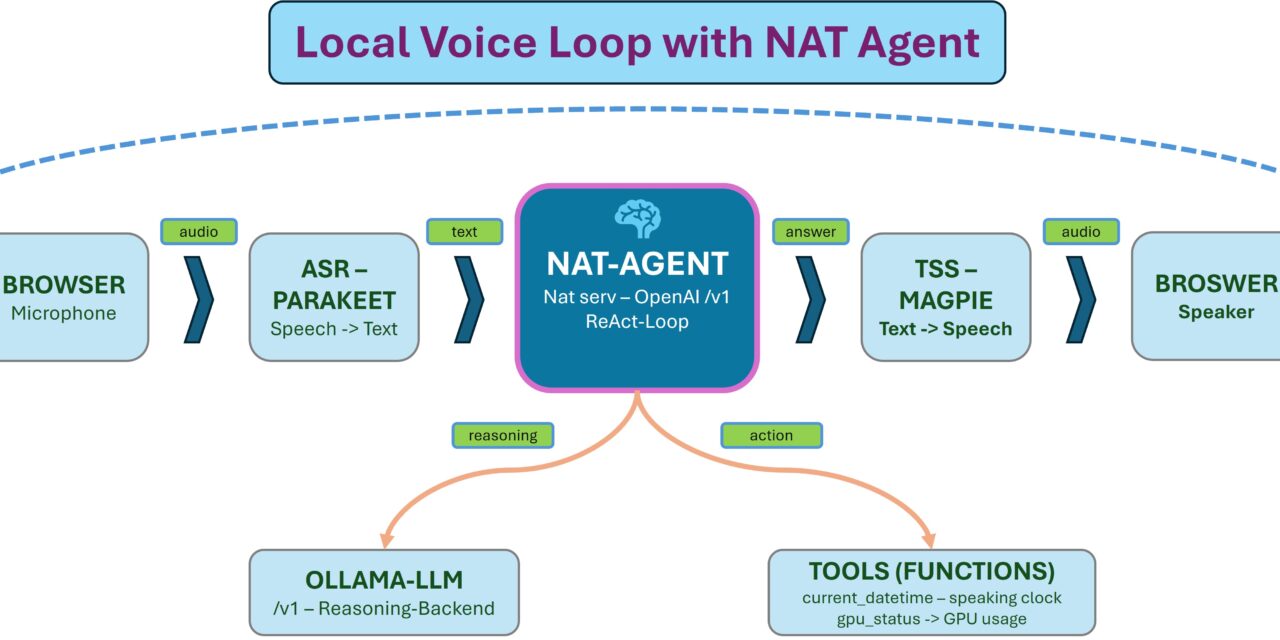
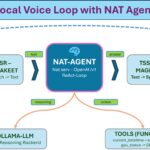
In Teil 6 steht der erste vollständige, lokale Voice-Loop: Ich spreche, Parakeet transkribiert, ein Ollama-LLM antwortet, Magpie spricht. Schön zum Reden auf Basis des gelernten Wissens des LLMs aber der Agent kann noch nichts tun: Im Loop hängt ein nacktes LLM, das frei drauflosredet und keinen Zugriff auf Werkzeuge hat.
Genau da setzt dieser Teil an, und zwar mit einem überraschend kleinen Eingriff: Das komplette Deployment aus Teil 6 läuft unverändert als Basis für mein Vorhaben. Ich muss etzt nur das Gehirn tauschen. Statt des nackten LLM mit seinem begrenzten Weltwissen hängt jetzt der NAT-Agent aus Teil 5 im Loop, und der kann Tools aufrufen. Jetzt ist die Frage was lassen wir den Agenten genau als Aktion ausführen? Die Idee die mir kam ist die klassische Zeitansage über das NAT-Built-in current_datetime Tool das direkt enthalten ist. Aus dem Gesprächspartner wird so ein echter Assistent der die Zeit Ansagen kann. In Teil 6 wer diesen gelesen hat erinnert sich das ich diesen Schritt als „Pfad B“ angekündigt hatte. Mehr steckt jetzt erst einmal nicht dahinter und dennoch wenn wir es verstanden haben öffnet es uns eine Welt von zusätzlichen Möglichkeiten. Es ist und bleibt dieselbe beschriebene Pipeline, nur ein erweitertes Gehirn. Das Wake-Word als Türsteher davor folgt dann in Teil 8 der dann diese Serie abschließt.
NVIDIA NAT Agent Voice Loop Architecture
Die NAT-Grundlagen setze ich hier voraus und diese habe ich in diesen Beiträgen ausführlich aufgebaut, und ich verlinke sie an den passenden Stellen noch einmal:
- NAT als Agenten-Orchestrator lokal aufsetzen (Teil 5)
- NAT vom Inferenz- zum Orchestrator-Layer (Installation, erster ReAct-Agent)
- GenAI-Agent-Orchestrierung lokal (ReAct im Detail, eigenes Tool bauen)
- Multi-Agent Supervisor-Pattern lokal
Was sich ändert und was nicht
Das Wichtigste vorweg: An der Sprach-Pipeline aus Teil 6 ändert sich nichts. Der ganze Loop, Transport, ASR, TTS, Unterbrechbarkeit, Speculative Speech, bleibt exakt so, wie er ist. Auch die NIMs und der Ollama-Server laufen unverändert weiter. Wir tauschen an einer einzigen Stelle ein paar Zeilen Code aus und fügen den NAT-Agent ein das Gehirn ein.
Der Trick liegt in einem Detail, das wir in Teil 6 schon genutzt haben: Pipecat spricht sein LLM über die OpenAI-kompatible Schnittstelle an, und welche Adresse dahinter liegt, steht allein in der .env (Variable NVIDIA_LLM_URL). In Teil 6 zeigte sie direkt auf den Ollama-Server. Jetzt ändern wir diese Anbindung und nach Teil 7 auf den NAT-Agenten und der wiederum spricht intern mit Ollama und ruft bei Bedarf unsere Tools auf die wir ihm zur Verfügung stellen.
Wie kann das überhaupt funktionieren?
Das funktioniert, weil NAT seinen Workflow per nat serve als FastAPI-Server mit OpenAI-kompatiblem /v1/chat/completions-Endpunkt bereitstellt. Für Pipecat sieht ein NAT-Endpunkt damit aus wie „irgendein OpenAI-Server“ genau so wie unsere Ollama Anbindung vorher. Nur die LLM-Stufe wandert also vom Modell zum Agenten angereichert um die zusätzlichen Tools:
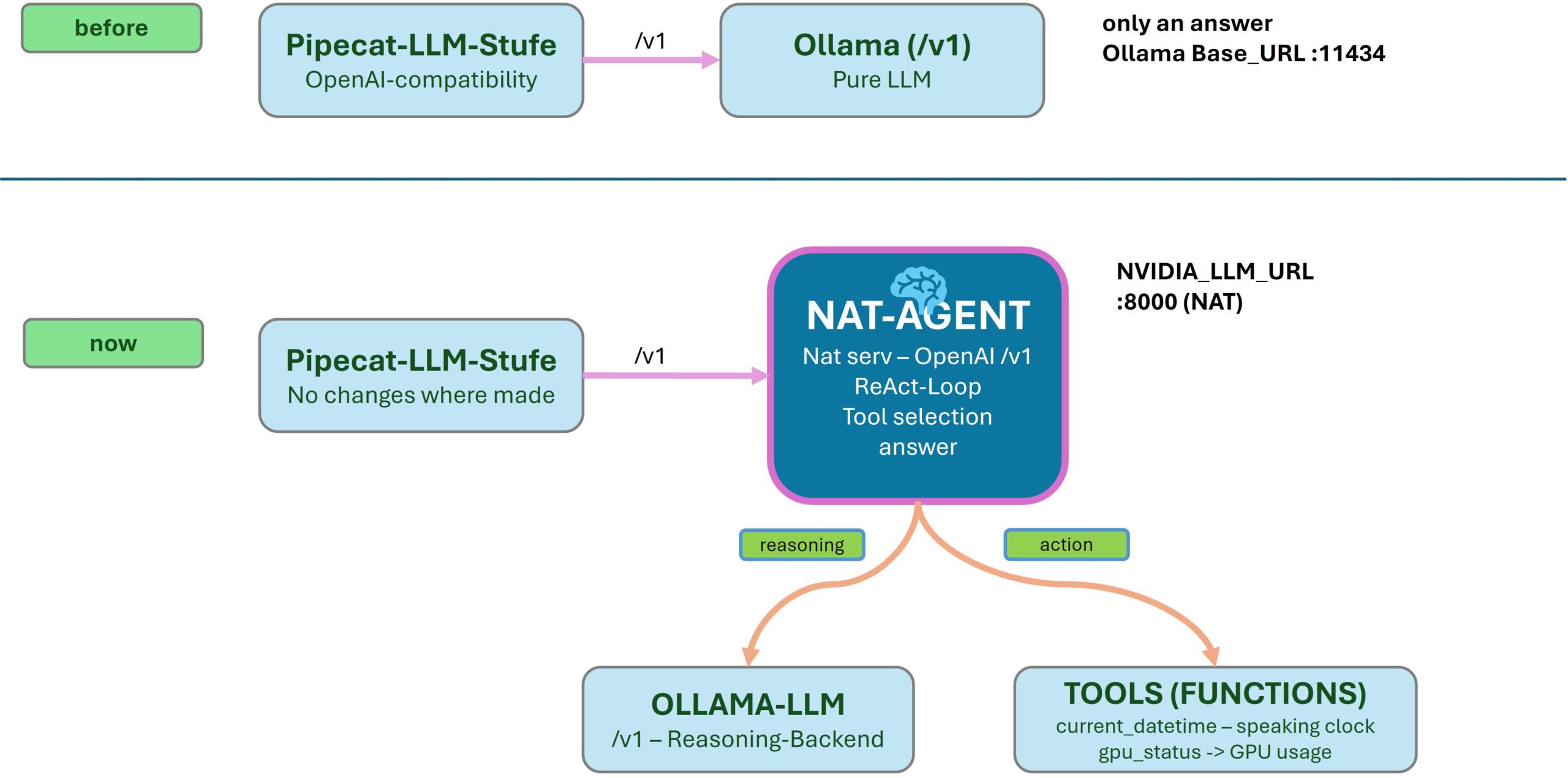
NVIDIA NIM Voice NAT AGENT
Mit anderen Worten: Der NAT-Agent klinkt sich an genau der Stelle ein, an der vorher das von Ollama bereitgestellte LLM saß. Eine einzige Zeile in der .env entscheidet, welcher Endpunkt oder eben Gehirn im Loop hängt. Das gut dabei ist, ein vollständiges Re-Deployment ist dafür nicht nötig.
Voraussetzungen
- Der laufende Voice-Loop aus Teil 6 (Parakeet + Magpie als NIMs, der Pipecat-Bot im Projektordner
voice_agent_websocket). - Ein funktionierendes NAT-Setup wie in diesem Beitrag beschrieben: das Projektverzeichnis
~/nat-playground/mitconfigs/undtools/, die uv-venv.venvundnvidia-nat[langchain]installiert. - Ollama als Inferenz-Backend mit mindestens einem brauchbaren Instruct-Modell. Wichtig für die Sprache: Nimm hier ein schnelles, nicht-reasoning Instruct-Modell (z. B. ein 7–8B-Instruct). Warum, dazu unten der ehrliche Latenz-Abschnitt – die Erkenntnis aus Teil 6 gilt hier doppelt.
- Mindestens ein Tool im NAT-Workflow. Wir starten mit dem Built-in
current_datetime(Zeitansage) und hängen später optional das eigenegpu_status-Tool aus dem Orchestrierungs-Beitrag dran.
Schritt 1: Einen sprach-tauglichen NAT-Workflow anlegen
Der Workflow aus Teil 5 ist ein guter Ausgangspunkt, aber für die Stimme passe ich zwei Dinge an: Die Antworten müssen kurz sein (ein Satz, keine Aufzählungen denn sonst liest Magpie minutenlang vor und das möchten wir nicht), und der System-Prompt muss Deutsch erzwingen (sonst kippt z. B. Qwen beim ReAct-Reasoning ins Englische oder Chinesische, siehe die Qwen-Falle in Teil 5).
Wechsle ins Config-Verzeichnis und lege den Workflow an:
Befehl: cd ~/nat-playground/configs
Befehl: nano voice_agent.yml
So sieht mein sprach-optimierter Single-Agent-Workflow aus. Beachte die beiden Pflicht-Platzhalter {tools} und {tool_names} im System-Prompt – ohne sie quittiert NAT mit ValueError: Invalid system_prompt (auch das kennen wir schon aus Teil 5):
general: front_end: _type: fastapi workflow: method: POST openai_api_v1_path: /v1/chat/completions step_adaptor: mode: custom custom_event_types: [] # unterdrückt die intermediate_data-Eventsllms: ollama_llm: _type: openai api_key: "EMPTY" base_url: "http://192.168.2.57:11434/v1" model_name: "gemma4:26b" temperature: 0.0 max_retries: 3functions: current_datetime: _type: current_datetimeworkflow: _type: react_agent tool_names: [current_datetime] llm_name: ollama_llm parse_agent_response_max_retries: 3 verbose: true system_prompt: | Du bist ein hilfsbereiter deutschsprachiger Sprachassistent. WICHTIG: Antworte AUSSCHLIESSLICH auf Deutsch – auch deine Thoughts. Antworte dem Nutzer in HÖCHSTENS EINEM kurzen Satz, ohne Aufzählungen oder Listen, da deine Antwort laut vorgelesen wird. Du hast Zugriff auf die folgenden Tools: {tools} Verwende exakt dieses Format: Question: die Eingabefrage Thought: überlege auf Deutsch, was zu tun ist Action: eine der folgenden Aktionen - [{tool_names}] Action Input: die Eingabe für die Aktion Observation: das Ergebnis der Aktion ... (Zyklus kann sich wiederholen) Thought: Ich kenne jetzt die finale Antwort Final Answer: die finale Antwort auf Deutsch, in einem kurzen Satz Beginne!Speichern mit Strg + X, dann Y.
Hinweis (Tool-Beschreibungen auf Englisch): Wie im Multi-Agent-Beitrag beschrieben, halte ich die Tool-Descriptions bewusst auf Englisch, auch wenn die Antwort an den Nutzer Deutsch ist. Die Modelle treffen so die Tool-Auswahl dann einfach zuverlässiger. Bei den Built-ins ist das ohnehin schon so.
Den Workflow lege ich auch in meinem GitHub-Repository ab, sodass du ihn nicht abtippen musst:
URL: github.com/custom-build-robots/nemo-agent-toolkit-examples
Bevor wir den Loop dranhängen, testen wir den Workflow einmal klassisch per nat run – so trennen wir „Agent funktioniert“ sauber von „Sprache funktioniert“:
Befehl: cd ~/nat-playground
Befehl: source .venv/bin/activate
Befehl: nat run --config_file configs/voice_agent.yml --input "Wie spät ist es?"
Wenn in der Trace Action: current_datetime auftaucht und am Ende eine kurze deutsche Final Answer mit der Uhrzeit steht wie ihr nachfolgend seht, ist der Agent bereit.
------------------------------
2026-06-18 06:45:40 - INFO - nat.front_ends.console.console_front_end_plugin:162 - --------------------------------------------------
Workflow Result:
Es ist jetzt 04:45 Uhr am 18. Juni 2026.
------------------------------------------------
Jetzt kann es weiter gehen mit der Konfiguration und der Einbindung des Agenten in unseren Voice-Workflow.
Schritt 2: Den NAT-Agenten als Server starten (nat serve)
Statt nat run (ein Aufruf, eine Antwort) starten wir den Workflow jetzt als dauerhaften Server. Dafür gibt es nat serve. Das hostet denselben Workflow hinter einem FastAPI-Server mit einem OpenAI-kompatiblen Chat-Completions-Endpunkt – also genau das Format, das unser Pipecat-Loop erwartet.
Befehl: cd ~/nat-playground
Befehl: source .venv/bin/activate
Befehl: nat serve --config_file configs/voice_agent.yml --port 8001
Standardmäßig lauscht der Server auf 127.0.0.1:8000. Ich starte ihn mit --port 8001, weil bei mir auf 8000 schon ein anderer Dienst lief. Kommt beim Start [Errno 98] address already in use, läuft noch ein alter nat serve – mit pkill -f "nat serve" beenden oder einen freien Port wählen. Ohne --host bindet NAT nur auf localhost; für den Zugriff von einer anderen Maschine zusätzlich --host 0.0.0.0 setzen. Die Dask is not installed-Warnungen sind harmlos.
Kurzer Funktionstest mit demselben OpenAI-Format, das nachher auch Pipecat schickt (in einem zweiten Terminal):
Befehl: curl http://localhost:8001/v1/chat/completions -H "Content-Type: application/json" -d '{"model":"voice_agent","messages":[{"role":"user","content":"Wie spät ist es?"}],"stream":false}'
Wenn du eine JSON-Antwort im OpenAI-Schema (choices[0].message.content) mit einer kurzen deutschen Uhrzeit-Antwort zurückbekommst, steht das Gehirn als Service. Bei mir sah die Antwort wie folgt aus:
ingmar@A6000Ada:~$ curl http://localhost:8001/v1/chat/completions -H "Content-Type: application/json" -d '{"model":"voice_agent","messages":[{"role":"user","content":"Wie spät ist es?"}],"stream":false}'
{"id":"62d20f5d-8e02-4656-ae41-c4f430c90991","object":"chat.completion","model":"unknown-model","created":1781804955,"choices":[{"finish_reason":"stop","index":0,"message":{"content":"Es ist jetzt 17:49 Uhr.","role":"assistant"}}],"usage":{"prompt_tokens":4,"completion_tokens":5,"total_tokens":9},"system_fingerprint":null,"service_tier":null}ingmar@A6000Ada:~$
Gut zu wissen: es kommt nur die Final Answer zur Stimme: Der ReAct-Agent produziert intern Thought/Action/Observation-Zeilen. Für die spätere Sprachausgabe ist entscheidend, dass davon nichts in der Antwort landet. Sonst würde Magpie die komplette Denk-Trace mit vorlesen. Genau das bestätigt der Test oben: Im content steht nur der fertige Satz ("Es ist jetzt 17:49 Uhr."), die Zwischenschritte bleiben serverseitig. Das ist das Standardverhalten des OpenAI-kompatiblen NAT-Endpunkts – wir müssen dafür also nichts extra konfigurieren.
Schritt 3: Den Voice-Loop auf NAT umbiegen (.env)
Jetzt der eigentliche Tausch – und der ist herrlich unspektakulär. Wir öffnen die .env des Pipecat-Projekts aus Teil 6 und ändern nur die beiden LLM-Zeilen:
Befehl: cd ~/voice-agent-examples/examples/voice_agent_websocket
Befehl: nano .env
Vorher (Teil 6 – zeigt direkt auf Ollama):
NVIDIA_LLM_URL=http://<OLLAMA-IP>:11434/v1
NVIDIA_LLM_MODEL=<dein-ollama-modell>Nachher (Teil 7 – zeigt auf den NAT-Server) und hier ist es wichtig das ihr localhost eingebt und nicht die IP-Adresse eures Servers:
# LLM = NAT-Agent (nat serve, OpenAI-kompatibel) statt Ollama direkt
NVIDIA_LLM_URL=http://localhost:8001/v1
NVIDIA_LLM_MODEL=voice_agentEin paar Worte dazu:
- NVIDIA_LLM_URL: zeigt jetzt auf den
nat serve-Endpunkt (Default-Port 8001) statt auf Ollama (11434). Läuft NAT auf derselben Maschine wie der Bot, reichthttp://localhost:8001/v1. - NVIDIA_LLM_MODEL:
nat servebedient genau den einen konfigurierten Workflow, daher ist das Modell-Feld hier eher ein Etikett. NVIDIA_LLM_MODEL:nat servebedient genau den einen konfigurierten Workflow und ignoriert den gesendeten Modellnamen (die Antwort zeigtmodel: "unknown-model"). Der Wert ist also ein reines Etikett. Damit passtvoice_agentbzw. jeder andere String täte es auch. - Alles andere bleibt: ASR-, TTS-, Sprach- und Stimm-Einstellungen rührst du nicht an. Auch
NVIDIA_API_KEY=dummybleibt – der OpenAI-Client besteht weiter auf einem nicht-leeren Wert.
Speichern, und den Bot neu starten (die NIMs aus Teil 6 müssen laufen, NAT aus Schritt 2 ebenfalls):
Befehl: source .venv/bin/activate
Befehl: python bot.py
Schritt 4: End-to-End testen „Wie spät ist es?“
Jetzt läuft alles zusammen: zwei NIMs (Schritt 2 aus Teil 6), der NAT-Server (Schritt 2 hier) und der Pipecat-Bot. Öffne die Test-UI wie gewohnt über den SSH-Tunnel:
Befehl: ssh -L 8100:localhost:8100 ingmar@192.168.2.119
URL: http://localhost:8100/static/index.html
Klick auf Start Audio und frag den Agenten: „Wie spät ist es?“ Was jetzt passiert, ist der ganze Unterschied zu Teil 6: Parakeet transkribiert die Frage, der NAT-Agent erkennt, dass er dafür das Tool current_datetime braucht, ruft es auf, formuliert aus dem Ergebnis einen kurzen deutschen Satz – und Magpie spricht die Uhrzeit aus. Der Agent hat zum ersten Mal eine echte Aktion ausgeführt.
Schritt 5: Ein eigenes Tool sprechbar machen (optional)
Sobald die Zeitansage steht, ist jedes weitere Tool nur noch ein Eintrag in tool_names. Als Beispiel hänge ich das selbstgebaute gpu_status-Tool aus dem Orchestrierungs-Beitrag ein. Mit dieser Anpassung kann ich meinen Server per Stimme nach seiner GPU-Auslastung fragen.
Falls noch nicht geschehen, installiere das Tool wie dort beschrieben (uv pip install -e tools/gpu_status) und prüfe, dass NAT es sieht:
Befehl: nat info components -t function | grep -i gpu
Dann ergänzt du es im Workflow voice_agent.yml:
functions:
current_datetime:
_type: current_datetime
gpu_status:
_type: gpu_status
workflow:
_type: react_agent
tool_names: [current_datetime, gpu_status]
llm_name: ollama_llm
# ... system_prompt wie oben ...nat serve neu starten (damit der geänderte Workflow geladen wird), und schon kannst du fragen: „Wie ausgelastet ist meine GPU gerade?“ – der Agent ruft gpu_status auf und Magpie liest die Werte vor. Jedes weitere Tool braucht zwei Einträge in der voice_agent.yml – einmal die Definition unter functions: und einmal den Verweis in tool_names: – und es muss vorher einmalig installiert/registriert sein.
Fazit
Mit diesem Tausch ist aus dem Sprach-Loop ein handelnder Assistent geworden der über genau zwei Tools verügt. Einmal die Zeitansage und die GPU-Auslastun. Ich spreche, der NAT-Agent versteht, wählt ein Werkzeug, führt es aus und antwortet mir das alles komplett lokal, auf Deutsch, auf eigener Hardware. Und das Eleganteste daran: Die ganze Sprach-Pipeline aus Teil 6 blieb unangetastet, getauscht wurde nur das Gehirn über eine einzige .env-Zeile.
Damit ist die Architektur offen für alles, was NAT kann und jetzt kommt die Phase Tools zu bauen die mir einen richtigen Mehrwert bieten. Nicht nur eine einfache Zeitansage über eigene Python-Tools bis (perspektivisch) zu mehreren Spezialisten. Für den Loop gilt aber: klein und schnell schlägt groß und schlau, sonst leidet das Gespräch und es fühlt sich nicht mehr gut an. Die Zeit die der Agent braucht zu antworten sollte idealerweise unter 1 Sekunde liegen.
Im nächsten Teil kommt der letzte fehlende Baustein: das Wake-Word. Bisher hört der Agent immer zu und antwortet auch ganz häufig. In Teil 8 setze ich ihm einen klassischen Türsteher davor, der erst auf ein Schlüsselwort hin den Loop öffnet und reagieren läßt.
Wenn du das nachbaust: Schreib mir gern in die Kommentare, welche Tools du als Erstes einhängst und welche Voice-to-Voice-Latenz du mit aktivem NAT-Agenten erreichst.






{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…