

Nachdem ich in meinen vorherigen Beiträgen gezeigt habe, wie ihr Ollama, Open WebUI und ComfyUI auf dem Gigabyte AI TOP ATOM installiert, kommt jetzt etwas für alle, die ihre eigenen Sprachmodelle anpassen also individuelle gestalten möchten: LLaMA Factory – ein Open-Source-Framework, das das Fine-Tuning von Large Language Models vereinfacht und Methoden wie LoRA, QLoRA und Full Fine-Tuning unterstützt. Ich habe den für meine Erfahrungsberichte von der Firma MIFCOM einen Spezialisten für Hochleistungs- und Gaming-Rechner aus München ausgeliehen bekommen.
In diesem Beitrag zeige ich euch, wie ich LLaMA Factory auf meinem Gigabyte AI TOP ATOM installiert und konfiguriert habe, um Sprachmodelle wie LLaMA, Mistral oder Qwen für spezielle Aufgaben anzupassen. LLaMA Factory nutzt die volle GPU-Performance der Blackwell-Architektur und ermöglicht es euch, Modelle mit verschiedenen Fine-Tuning-Methoden zu trainieren. Wohlgemerkt soll alles lokal auf eurem eigenen AI TOP ATOM oder eurer eigenen NVIDIA DGX Spark laufen. Da das System AI TOP ATOM von Gigabyte auf der gleichen Plattform wie die NVIDIA DGX Spark basiert, funktionieren die offiziellen NVIDIA Playbooks hier genauso zuverlässig.
Die Grundidee: Eigene Sprachmodelle für spezielle Aufgaben anpassen
Bevor ich in die technischen Details einsteige, ein wichtiger Punkt: LLaMA Factory ist ein Framework, dass das Fine-Tuning von Large Language Models deutlich vereinfacht. Im Gegensatz zu komplexen manuellen Setups bietet LLaMA Factory eine einheitliche Oberfläche für verschiedene Fine-Tuning-Methoden wie Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF) und Quantized LoRA (QLoRA).
Das Besondere daran: LLaMA Factory unterstützt eine große Auswahl an LLM-Architekturen wie LLaMA, Mistral, Qwen und viele mehr. Ihr könnt eure Modelle für spezielle Domänen anpassen – sei es für Code-Generierung, medizinische Anwendungen oder spezielle Unternehmensanforderungen. Die Installation erfolgt über Docker mit dem NVIDIA PyTorch Container, der bereits CUDA-Unterstützung und alle notwendigen Bibliotheken enthält.
Was ihr dafür braucht:
-
Einen Gigabyte AI TOP ATOM, ASUS Ascent, MSI EdgeXpert (oder NVIDIA DGX Spark) der mit dem Netzwerk verbunden ist
-
Einen angeschlossenen Monitor oder Terminal-Zugriff auf den AI TOP ATOM
-
Docker installiert und für GPU-Zugriff konfiguriert
-
Grundkenntnisse in Terminal-Befehlen, Docker und Python
-
Mindestens 50 GB freien Speicherplatz für Modelle, Checkpoints und Trainingsdaten
-
Eine Internetverbindung zum Download von Modellen vom Hugging Face Hub
-
Optional: Ein Hugging Face Account für gated Models (Modelle mit Zugriffsbeschränkungen)
Phase 1: System-Voraussetzungen prüfen
Ich gehe jetzt bei meiner weiteren Anleitung davon aus, dass ihr direkt vor dem AI TOP ATOM oder der NVIDIA DGX Spark sitzt und einen Monitor, Keyboard und Maus angeschlossen habt. Zuerst prüfe ich, ob alle notwendigen System-Voraussetzungen erfüllt sind. Dazu öffne ich ein Terminal auf meinem AI TOP ATOM und führe die folgenden Befehle aus.
Der nachfolgende Befehl zeigt euch, ob das CUDA Toolkit installiert ist:
Befehl: nvcc --version
Ihr solltet CUDA 12.9 oder höher sehen. Als nächstes prüfe ich, ob Docker installiert ist:
Befehl: docker --version
Jetzt prüfe ich mit dem nachfolgenden Befehl, ob Docker GPU-Zugriff hat. Es werden ein paar GB herunter geladen aber die Zeit spart ihr euch dann später wieder denn es wird der gleiche Docker Container für LLaMA Factory benötigt.
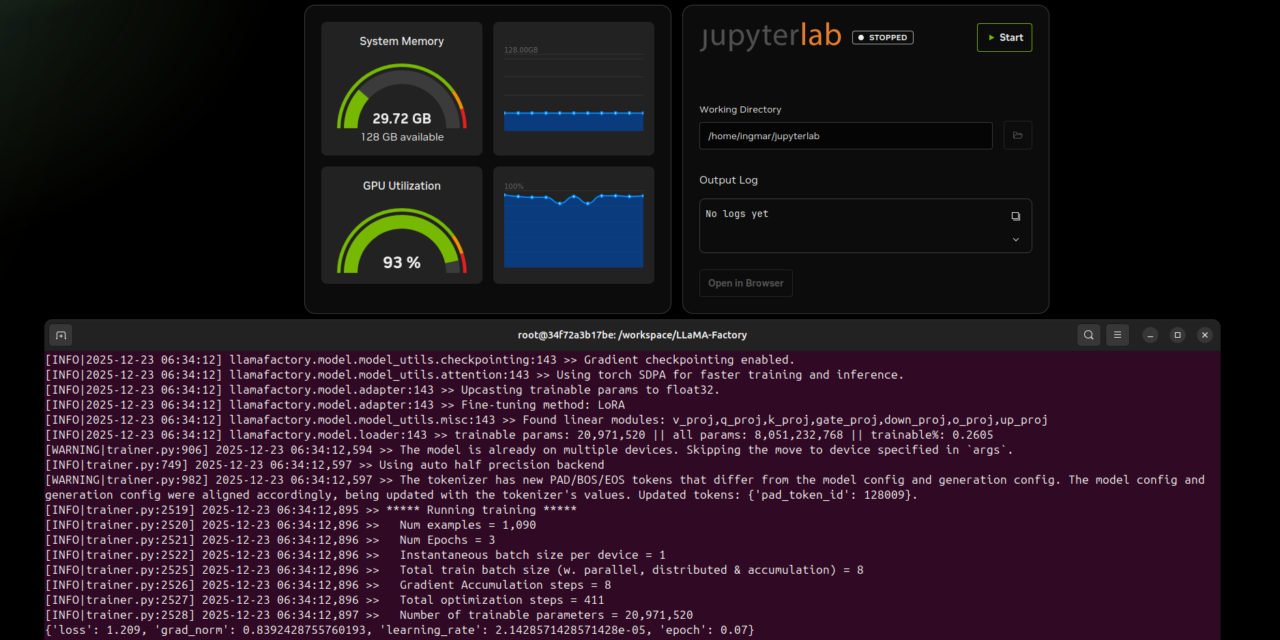
Befehl: docker run --gpus all nvcr.io/nvidia/pytorch:25.11-py3 nvidia-smi
Dieser Befehl startet einen Test-Container und zeigt die GPU-Informationen an. Falls Docker noch nicht für GPU-Zugriff konfiguriert ist, müsst ihr das zuerst einrichten. Prüft auch Python und Git:
GIGABYTE AI TOP ATOM – LLaMA Factory Docker Container test
Befehl: python3 --version
Befehl: git --version
Und schließlich prüfe ich, ob die GPU erkannt wird:
Befehl: nvidia-smi
Ihr solltet jetzt die GPU-Informationen sehen. Falls einer dieser Befehle fehlschlägt, müsst ihr die entsprechenden Komponenten zuerst installieren.
GIGABYTE AI TOP ATOM – NVIDIA-SMI
Phase 2: NVIDIA PyTorch Container mit GPU-Unterstützung starten
LLaMA Factory läuft in einem Docker-Container, der bereits PyTorch mit CUDA-Unterstützung enthält. Das macht die Installation deutlich einfacher, da wir uns nicht um Python-Dependencies kümmern müssen. Zuerst erstelle ich ein Arbeitsverzeichnis:
Befehl: mkdir -p ~/llama-factory-workspace
Befehl: cd ~/llama-factory-workspace
NVIDIA PyTorch Container:
Als nächstest kommt der spannende Teil des Projektes. Jetzt starte ich den NVIDIA PyTorch Container mit GPU-Zugriff und mounte das Arbeitsverzeichnis. Wichtig: Ich verwende einen Namen für den Container (--name llama-factory) und lasse --rm weg, damit der Container auch nach einem Neustart erhalten bleibt:
Befehl: docker run --gpus all --ipc=host --ulimit memlock=-1 -it --ulimit stack=67108864 --name llama-factory -p 7862:7860 -v "$PWD":/workspace nvcr.io/nvidia/pytorch:25.11-py3 bash
Dieser Befehl startet den Container und öffnet eine interaktive Bash-Session. Der Container unterstützt CUDA 13 und ist speziell für die Blackwell-Architektur optimiert. Die Parameter --ipc=host und --ulimit sind wichtig für die GPU-Performance und Speicherverwaltung.
Nach dem Start seht ihr einen neuen Prompt, der zeigt, dass ihr jetzt im Container seid. Alle folgenden Befehle werden innerhalb des Containers ausgeführt.
Wichtiger Hinweis: Falls der Container bereits existiert (z.B. nach einem Neustart), startet ihn mit: docker start -ai llama-factory. Um wieder in einen laufenden Container zu kommen: docker exec -it llama-factory bash.
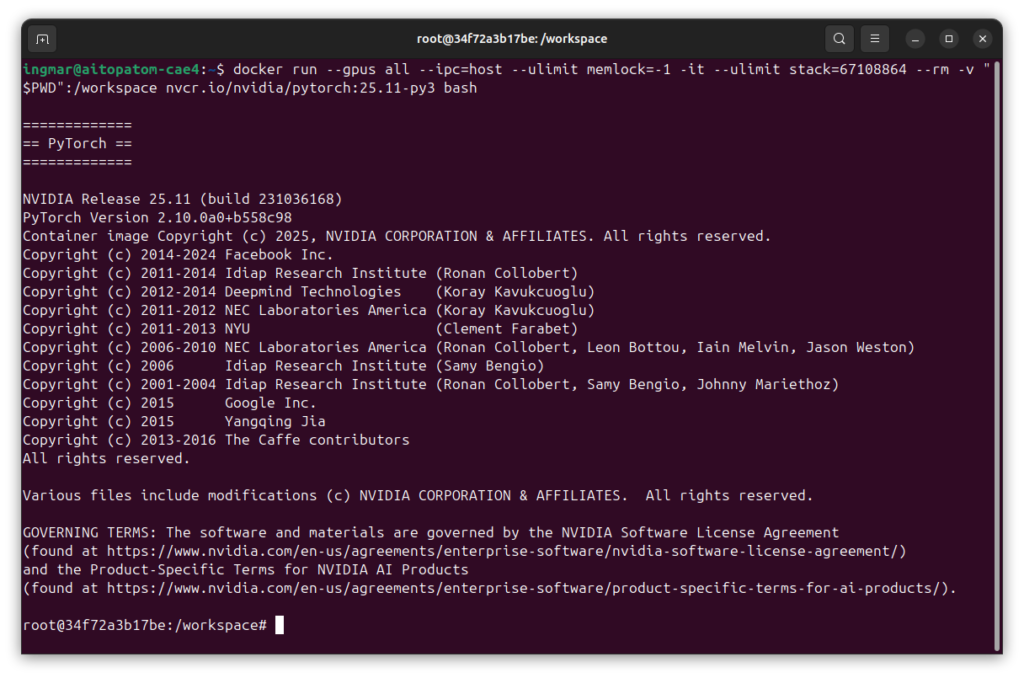
GIGABYTE AI TOP ATOM – LLaMA Factory Docker Container CLI
Phase 3: LLaMA Factory Repository klonen
Jetzt lade ich den LLaMA Factory Quellcode vom offiziellen GitHub Repository herunter. Da wir im Container sind, wird alles im gemounteten Workspace-Verzeichnis gespeichert:
Befehl: git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
Der Parameter --depth 1 lädt nur die neueste Version herunter, was schneller geht. Nach dem Klonen wechsle ich in das LLaMA Factory Verzeichnis:
Befehl: cd LLaMA-Factory
Das Repository enthält alle notwendigen Dateien für LLaMA Factory, einschließlich Beispiel-Konfigurationen und Trainingsskripte.
Phase 4: LLaMA Factory mit Dependencies installieren
Jetzt installiere ich LLaMA Factory im editable Modus mit Metrics-Unterstützung für die Trainingsauswertung:
Befehl: pip install -e ".[metrics]"
Diese Installation kann einige Minuten dauern, da viele Pakete heruntergeladen werden müssen. Der Parameter -e installiert LLaMA Factory im editable Modus, sodass Änderungen am Code sofort wirksam werden. Die Option [metrics] installiert zusätzliche Pakete für die Trainingsmetriken.
Hier habe ich nichts interessantes im Terminal-Fenster gesehen außer „Successfully installed….“ und habe daher kein Bild hier eingefügt.
Phase 5: PyTorch CUDA-Unterstützung prüfen
PyTorch ist bereits im Container vorinstalliert, aber ich prüfe trotzdem, ob CUDA-Unterstützung verfügbar ist:
Befehl: python -c "import torch; print(f'PyTorch: {torch.__version__}, CUDA: {torch.cuda.is_available()}')"
Ihr solltet eine Ausgabe sehen, die etwa so aussieht:
PyTorch: 2.10.0a0+b558c986e8.nv25.11, CUDA: TruePhase 6: Trainings-Konfiguration vorbereiten
LLaMA Factory verwendet YAML-Konfigurationsdateien für das Training. Ich schaue mir die Beispiel-Konfiguration für LoRA Fine-Tuning mit Llama-3 an:
Befehl: cat examples/train_lora/llama3_lora_sft.yaml
Diese Konfiguration enthält alle notwendigen Parameter für das Training: Modellname, Dataset, Batch-Größe, Learning Rate und vieles mehr. Ihr könnt diese Datei kopieren und für eure eigenen Anforderungen anpassen.
Wichtiger Hinweis: Für euer erstes Training empfehle ich, die Beispiel-Konfiguration zunächst unverändert zu verwenden, um sicherzustellen, dass alles funktioniert.







{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…