

In meiner vierteiligen TensorRT-LLM-Serie habe ich gezeigt, wie ich Inferenz-Performance auf der RTX A6000 Ada optimiere und 251 Tokens/sec mit Qwen-2.5-7B in FP8, deploybare .engine-Dateien, alles sauber reproduzierbar. Aber dabei hatte ich nur einen Teil des Stacks gebaut: den Inferenz-Layer.
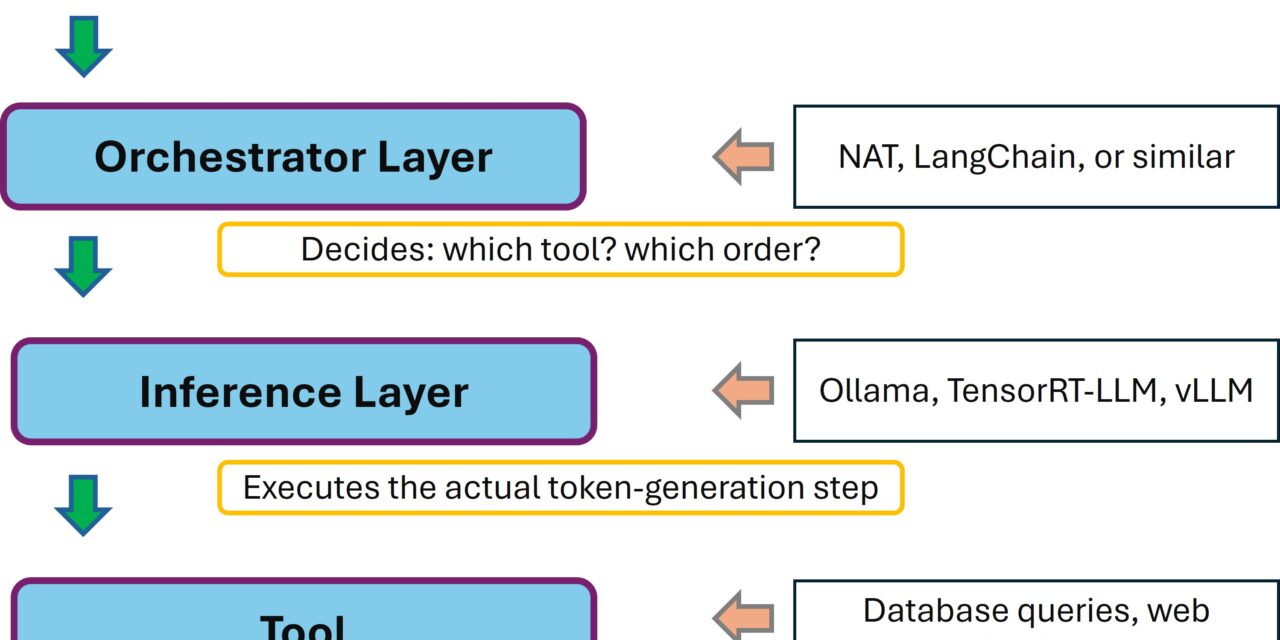
Inspiriert von dem allgegenwärtigen GenAI Agenten Veröffentlichungen ist mir klar geworden: ein produktiver AI-Stack besteht aus mehreren Schichten. Inferenz ist nur eine davon. Darüber sitzt der Orchestrator also die Schicht, die entscheidet, welches Tool wann aufgerufen wird, die Multi-Step-Reasoning macht, die Agent-Verhalten erzeugt.
NVIDIA hat dafür das NeMo Agent Toolkit (NAT) als Open-Source-Bibliothek bereitgestellt. In diesem Beitrag zeige ich dir, wie ich NAT auf meinem Ubuntu-24.04-Server installiert habe sauber in einer Python-venv isoliert, mit meinem bestehenden Ollama-Setup als Backend und wie ich den ersten ReAct-Agent zum Laufen gebracht habe. Inklusive zweier nicht-trivialer Stolperfallen, die ich dir gerne erspare.
Hier geht es zu dem NeMo Agent Toolkit: https://github.com/NVIDIA/NeMo-Agent-Toolkit
Worum geht es eigentlich?
Ein Agent im modernen LLM-Kontext ist mehr als ein Chatbot. Ein Chatbot bekommt eine Frage und antwortet. Ein Agent bekommt eine Aufgabe und entscheidet selbständig, welche Tools er aufruft, in welcher Reihenfolge, und wann er genug Informationen für eine finale Antwort hat. Das klassische Muster heißt ReAct (Reason + Act): Das Modell denkt nach, wählt eine Aktion (Tool-Aufruf), beobachtet das Ergebnis, denkt wieder nach bis es eine fertige Antwort hat.
Auf der Architektur-Ebene sieht das so aus:
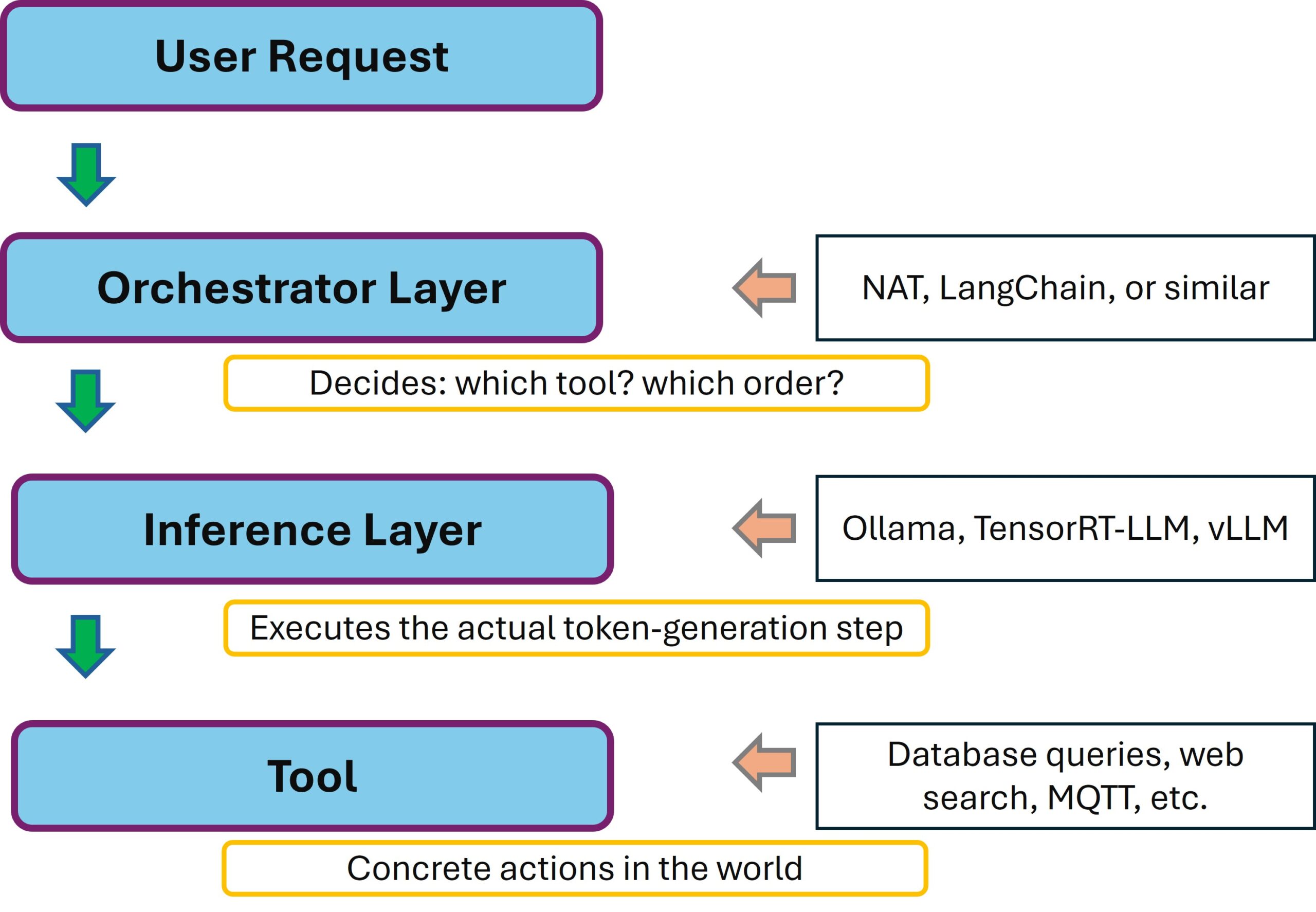
NVIDIA NeMo Agent Toolkit – Architecture
NAT ist explizit so gebaut, dass es framework-agnostisch ist: Du kannst LangChain, LlamaIndex, CrewAI oder auch eigene Frameworks dahinter hängen. Und der Inferenz-Layer ist über die OpenAI-kompatible API entkoppelt. Das ist eine sehr flexible Architektur und was unten dran hängt, ist NAT komplett egal. Ollama, vLLM, TensorRT-LLM, oder ein NVIDIA NIM solange es OpenAI-Format spricht, funktioniert es.
Voraussetzungen
Diese Anleitung setzt voraus, dass dein Server bereits grundlegend für KI-Inferenz vorbereitet ist. Falls nicht, arbeite zuerst meinen Foundation-Beitrag durch: Ubuntu 24.04 Server für KI-Inferenz vorbereiten.
Konkret brauchst du:
- Ubuntu 24.04 LTS
- Eine NVIDIA-GPU (ich nutze die RTX A6000 Ada für 7B-Modelle in 4-Bit-Quantisierung reicht aber auch jede Karte ab 8 GB VRAM)
- Ollama läuft bereits mit
qwen2.5:7b-instructim Modell-Cache (oder einem anderen Modell deiner Wahl) - Python 3.11, 3.12 oder 3.13 auf dem Host System-Python von Ubuntu 24.04 ist Python 3.12, passt
- Internet-Verbindung für die initialen Paket-Downloads (rund 1,5 GB)
Architektur-Überblick: Was läuft wo?
Bevor wir loslegen, ein kurzer Blick auf die saubere Trennung der Komponenten. Auf meinem Server koexistieren mehrere Layer mit unterschiedlichen Isolationsmechanismen:
| Komponente | Wo läuft sie? | Warum dort? |
|---|---|---|
| NVIDIA-Treiber, CUDA, Docker | System-weit | Brauchen alle Anwendungen, kein Isolations-Bedarf |
| Ollama | System-Service (systemctl) | Daemon-Charakter, hört auf Port 11434 |
| TensorRT-LLM | Docker-Container (NGC-Image) | Komplexer Dependency-Stack → Container isoliert ihn |
| NeMo Agent Toolkit (NAT) | Python-venv auf dem Host | Mittlerer Komplexitäts-Grad — venv reicht |
| Custom Tools (Python) | Im selben venv wie NAT | Direkter Zugriff auf NAT-API |
Der entscheidende Punkt: NAT braucht keinen Container, weil es eine reine Python-Bibliothek ist. Aber es braucht zwingend eine eigene Python-Umgebung, weil seine rund 80 bis 120 Dependencies sonst mit anderen Python-Projekten oder System-Tools kollidieren können. Die NAT-Dokumentation warnt übrigens explizit vor conda. Daher nehme ich Vanilla-venv.
Schritt 1: uv installieren
uv ist ein moderner Python-Paket-Manager, der etwa 10-100x schneller als pip ist. Die NVIDIA-Dokumentation empfiehlt ihn explizit als bevorzugte Variante für die NAT-Installation. Jetzt müssen eine Reihe von Befehlen ausgeführt werden. Das geht jetzt alles Schritt für Schritt.
Befehl: curl -LsSf https://astral.sh/uv/install.sh | sh
Befehl: source ~/.bashrc
Befehl: uv --version
Bei mir landet uv unter ~/.local/bin/uv, und die Versionszeile sieht etwa so aus: uv 0.x.x. Falls die Verifikation fehlschlägt, ist der Installer typischerweise an der falschen Stelle gelandet — ein source ~/.profile oder ein frisches Terminal hilft.
Schritt 2: Verzeichnis-Struktur anlegen
Ich lege ein eigenes Projektverzeichnis für NAT an, separat von meinen anderen KI-Projekten. Das hat den Vorteil, dass ich später beliebig viele Agent-Projekte parallel haben kann, ohne dass sich die Dependencies in die Quere kommen.
Befehl: mkdir -p ~/nat-playground/configs
Befehl: mkdir -p ~/nat-playground/tools
Befehl: cd ~/nat-playground
Die spätere Verzeichnisstruktur sieht dann so aus:
~/nat-playground/ ├── .venv/ # Eigene Python-Umgebung (Schritt 3) ├── configs/ # YAML-Workflow-Konfigurationen └── tools/ # Eigene Custom-Tools (Python-Module)
Schritt 3: Python-venv für NAT anlegen
Jetzt erstellen wir die virtuelle Python-Umgebung. Mit uv geht das in einem Schritt und ich bin immer noch begeistert wie einfach das geht:
Befehl: uv venv --python 3.12 --seed .venv
Befehl: source .venv/bin/activate
Der --seed-Flag sorgt dafür, dass pip in der venv mit installiert wird, was Plugin-Installationen vereinfacht. Erkennbar an dem (.venv) im Shell-Prompt.
Was passiert hier? Eine venv ist im Grunde nur ein Verzeichnis mit einer eigenen python-Binary (oft Symlink zum System-Python), einem eigenen site-packages-Ordner und einem Aktivierungs-Skript. Beim Aktivieren wird der Shell-PATH so manipuliert, dass beim Aufruf von python oder pip zuerst die venv-Binaries gefunden werden. Diese installieren Pakete in den venv-eigenen site-packages-Ordner sind komplett isoliert vom System was wir unbedingt erreichen wollen.
Vorteil: Wenn ich mir die Installation zerschieße, lösche ich einfach .venv/ und fange von vorne an. Das System-Python bleibt unberührt.
Schritt 4: NeMo Agent Toolkit installieren
Mit aktiver venv installiere ich NAT mit dem LangChain-Plugin. LangChain ist die Standard-Framework-Brücke und wird für den ReAct-Agent gebraucht:
Befehl: uv pip install "nvidia-nat[langchain]"
Der Befehl zieht etwa 80-120 Pakete LangChain, Pydantic, httpx, openai-Client und einiges mehr. Mit uv hat die Installation ca. 5-10 Minuten gedauert.
Jetzt prüfen wir einmal ob NAT auch installiert wurde.
Befehl: nat --version
Befehl: nat info components -t llm_provider
Der zweite Befehl listet die verfügbaren LLM-Provider auf. Du solltest mindestens openai und nim in der Liste sehen. Der openai-Provider ist der, den wir für Ollama verwenden werden. Er funktioniert mit jedem OpenAI-kompatiblen Endpoint.
Um die Listenansicht wieder zu verlassen muss einfach q getippt werden.
Schritt 5: Ollama OpenAI-API verifizieren
Ollama stellt seit Version 0.1.24 einen OpenAI-kompatiblen Endpoint unter /v1 bereit. Jetzt machen wir einen schnellen Funktionstest, bevor wir NAT damit verbinden. Wichtig ist das Dein Ollama Inferenz-Server läuft und erreichbar ist:
Befehl: curl http://localhost:11434/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "qwen2.5:7b-instruct",
"messages": [{"role":"user","content":"Antworte mit OK."}],
"max_tokens": 10
}'
Wenn du eine JSON-Antwort mit "OK" im content-Feld zurückbekommst, ist alles bereit.
Hinweis: Falls NAT auf einem anderen Rechner laufen soll als Ollama, muss Ollama auf allen Interfaces lauschen.
Schritt 6: Erste Agenten-Workflow-Konfiguration
NAT-Workflows werden in YAML-Dateien definiert. Wir starten mit einem minimalen Workflow, der nur ein einziges Tool nutzt. Dieser soll die aktuelle Uhrzeit ausgeben. Der Workflow wird in einer *.yml Datei hinterlegt. Ich habe dazu mit nano die folgende Datei im Order configs angelegt.
Befehl: ~/nat-playground/configs
Befehl: nano ollama_agent.yml
In diese Datei kopierst Du den folgenden Inhalt der den Workflow beschreibt.
llms:
ollama_llm:
_type: openai
api_key: "EMPTY"
base_url: "http://localhost:11434/v1"
model_name: "qwen2.5:7b-instruct"
temperature: 0.0
max_retries: 3
functions:
current_datetime:
_type: current_datetime
workflow:
_type: react_agent
tool_names: [current_datetime]
llm_name: ollama_llm
verbose: true
parse_agent_response_max_retries: 3Mit der Tastenkombination STRG + x gefolgt von einem y speicherst Du die Änderung ab.
Drei Hauptblöcke:
llms:Definiert die verfügbaren LLM-Backends._type: openaimacht Ollama als generischen OpenAI-Endpoint nutzbar. Dasapi_key: "EMPTY"ist Pflicht, auch wenn Ollama es nicht prüft das Feld muss aber gesetzt sein, sonst gibt’s einen Validierungsfehler.functions:Definiert die Tools, die der Agent aufrufen darf.current_datetimeist ein Built-in von NAT.workflow:Definiert das Agent-Pattern.react_agentist der klassische Reason+Act-Pattern.
Schritt 7: Den Agenten ausführen
Wenn Du jetzt den Agenten-Workflow ausführen möchtest ist es wichtig das Du in der aktiven virtuellen Umgebung .venv bist. Führe jetzt die folgenden Befehle aus.
Befehl:cd ~/nat-playground
Befehl:nat run --config_file configs/ollama_agent.yml --input "Welche Uhrzeit ist es jetzt und was kann ich daraus für meinen Arbeitstag ableiten?"
Wenn alles funktioniert, siehst du eine ReAct-Trace im Terminal der wie folgt aussehen kann. Bei mir sind aber noch viele chinesische Zeichen dazwischen gewesen.
Thought: Ich muss die aktuelle Uhrzeit herausfinden.
Action: current_datetime
Action Input: {}
Observation: 2026-05-16 16:56:52 +0000
Thought: Es ist Samstagabend, 18:56 Münchner Zeit. Da kann ich ableiten...
Final Answer: Es ist gerade 18:56 Uhr am 16. Mai 2026...Damit hast du den Inferenz-Layer (Ollama) und den Orchestrator-Layer (NAT) sauber gekoppelt. Genau die Architektur-Trennung die wir erreichen wollen. In diesem Fall mit Ollama statt TensorRT-LLM.
Die Qwen-Falle: Wenn der Agent plötzlich Chinesisch spricht
Hier wird’s interessant. Bei meinem ersten Lauf erlebte ich folgende Trace:
Thought: 为了回答这个问题,我需要获取当前的时间和日期信息...
Action: current_datetime
Action Input: {"unused": "2023-11-29T15:48:00Z"}
...
Final Answer: 当前时间为2026年5月16日下午4点56分52秒...Der Agent hat das Tool korrekt aufgerufen, die richtige Uhrzeit bekommen aber die komplette Antwort kam auf Chinesisch. Das ist ein bekannter Quirk der Qwen-2.5-Familie: das Modell stammt von Alibaba und fällt bei strukturiertem Reasoning regelmäßig in seine Trainings-Hauptsprache zurück. Bei Modellen unter 14B Parametern besonders ausgeprägt.
Die Lösung: ein expliziter System-Prompt, der die Sprache erzwingt. Aber Achtung NAT’s react_agent ist Template-basiert. Wenn du einen eigenen System-Prompt setzt, musst du die Platzhalter {tools} und {tool_names} selbst einbauen, sonst weiß der Agent nicht, welche Tools verfügbar sind. Das hat mich beim ersten Versuch gleich ein paar Minuten gekostet da ich das nicht gemacht hatte.
Die richtige Lösung mit System-Prompt der als Sprache Deutsch fordert sieht so aus. Lege einfach einen neuen Workflow an.
Befehl: ~/nat-playground/configs
Befehl: nano ollama_agent_system_prompt.yml
llms:
ollama_llm:
_type: openai
api_key: "EMPTY"
base_url: "http://localhost:11434/v1"
model_name: "qwen2.5:7b-instruct"
temperature: 0.0
max_retries: 3
workflow:
_type: react_agent
tool_names: [current_datetime]
llm_name: ollama_llm
system_prompt: |
Du bist ein hilfsbereiter deutschsprachiger Assistent.
WICHTIG: Antworte AUSSCHLIESSLICH auf Deutsch. Auch deine Gedanken (Thoughts) müssen auf Deutsch sein.
Verwende NIEMALS Chinesisch oder eine andere Sprache.
Du hast Zugriff auf die folgenden Tools:
{tools}
Verwende folgendes Format für deine Antwort:
Question: die Eingabefrage, die du beantworten musst
Thought: überlege auf Deutsch, was als nächstes zu tun ist
Action: die auszuführende Aktion - muss eines der folgenden sein: [{tool_names}]
Action Input: die Eingabe für die Aktion
Observation: das Ergebnis der Aktion
... (dieser Zyklus kann sich wiederholen)
Thought: Ich kenne jetzt die finale Antwort
Final Answer: die finale Antwort - auf Deutsch
Beginne!
verbose: true
parse_agent_response_max_retries: 3Die beiden geschweiften Klammern {tools} und {tool_names} sind Template-Variablen, die NAT zur Laufzeit ersetzt:
{tools}wird zur detaillierten Beschreibung aller Tools (Name, Description, Parameter){tool_names}wird zur Komma-separierten Liste der Tool-Namen
Bei NAT’s Default-Prompt (also wenn du system_prompt weglässt) macht NAT das automatisch – aber dann ist der Prompt eben auf Englisch, mit allen Konsequenzen für die Sprach-Ausgabe.
Schritt 8: Tool-Erweiterung mit Wikipedia-Suche
Der current_datetime-Test den wir als erstes ausprobiert haben ist trivial. Spannender wird’s mit echten Tools. NAT hat wiki_search als Built-in. Erweitere jetzt die Config um die WiKi Suche wie nachfolgend kurz gezeigt.:
functions:
current_datetime:
_type: current_datetime
wikipedia_search:
_type: wiki_search
max_results: 3
workflow:
_type: react_agent
tool_names: [current_datetime, wikipedia_search]
llm_name: ollama_llm
system_prompt: |
...wie oben...
verbose: true
parse_agent_response_max_retries: 3Jetzt kannst Du wie bereits gezeigt die Workflows ausführen. Achte bitte darauf das Du die richtigen Namen nimmst so wie Du die *.yml Dateien genannt hast.
Befehl: nat run --config_file configs/ollama_agent.yml --input "Wer war Nikola Tesla und in welchem Jahr starb er?"
Der Agent sollte jetzt selbständig die wikipedia_search auswählen, das Ergebnis interpretieren und eine zusammenfassende Antwort liefern diesmal idealerweise auf Deutsch.
Stolperfallen, die du wahrscheinlich treffen wirst
1. Qwen-7B macht ReAct nicht immer sauber
Auch mit System-Prompt: kleinere Modelle (7B-Klasse) halten sich nicht immer perfekt an das ReAct-Format. Du wirst gelegentlich Output sehen, in dem Action und finale Antwort vermischt sind. Das ist der Grund für parse_agent_response_max_retries: 3 in der Config NAT versucht das Re-Parsing automatisch durchzuführen.
Wenn der Aufruf dauerhaft scheitert: Wechsle auf ein größeres Modell das Du noch betreiben kannst. Größere Modelle sind beim ReAct-Reasoning deutlich zuverlässiger. So hat bei mir das qwen3.6:27b ganz brauchbare Ergebnisse geliefert.
2. Custom System-Prompt braucht Template-Variablen
Wenn du system_prompt setzt, müssen {tools} und {tool_names} drin stehen. Sonst kommt der unschöne ValueError: Invalid system_prompt Fehler.
3. Verbindungs-Fehler zu Ollama
Falls du Connection refused siehst, prüfe der Reihe nach:
- Läuft Ollama?
systemctl status ollama - Ist
base_urlrichtig? Achtung: NAT braucht/v1am Ende - Falls Ollama remote läuft: Akzeptiert Ollama Verbindungen von außerhalb? (
OLLAMA_HOST=0.0.0.0setzen)
4. Performance-Erwartungen
Ein ReAct-Loop mit zwei bis drei Tool-Calls braucht typischerweise 5 bis 15 Sekunden. Das fühlt sich langsamer an als einfache Chat-Inferenz. Grund: Der Agent generiert deutlich mehr Tokens als eine einfache Antwort (Thoughts, Actions, Observations, finale Antwort).
5. Was du NICHT machen solltest
Wenn Du so wie ich das Nivida NeMo Agent Tool kit installieren möchtest dann vermeide folgendes:
sudo pip install nvidia-natglobale Installation als root kann System-Python-basierte Tools zerschießenpip install nvidia-natohne aktive venv landet die Installation je nach Konfig im User-Verzeichnis- Conda-Umgebung statt venv die NAT-Doku warnt explizit davor Conda zu verwenden
Was kommt als Nächstes?
Mit diesem Setup hast du den Orchestrator-Layer auf deiner Workstation. Die spannenden Erweiterungen liegen auf der Hand:
- MCP-Tools anbinden: NAT unterstützt das Model Context Protocol nativ. Damit hängst du Tools wie Filesystem-Zugriff, GitHub-API oder eigene REST-Endpoints an
- Custom Python Tool: z. B. eine MQTT-Bridge zu einem ESP32-Roboter. Das wäre die spannende Brücke zwischen LLM-Agent und Physical AI die mich persönlich sehr interessiert
- A2A-Protokoll: (Agent-to-Agent) mehrere Agenten orchestrieren, Aufgaben verteilen
- NAT als FastAPI-Server: mit
nat servedas wäre die Web-UI-Anbindung - Vision-Language-Models: wenn du den Agent auch mit Bildern füttern willst, ist das der nächste Modell-Schritt
Mein nächster Plan: ein Custom-Tool, das per MQTT mit einem ESP32-Robot-Car kommuniziert. Damit wird aus dem ReAct-Agent ein echter Hybrid zwischen Sprachmodell und embedded Hardware und Physical AI bekommt eine konkrete, greifbare Bedeutung in meiner KI-Werkstatt.
Fazit
Der Übergang vom reinen Inferenz-Layer wie Ollama zum Orchestrator-Layer (NAT) ist konzeptionell ein größerer Sprung, als es zunächst aussieht. Du hast es plötzlich mit Multi-Step-Reasoning, Tool-Selection, Prompt-Templating und Format-Robustheit zu tun. Das sind alles Themen, die in der reinen Inferenz keine Rolle spielten. Gleichzeitig ist das Setup mit NAT erstaunlich übersichtlich: eine venv, ein uv pip install, eine YAML-Datei und du hast den Orchestrator stehen. Die Komplexität liegt nicht im Setup, sondern in den Details: der Sprach-Drift bei kleineren Modellen, die Template-Variablen, die Prompt-Engineering-Feinheiten.
Für mich ist das die zweite Säule des Stacks und zusammen mit der ersten Säule dem Inferenz-Server habe ich jetzt eine solide Basis, um die nächsten Edge-AI-Themen anzugehen: VLMs, Physical AI über ESP32-Brücken, und irgendwann die Portierung auf einen Jetson Thor, wenn ich soweit komme.
Viel Erfolg beim eigenen Setup!








{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…