
Ein Bekannter hat mir Chatterbox empfohlen mich damit einmal zu beschäftigen. Er nutzt Chatterbox als Sprachausgabe für einen Roboter den erzusammen mit seinem Sohn baut. Ich habe Chatterbox ausprobiert und bin begeistert. Daher wird es diesmal eine etwas umfassendere und praxisnahere Anleitung. Im Fokus für mich stand der Betrieb dieser kleinen aber feinen AI-Anwendungen auf meinem dedizierten Ubuntu Server mit zwei NVIDIA RTX A6000 GPUs. In diesem Beitrag zeige ich, wie ich eine vollständig entkoppelte und persistente Text-to-Speech (TTS)-Anwendung auf Basis des Chatterbox Multilingual TTS Modells implementiert habe.
Das besondere Augenmerk liegt hier auf der Microservices-Architektur, bei der das Backend (der eigentliche Synthese-Service) strikt vom Frontend (der Benutzeroberfläche) getrennt ist. Dieser Aufbau ist essenziell für skalierbare, sich nicht-blockierende Workflows. Denn aktuell bin ich mir noch nicht sicher wo überall ich eine Sprachausgabe gebrauchen kann aber an Ideen fehlt es mir dazu nicht. Auch werden die großen Open Source Sprachenmodelle immer besser wie z. B. das GPT-OSS 120B Modell von OpenAI. Auch unterstützt Chatterbox Voice-Cloning was ich super spannend finde um der Stimme noch einen eigenen Ton mitgeben zu können.
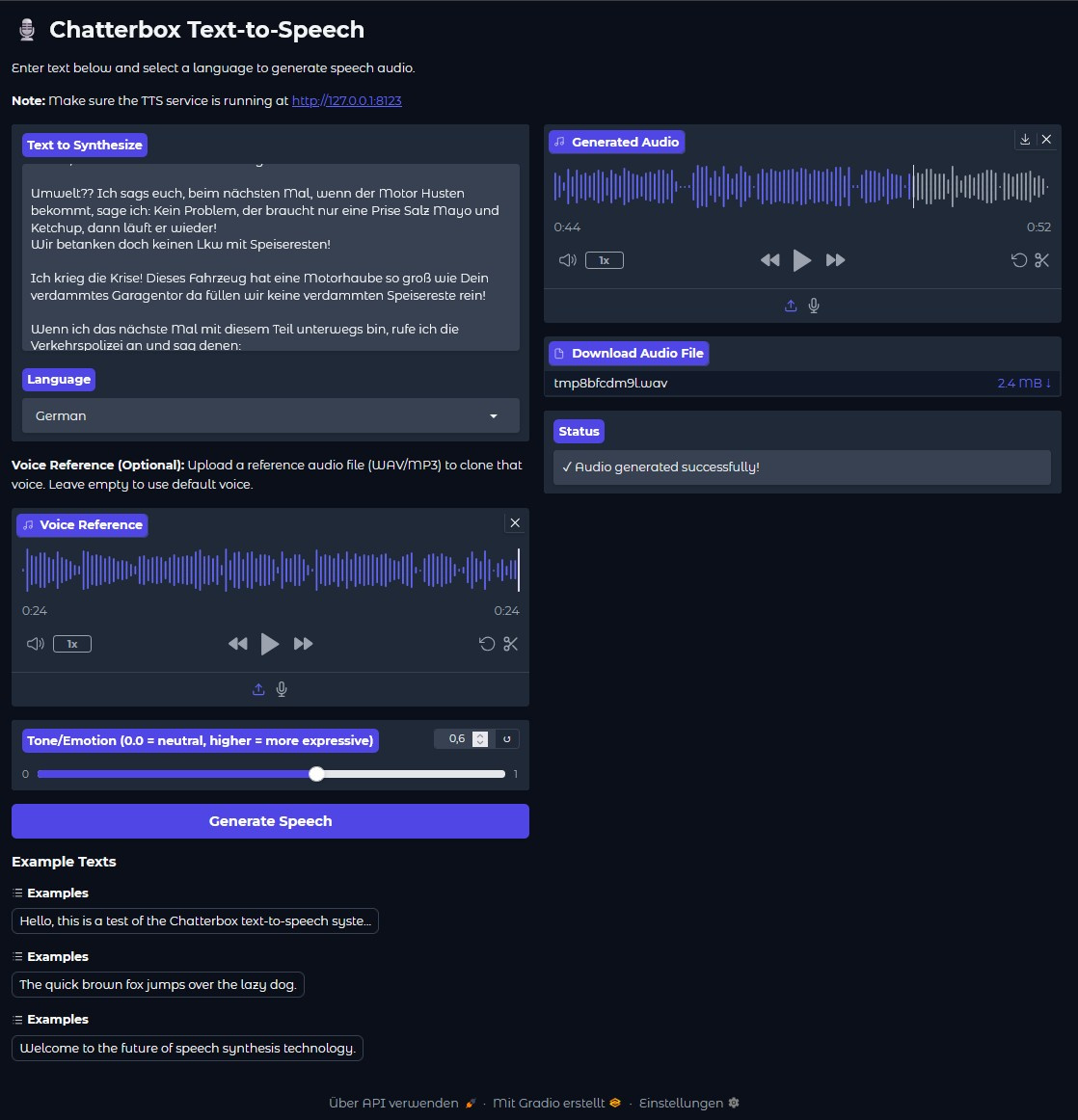
Chatterbox – Text-to-Speech web app
Die Service Architektur
Ich habe mich dazu entschieden, die Chatterbox TTS-Anwendung als Service zu implementieren, um eine leistungsstarke und mehrsprachige Sprachausgabe auf meinem Server bereitzustellen die ich von beliebigen Clients aus aufrufen kann. Mein primäres Ziel war dabei nicht nur die Funktionalität, sondern die modulare und persistente Ausführung.
Die Architektur der Anwendung basiert auf zwei Hauptkomponenten:
-
TTS Service (FastAPI): Zunächst einmal der Kern-Service, der die komplexe Logik der Text-to-Speech-Synthese, die GPU-Nutzung und das Job-Management im Hintergrund übernimmt. Dieser läuft auf Port 8123 da der default Port 8000 bei mir bereits belegt ist.
-
Gradio Frontend: Eine leichtgewichtige Weboberfläche, die als reiner Test-Client dient, Eingaben entgegennimmt, diese an den Service sendet und regelmäßig den Status abfragt (Polling). Dieser läuft auf Port 7123. Ob die Implementierung über Polling so ideal ist für den Client glaube ich nicht aber hier geht es auch draum das Setup testen zu können.
Diese Entkopplung stellt sicher, dass die Benutzeroberfläche nicht blockiert wird, während die GPU im Hintergrund rechenintensive Aufgaben durchführt. Alle Synthese-Jobs werden zudem persistent gespeichert, was Ausfallsicherheit garantiert und dem Client die Möglichkeit gibt mit der passenden ID Jederzeit auch Tage später noch die generierte Audio-Datei abrufen zu können.
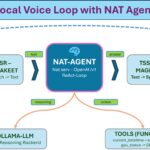
Architektur und Datenfluss
Bevor es mit der Installation losgeht, stelle ich euch die Architektur im Detail vor. Das Herzstück des Setups ist, dass die gesamte Anwendung ist als asynchroner Workflow konzipiert ist:
-
Start: Ein Nutzer gibt Text und Parameter über das Gradio UI also seinen Client ein.
-
Job-Anlegen: Der Client (hier aktuell das Gradio Frontend) sendet eine POST-Anfrage an den
/tts/synthesize-Endpunkt des FastAPI Chatterbox Service. Diese POST-Anfrage erhält eine eindeutige JOB-ID diechatterbox_id. -
Hintergrundverarbeitung: Der FastAPI Service startet die Synthese in einem dedizierten Hintergrund-Thread, um die API-Verbindung sofort freizugeben. Die Anfrage liefert eine eindeutige
chatterbox_idzurück an den rufenden Client. -
Persistenz: Der Service speichert den Job-Status in einer JSON-Datei im persistenten Speicherort (
/var/chatterbox_jobs/). -
Status-Polling: Das Gradio Frontend fragt periodisch den Status des Jobs über den
/tts/status/{job_id}-Endpunkt ab, bis der Status aufCOMPLETEwechselt. Dieses Polling habe ich umgesetzt da es für mich zum Testen gut funktioniert. -
Ergebnis bereitstellen: Nach Fertigstellung der Audiodatei liefert der Service die generierte
.wav-Datei aus, die dann im Gradio UI zur Wiedergabe und zum Download bereitsteht. Auch hier bestünde die Möglichkeit die Datei in verschiedenen Formaten zurück zu geben aber das habe ich noch nicht implementiert.
Das Architekturbild habe ich von Nano Banana anhand eines kurzen Prompt erstellen lassen und muss sagen es trifft ganz gut die zugrunde liegende Architektur.
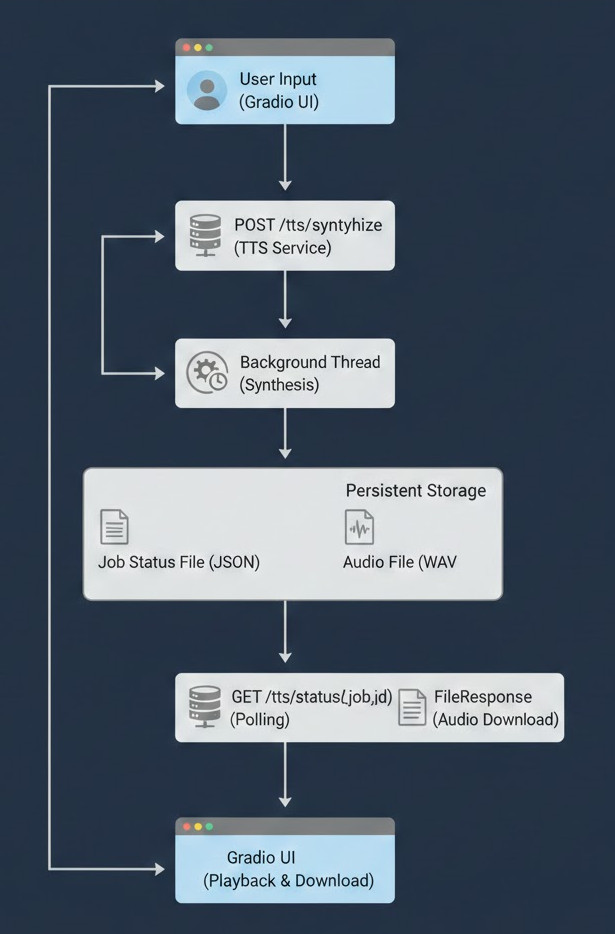
Chatterbox web-app Architecture
Vorbereitung des Ubuntu Servers
Nach der theoretischen Vorstellung geht es jetzt zum Praktischenteil. Der erste Schritt ist die Vorbereitung des Ubuntu Server 22.04 LTS. Ich setze voraus, dass die passenden NVIDIA-Treiber und die entsprechende CUDA-Version (für dieses Modell: CUDA 12.1) bereits korrekt installiert sind, um die GPU-Beschleunigung überhaupt durch Chatterbox nutzen zu können.
Der zentrale Punkt für die Persistenz ist die Einrichtung des Speicherverzeichnisses in dem alle Dateien abgelegt und verwaltet werden:
# 1. Erstellen des persistenten Speicherverzeichnisses
sudo mkdir -p /var/chatterbox_jobs
# 2. Festlegen der korrekten Berechtigungen
# Ich stelle sicher, dass mein aktueller Benutzer Schreib- und Leserechte hat
sudo chown -R $USER:$USER /var/chatterbox_jobs
Diese Maßnahme ist kritisch, da der TTS Service in diesem Verzeichnis die Status-Dateien und die finalen Audio-Dateien ablegt.
Hinweis:
Aktuell habe ich noch nichts implementiert das ein Client über die chatterbox_id die Audio-Datei z. B. löschen kann oder der Service selber Dateien die älter sind als 30 Tage löscht. Das wäre noch etwas für die ToDo Liste.
Hier geht es weiter zu Teil 2 der im Detail auf die Installation eingeht.





{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…