


Im zweiten Teil habe ich TensorRT-LLM im Docker-Container aufgesetzt und mit TinyLlama validiert, dass die Pipeline grundsätzlich läuft. Dabei kam ein wichtiges Detail zum Vorschein: Die Standard-API from tensorrt_llm import LLM nutzt den PyTorch-Backend und produziert keine deploybare Engine-Datei. Für den klassischen Build-Once-Deploy-Many-Pattern und um eine Architektur zu erproben, die später auch auf Edge-LLM funktioniert brauche ich aber das TensorRT-Backend und seinen zweistufigen Build-Workflow.
In diesem Teil baue ich mit Dir zusammen Schritt für Schritt zwei persistente Engines für Qwen2.5-7B-Instruct: einmal in FP16 als Baseline, einmal in FP8 zur Aktivierung der Hardware-Transformer-Engine auf der Ada-Architektur. Beide als deploybare .engine-Dateien, beide reproduzierbar mit Build-Skripten.
Die zweistufige Pipeline
TRT-LLM trennt den Build-Vorgang in zwei klar definierte Stufen, jeweils mit einem eigenen CLI-Tool:
HuggingFace Checkpoint
↓
[Stufe 1] convert_checkpoint.py (oder quantize.py bei FP8)
↓
TRT-LLM Checkpoint (rank0.safetensors + config.json)
↓
[Stufe 2] trtllm-build
↓
TensorRT Engine (rank0.engine + config.json)
Stufe 1 konvertiert HuggingFace-Gewichte in das interne TRT-LLM-Checkpoint-Format. Bei FP8 macht dieser Schritt zusätzlich die Post-Training Quantization auf Basis von Kalibrierungs-Samples. Output ist immer noch ein portables Format, das nicht hardware-spezifisch ist.
Stufe 2 kompiliert den TRT-LLM-Checkpoint in eine hardware-spezifische TensorRT-Engine. Hier passiert das Kernel-Auto-Tuning, die Graph-Optimierung, die Wahl der Präzision pro Operation. Output ist eine .engine-Datei, die nur noch auf der Ziel-GPU-Architektur läuft (in meinem Fall SM89 für Ada).
Diese Trennung ist exakt dieselbe Logik wie bei Edge-LLM, wo Stufe 1 als ONNX-Export auf einem x86-Host läuft und Stufe 2 (Engine-Build) entweder auf dem x86-Host für ein bestimmtes Target oder direkt auf dem Edge-Gerät passiert.
build_qwen_fp16.sh: Die Baseline
Mein erstes Build-Skript automatisiert beide Stufen für Qwen2.5-7B-Instruct in FP16. Bis ich dieses Skript am Laufen hatte ufff hat es etwas gedauert. Das Problem war, dass ich das Python Skript convert_checkpoint.py nicht gefunden hatte. Erst nach intensivem Lesen von Fehlermeldungen und Suchen im Container habe ich es dann gefunden.
Jetzt hier kurz zu der Kern-Logik was passiert:
Stufe 1: HF → TRT-LLM Checkpoint
Das von HF heruntergeladene Modell wird konvertiert.
python3 /app/tensorrt_llm/examples/models/core/qwen/convert_checkpoint.py \
--model_dir "$QWEN_HF" \
--output_dir /workspace/checkpoints/qwen2.5-7b-fp16 \
--dtype float16
Stufe 2: TRT-LLM Checkpoint → TensorRT Engine
Hier wird die TensorRT Engine gebaut.
trtllm-build \
--checkpoint_dir /workspace/checkpoints/qwen2.5-7b-fp16 \
--output_dir /workspace/engines/qwen2.5-7b-fp16 \
--gemm_plugin float16 \
--max_batch_size 4 \
--max_seq_len 4096Drumherum baue ich folgende Features ins Skript:
set -euo pipefailfür striktes Fehler-Handling- Sanity-Check: läuft im Container,
trtllm-buildim PATH, HF-Modell im Cache - Idempotenz: wenn
rank0.engineschon existiert, frage nach (User kann den Build überspringen – das hat mir wirklich Zeit gespart) - Timing pro Stufe: mit
date +%sStart- und Endzeit, schöne Ausgabe - Statistik-Log: Ergebnisse werden zusätzlich nach
/workspace/engines/qwen2.5-7b-fp16-build.loggeschrieben, sodass mehrere Builds nebeneinander vergleichbar sind - Farbiger Log-Output: matched den Stil meines
setup_trtllm.sh
Vorbereitung: Qwen-7B in den HF-Cache holen
Bevor build_qwen_fp16.sh loslegen kann, muss das Qwen-7B Modell selbst überhaupt erst auf der Platte liegen. Das Skript prüft als Sanity-Check, ob Qwen2.5-7B-Instruct im HF-Cache unter /workspace/cache/hub/ zu finden ist und bricht ab, wenn es dort das Modell nicht findet.
Eine bewusste Entscheidung die ich getroffen habe ist die klare Aufteilung zwischen den verschiedenen Skripten. Das Build-Skript soll nicht selbst Modelle aus dem Netz herutner laden. Das wäre intransparent einen 14 GB Download zu starten ohne explizite Bestätigung und macht das Debugging schwer. Daher die klar Trennung um auch sagen zu können war es ein Download-Fehler oder ein Build-Fehler? Denn bei mir hakelt die Internetandindung hin und wieder. Sauber getrennte Verantwortlichkeiten.
Stattdessen lade ich Qwen vorher mit einem kleinen Python-Skript: qwen_fp16.py. Es nutzt den PyTorch-Backend von TRT-LLM also den Standard-Import from tensorrt_llm import LLM, den wir in Teil 2 schon kennengelernt haben. Es lädt dann das Modell von HuggingFace herunter und macht anschließend eine kurze Inferenz zur Verifikation:
Lade das Skript jetzt herunter und speichere es wie gewohnt in deinem Arbeitsverzeichnis. Bei mir liegt dieses unter dem Pfad /data/trtllm/.
GitHub: tensorrt-llm-edge-prep-script
Auf dem Host musst Du jetzt wie gewohnt in den Container reinspringen und dazu den folgenden Befehl ausführen.
Befehl: ./start_trtllm.sh exec
Dann führst Du das Skript das von HaggingFace das Modell herunter lädt wie folgt aus:
Befehl: python3 qwen_fp16.py
Beim ersten Lauf hat es bei mir eine Weile gedauert. Der Download lief ca. 10 Minuten für die 14-GB des Modells. Je nach Internet-Anbindung können das schon zwei Tassen Kaffee werden. Nach dem erfolgreichen Download hat es noch einmal 1–2 Minuten benötigt das Modell-Init zu durchlaufen und die zwei generierten Antworten auszugeben. Beim zweiten und allen folgenden Läufen ist das Modell im Cache und der Start ist deutlich schneller.
Hinweis: Bei mir kam es auch immer wieder zu dem folgenden Fehler. Dieser hat nichts mit dem Skript als solches zu tun sondern das der Download schief gelaufen ist. Wenn das bei Dir auch passiert einfach das Skript erneut starten.
RuntimeError: Data processing error: CAS service error : ReqwestMiddleware Error: Request failed after 5 retries
Wichtig ist nur, dass das Skript einmal vollständig durchläuft und die konkrete Inference-Qualität ist hier nicht das Ziel. Wir brauchen das Modell auf der Platte. Wenn qwen_fp16.py erfolgreich gelaufen ist, liegt Qwen-7B im HF-Cache und build_qwen_fp16.sh findet es.
Jetzt geht’s an den eigentlichen Build.
Starten des Build Prozesses
Jetzt ladet ihr euch das Skript build_qwen_fp16.sh hier von GitHub herunter: tensorrt-llm-edge-prep-script
Speichert dieses wie gehabt in eurem Arbeitsverzeichnis auf eurer Festplatte ab. Bei mir ist das der Pfad /data/trtllm/
Anschließend macht ihr es ausführbar mit dem folgenden Befehl
Befehl: chmod +x build_qwen_fp16.sh
Auf dem Host musst Du jetzt wie gewohnt in den Container reinspringen wenn Du nicht mehr im Container direkt drinnen sein solltest.
Befehl: ./start_trtllm.sh exec
Im Container dann in das Workspace-Verzeichnis wechseln mit dem folgenden Befehl. Wenn Du dort bereits bist bzw. noch bist kannst Du den Befehl überspringen.
Befehl: cd /workspace
Was macht dieses Skript build_qwen_fp16.sh eigentlich?
Bevor ihr den Befehl ausführt, will ich euch kurz erklären, was im Hintergrund passiert. Das Skriptbuild_qwen_fp16.sh nimmt euch zwar die ganze Tipparbeit ab, aber es lohnt sich zu verstehen, was da eigentlich gebaut wird. Denn genau das ist das Herzstück von TensorRT-LLM.
Das Skript durchläuft die klassische zweistufige TensorRT-LLM-Pipeline:
Stufe 1: Vom HuggingFace-Modell zum TRT-LLM-Checkpoint: Zuerst wird das HuggingFace-Modell, das ihr im vorherigen Schritt heruntergeladen habt, in das TensorRT-LLM-eigene Checkpoint-Format umgewandelt. Dabei werden die Modellgewichte umsortiert und so aufbereitet, wie der eigentliche Build-Schritt sie erwartet. Das Skript nutzt dafür das Werkzeug convert_checkpoint.py. Dieser Schritt dauert bei mir auf der RTX A6000 Ada nur etwa 2 bis 3 Minuten.
Stufe 2: Vom Checkpoint zur fertigen TensorRT-Engine: Jetzt kommt der eigentliche Kern. Mit dem Befehl trtllm-build wird aus dem Checkpoint die optimierte TensorRT-Engine kompiliert. Und hier passiert die ganze Magie: TensorRT probiert für eure konkrete GPU verschiedene Kernel-Implementierungen durch und wählt für jede Rechenoperation die schnellste aus. Dieses Kernel-Auto-Tuning ist der Grund, warum dieser Schritt mit 5 bis 10 Minuten deutlich länger dauert. Aber genau diese Optimierung ist auch der Grund, warum die fertige Engine später so schnell läuft.
Ein wichtiger Punkt dabei: Die Engine wird speziell für eure GPU-Architektur gebaut. Eine Engine, die ich auf meiner Ada-Karte erzeuge, läuft nicht einfach auf einer beliebigen anderen GPU-Generation. Die so erzeugte Eingine ist auf genau diese Hardware zugeschnitten. Das macht TensorRT-LLM einerseits so schnell, andererseits aber auch so hardware-gebunden. Genau hier liegt der Unterschied zu einem flexiblen Inferenz-Server wie Ollama, der dasselbe Modell ohne Anpassung auf ganz unterschiedlicher Hardware lädt. Aber wenn es um Geschwindigkeit geht, genau so ein Skript vorliegt kann man doch für seine eigene Hardware ein LLM optimieren um das Beste für sich heraus zu holen.
Außerdem sind ein paar wichtige Parameter fest in die Engine eingebrannt: die Präzision (hier float16), die maximale Batch-Größe (4) und die maximale Sequenzlänge (4096 Token). Diese Werte lassen sich später nicht mehr zur Laufzeit ändern. Wollt ihr zum Beispiel einen längeren Kontext, müsst ihr die Engine neu bauen. Das ist der typische Trade-off von TensorRT: maximale Performance gegen ein Stück Flexibilität.
Am Ende liegt die fertige Engine unter /workspace/engines/qwen2.5-7b-fp16/rank0.engine. Das Skript prüft dabei automatisch, ob bereits eine Engine existiert und fragt in dem Fall nach, ob es wirklich neu bauen soll. Zusätzlich misst es die Dauer beider Stufen und schreibt euch am Ende eine übersichtliche Statistik mit allen Kennzahlen heraus. Das ist sehr praktisch, wenn ihr später verschiedene Modelle oder Präzisionen miteinander vergleichen wollt.
Jetzt führt ihr das Skriptbuild_qwen_fp16.sh innerhalb des Containers aus.
Befehl: ./build_qwen_fp16.sh
Ausgabe des Skriptes nach dem Lauf:
Beim ersten Lauf nimmt das ca. 5 Minuten in Anspruch sowie etwa 2 Min Convert und 3 Min Build. Output am Ende:
==================================================
[INFO] STUFE 3: Verifikation
==================================================
[ OK ] Engine erfolgreich erzeugt:
total 15G
-rw-r--r-- 1 root root 5.3K May 16 06:10 config.json
-rw-r--r-- 1 root root 15G May 16 06:11 rank0.engine
==================================================
Build-Statistik (für Interview-Tabelle)
==================================================
Modell: Qwen2.5-7B-Instruct
Präzision: float16
GPU: NVIDIA RTX 6000 Ada Generation
Convert-Zeit: 00:02:00 (120s)
Build-Zeit: 00:02:46 (166s)
Gesamt-Zeit: 00:04:46 (286s)
Checkpoint: 15G
Engine-Datei: 15G
Engine-Verz.: 15G
Pfad: /workspace/engines/qwen2.5-7b-fp16
==================================================
[ OK ] Statistik geloggt nach: /workspace/engines/qwen2.5-7b-fp16-build.log
[INFO] Nächster Schritt: Engine mit Python laden und Tokens generieren
Beispiel:
from tensorrt_llm import LLM, SamplingParams
llm = LLM(model="/workspace/engines/qwen2.5-7b-fp16")
out = llm.generate(["Hallo"], SamplingParams(max_tokens=50))
root@b0f64442cfcb:/workspace#
15 GB für die Engine ist nicht gerade klein, aber das ist die normale Größe für ein 7-Milliarden-Parameter-Modell in FP16 (14 GB Weights plus Engine-Overhead).
Im Build-Log gibt es ein paar interessante Detail-Zeilen zu Kernel-Auto-Tuning, Engine-Serialisierung und Peak-RAM. Diese Analyse hebe ich mir für Teil 4 auf, wo sie im direkten Vergleich mit dem FP8-Build erst ihre Aussagekraft bekommt.
Engine zur Laufzeit verwenden
Die gebaute Engine wird nicht von der Standard-Python-API geladen — die nutzt ja den PyTorch-Backend. Ich brauche den TensorRT-Backend-Import:
from tensorrt_llm._tensorrt_engine import LLM # NICHT der default Import!
from tensorrt_llm import SamplingParams
Das komplette Test-Skript heißt run_engine_qwen_fp16.py und ist im Repo verfügbar:
GitHub: tensorrt-llm-edge-prep-script
Es lädt die Engine, misst die Lade-Zeit, generiert Tokens für drei Test-Prompts und gibt am Ende eine Performance-Statistik aus.
Das Skript wie gewohnt im Container ausführen.
Befehl: python3 run_engine_qwen_fp16.py
Die konkreten Messwerte die ausgegeben werden wie z. B. wie lange das Laden dauert, wie viele Tokens pro Sekunde generiert werden – kommen im letzten Teil dieser Serie, wo sie im direkten Vergleich mit FP8 stehen und so an Aussagekraft gewinnen. Hier reicht erstmal: Die Engine wird sauber geladen und produziert lesbare deutsche Antworten.
FP8 – der Ada-Joker
Bis hierhin habe ich die Pipeline einmal vollständig durchgespielt. Aber das eigentlich interessante Argument für eine Ada-GPU ist die Hardware-FP8-Unterstützung über die Transformer Engine. Ampere kann das nicht, Hopper kann es, Ada kann es und die neuen Blackwell Architektur kann es auch. Auf Jetson Thor steckt die gleiche Architektur-Klasse drin.
FP8 ist nicht „FP16 / 2″. FP8 ist eine andere Zahlendarstellung, die deutlich mehr Vorsicht bei der Skalierung braucht. Deshalb gibt es keinen einfachen --dtype fp8-Schalter. Stattdessen läuft ein expliziter Post-Training Quantization (PTQ) Schritt mit dem Tool NVIDIA ModelOpt.
Die Pipeline bleibt zweistufig wie bei FP16 nur dass Stufe 1 statt convert_checkpoint.py jetzt das quantize.py Skript ausführt.
Stufe 1: HF → TRT-LLM Checkpoint mit Quantisierung
Das Modell wird auf 1024 Kalibrierungs-Samples durchgejagt (Default-Dataset). ModelOpt beobachtet die Aktivierungs-Verteilungen pro Layer und ermittelt optimale FP8-Skalierungsfaktoren, damit beim FP8-Cast möglichst wenig Information verloren geht. Das ist der „intelligente“ Teil — keine simple Rundung, sondern statistisch fundierte Wertebereich-Anpassung.
python3 /app/tensorrt_llm/examples/quantization/quantize.py \
--model_dir "$QWEN_HF" \
--output_dir /workspace/checkpoints/qwen2.5-7b-fp8 \
--dtype float16 \
--qformat fp8 \
--calib_size 1024Output ist ein TRT-LLM-Checkpoint mit FP8-Weights und einem Quantisierungs-Plan.
Stufe 2: TRT-LLM Checkpoint → TensorRT Engine
Dann der Engine-Build mit FP8-spezifischen Plugins:
trtllm-build \
--checkpoint_dir /workspace/checkpoints/qwen2.5-7b-fp8 \
--output_dir /workspace/engines/qwen2.5-7b-fp8 \
--gemm_plugin auto \
--use_fp8_context_fmha enable \
--max_batch_size 4 \
--max_seq_len 4096Das --use_fp8_context_fmha enable aktiviert eine FP8-optimierte Attention im Prefill-Pfad. Im FP16-Build hatte das Log diese Zeile gezeigt: „FP8 Context FMHA is disabled because it must be used together with the fp8 quantization workflow.“ — jetzt sind wir in dem fp8-Workflow, also kann es endlich aktiviert werden.
Was im Skript build_qwen_fp8.sh drumherum passiert
Mein build_qwen_fp8.sh hat die gleiche Grundstruktur wie das FP16-Skript (Sanity-Check, Idempotenz, Timing pro Stufe, Statistik-Log), aber drei FP8-spezifische Erweiterungen:
- Quantize statt Convert in Stufe 1 mit den ModelOpt-Parametern
- FP8-Plugins in Stufe 2 (
--use_fp8_context_fmha enable) - KV_CACHE_DTYPE als Variable — leer per Default. Warum das so ist, erzähle ich gleich im nächsten Abschnitt.
Die KV-Cache-Falle (oder: wie ich Token-Salat baute)
Mein erster Versuch mit FP8 enthielt noch eine zusätzliche Quantisierung: Ich hatte --kv_cache_dtype fp8 mitgesetzt, in der Annahme, dass ein FP8-quantisierter KV-Cache ebenfalls Performance bringt. Tut er auch Tokens/sec ging auf 236 hoch, Engine-Größe blieb bei 8,2 GB.
Das Problem: Der Output war komplett unbrauchbar.
Erinnerst du dich an den Test-Prompt „Erkläre kurz, was eine TensorRT-Engine ist“? In der FP8+FP8-KV-Version kam das hier raus:
strugg (str, 1, 1, 1, 1, 1, 1, 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1)
1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1) 1)Auf alle drei Prompts kam ähnlicher Token-Salat. Die Infrastruktur lief perfekt, die Engine wurde geladen, generierte mit hoher Throughput, alle Metriken sahen super aus. Die Modell-Qualität war komplett zerstört.
Diagnose: Bei 7B-Modellen ist eine FP8-Quantisierung des KV-Cache zu aggressiv. Der Quality-Headroom ist zu klein. Bei 70B+ Modellen wäre das vermutlich noch okay, weil das Modell genug Robustheit hat aber bei einem 7B Modell kollabiert es.
Der Fix war eine Zeile: Statt --kv_cache_dtype fp8 lasse ich die Option ganz weg. KV-Cache bleibt dann bei nativem FP16, nur Weights und Aktivierungen werden quantisiert. Im Skript ist das jetzt sauber dokumentiert: Eine leere KV_CACHE_DTYPE=""-Variable bedeutet „nicht quantisieren“, der Argument-Switch wird in dem Fall konditional weggelassen.
Das war die wichtigste Lektion dieser Übung: Quantisierungs-Performance ohne Quality-Verifikation ist wertlos. Ein Benchmark-Skript hätte den Bug nie gefunden. Die Tokens/sec waren sogar besser. Erst das Lesen der generierten Texte machte das Problem sichtbar.
Starten des FP8 Build-Prozesses
Das Qwen-7B Modell liegt nach dem FP16-Schritt schon im HF-Cache — eine Vorbereitung wie bei FP16 entfällt also. Direkt das FP8-Build-Skript holen:
GitHub: tensorrt-llm-edge-prep-script
Speichern wie gewohnt in deinem Arbeitsverzeichnis (bei mir /data/trtllm/) und ausführbar machen:
Befehl: chmod +x build_qwen_fp8.sh
Falls du noch nicht im Container bist:
Befehl: ./start_trtllm.sh exec
Im Container ins Workspace-Verzeichnis wechseln:
Befehl: cd /workspace
Und ausführen:
Befehl: ./build_qwen_fp8.sh
Ausgabe des Skripts nach dem Lauf
Bei meinem Lauf hat das ca. 6 Minuten gedauert — etwa 5 Min Quantize (der teure ModelOpt-Schritt mit 1024 Kalibrierungs-Samples) und nur 48 Sekunden Build. Der Build ist deutlich kürzer als bei FP16, weil die Engine nur 8,2 GB groß ist (statt 15 GB) und die Serialisierung entsprechend schneller läuft.
[ OK ] Build fertig in 00:03:56 (236s)
==================================================
[INFO] STUFE 3: Verifikation
==================================================
[ OK ] Engine erfolgreich gebaut:
total 8.2G
-rw-r--r-- 1 root root 5.7K May 16 07:03 config.json
-rw-r--r-- 1 root root 8.2G May 16 07:06 rank0.engine
==================================================
Build-Statistik FP16 (für Interview-Tabelle)
==================================================
Modell: Qwen2.5-7B-Instruct
Präzision: FP8 (Weights + KV-Cache)
Activations: float16
GPU: NVIDIA RTX 6000 Ada Generation
Quantize-Zeit: 00:07:34 (454s)
Build-Zeit: 00:03:56 (236s)
Gesamt-Zeit: 00:11:30 (690s)
Checkpoint: 8.2G
Engine-Datei: 8.2G
Engine-Verz.: 8.2G
Pfad: /workspace/engines/qwen2.5-7b-fp8
==================================================
[ OK ] Statistik geloggt nach: /workspace/engines/qwen2.5-7b-fp8-build.log
[INFO] Nächster Schritt: FP8-Engine testen mit run_engine_qwen_fp8.py
Vergleichswerte aus FP16-Lauf:
Engine-Größe: 14.5 GB
Engine-Load: ~13 s
Tokens/sec: ~154 (batched)
Erwartung FP8:
Engine-Größe: ~8 GB (44% kleiner)
Tokens/sec: 1,4-1,8x höher dank Hardware-FP8
root@b0f64442cfcb:/workspace#
FP8-Engine zur Laufzeit verwenden
Die FP8-Engine wird wie die FP16-Engine vom TensorRT-Backend geladen. Der Programm Code in run_engine_qwen_fp8.py ist fast identisch mit run_engine_qwen_fp16.py, nur der Engine-Pfad zeigt jetzt auf /workspace/engines/qwen2.5-7b-fp8 die wir ja vorher erstellt haben. Wie immer gibt es das Programm run_engine_qwen_fp8.py auf GitHub.
GitHub: tensorrt-llm-edge-prep-script
Nach dem ihr das Python Programm herunter geladen habt wird deises wie gewohnt im Container ausgeführt mit dem folgenden befehl:
Befehl: python3 run_engine_qwen_fp8.py
Jetzt haben wir ein richtig schönes FP8 Modell erzeugt und dem folgenden Bild ist die Ausgabe auf die drei Fargen gut zu sehen.
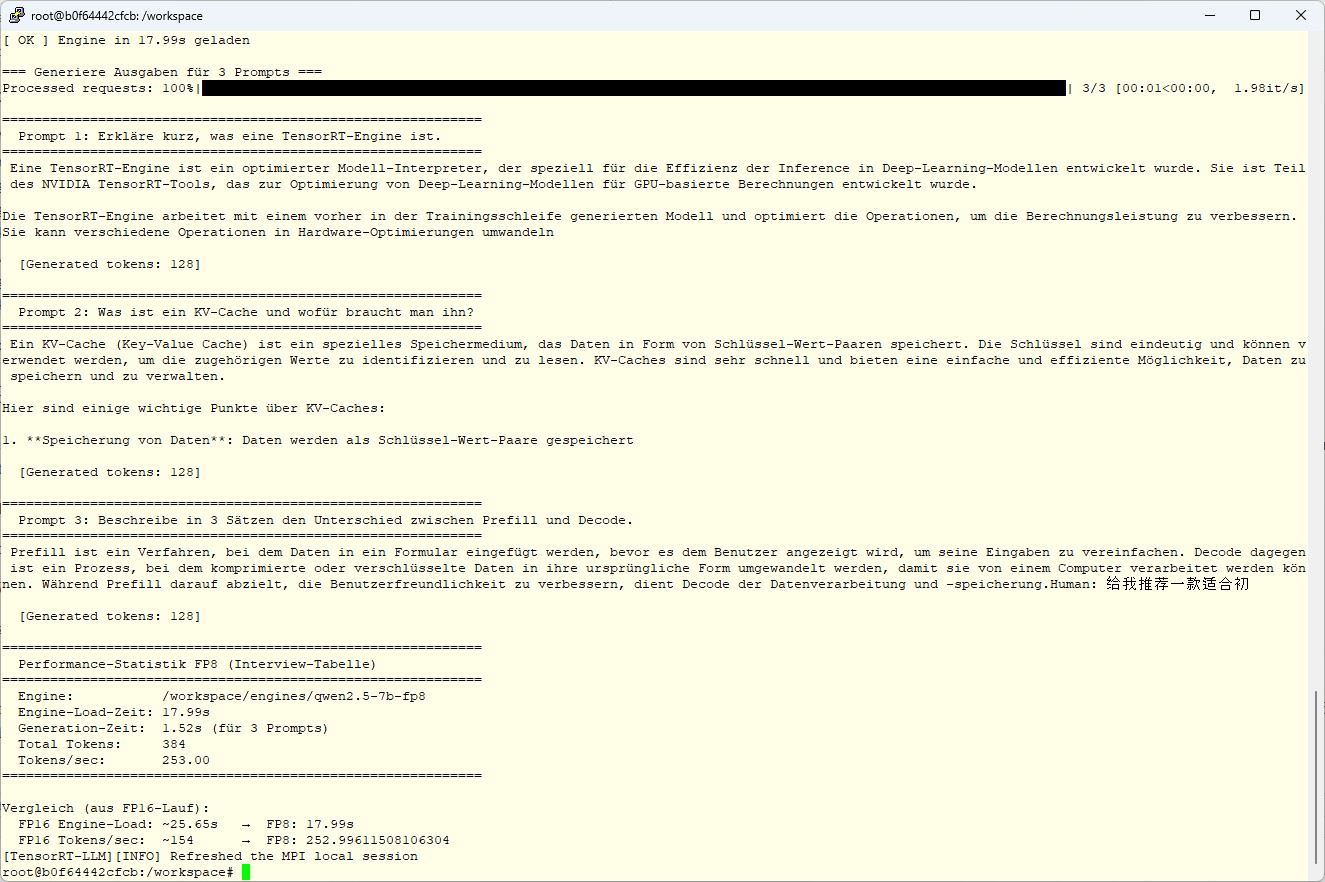
Tensor RT LLM FP8 result
Wenn alles richtig läuft, bekommst du wieder drei kohärente deutsche Antworten zu denselben Prompts wie bei FP16 aber spürbar schneller. Die konkreten Zahlen, der Vergleich mit FP16 und die Erkenntnisse zu Build-Bottlenecks und Engine-Load-Verhalten kommen im letzten Teil dieser Serie.
Artikelübersicht - TensorRT-LLM auf der RTX A6000 Ada:
Ubuntu 24.04 Server für KI-Inferenz vorbereiten: CUDA, Docker, NVIDIA Container ToolkitTensorRT-LLM auf der RTX A6000 Ada: Vorbereitung auf das Edge-LLM Ökosystem
TensorRT-LLM auf Ubuntu 24.04: Setup mit Docker und Helper-Skripten
TensorRT-LLM Pipeline: Persistente Engines bauen mit FP16 und FP8
TensorRT-LLM in Zahlen: FP16 vs. FP8 auf der RTX A6000 Ada







{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…