

Wer einen leistungsstarken Server mit zwei NVIDIA GPUs (wie z.B. zwei RTX A6000) betreibt, stößt bei der Standard-Installation von Ollama schnell auf ein Problem: Ollama verwaltet Anfragen standardmäßig in einer Warteschlange (Queue). Selbst mit 96 GB VRAM warten parallele Jobs oft aufeinander, anstatt gleichzeitig berechnet zu werden.
Die Lösung? Wir lassen zwei getrennte Ollama-Instanzen laufen!
In diesem Tutorial zeige ich dir, wie du Ollama so konfigurierst, dass Instanz A exklusiv auf GPU 0 (Port 11434) und Instanz B exklusiv auf GPU 1 (Port 11435) läuft. Das Ergebnis: Echte Parallelität und saubere Speichertrennung.
Die Voraussetzungen
-
Ein Ubuntu Server mit installierten NVIDIA-Treibern.
-
Zwei NVIDIA GPUs.
-
Ollama ist bereits installiert (Standard-Installation).
-
Optional: Ein dedizierter Pfad für Modelle (um Speicherplatz zu sparen).
Schritt 1: GPUs identifizieren
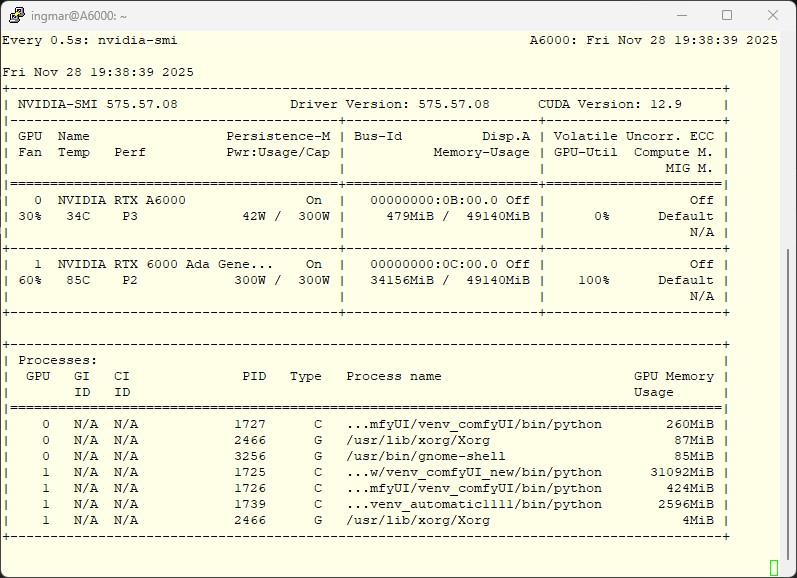
Zuerst verschaffen wir uns einen Überblick über die Hardware-IDs.
Befehl: nvidia-smi
In der Regel sind die GPUs von 0 bis 1 durchnummeriert. Unser Ziel:
-
Ollama 1: GPU 0
-
Ollama 2: GPU 1
Ollama multi instance
Schritt 2: Die erste Instanz einschränken (GPU 0)
Der Standard-Service von Ollama (ollama.service) versucht oft, alle Ressourcen zu greifen. Wir zwingen ihn mittels systemd override auf die erste Karte.
Führe folgenden Befehl aus:
Befehl: sudo systemctl edit ollama.service
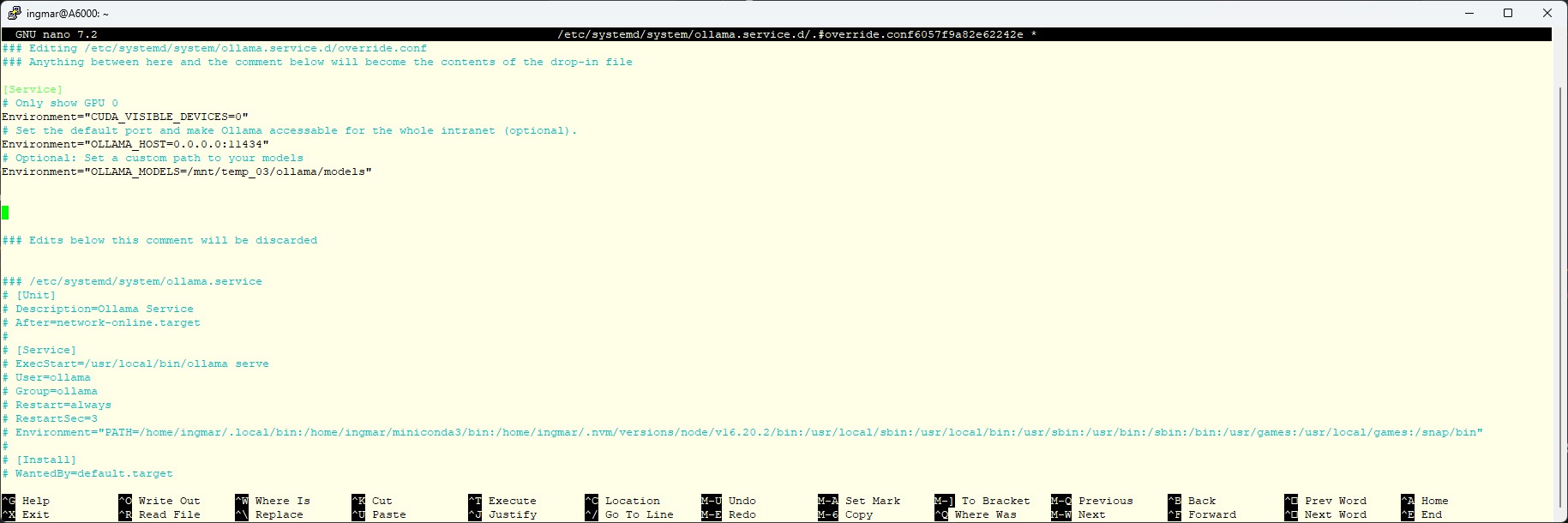
Füge im Editor folgenden Inhalt ein. Dies überschreibt die Umgebungsvariablen, ohne die Originaldatei anzufassen:
[Service]
# Nur GPU 0 sichtbar machen
Environment="CUDA_VISIBLE_DEVICES=0"
# Standard-Port explizit setzen (optional, aber sauber)
Environment="OLLAMA_HOST=0.0.0.0:11434"
# Optional: Falls du einen custom Model-Pfad hast
Environment="OLLAMA_MODELS=/mnt/dein/pfad/zu/modellen"
Ollama multi instance set variables
Schritt 3: Die zweite Instanz erstellen (GPU 1)
Für die zweite GPU erstellen wir einen komplett neuen Service. Wir kopieren im Grunde die Logik des ersten, ändern aber den Port und die GPU-ID.
Erstelle die Datei /etc/systemd/system/ollama-2.service:
Befehl: sudo nano /etc/systemd/system/ollama-2.service
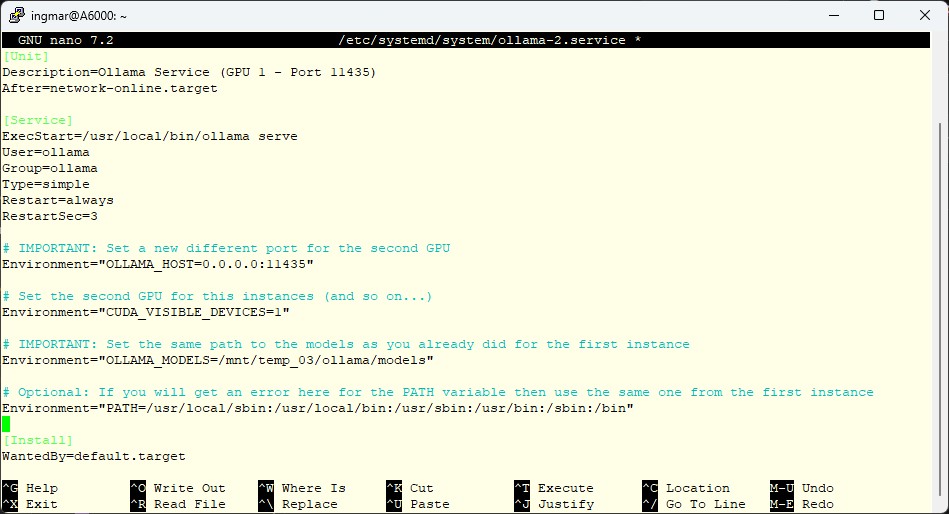
[Unit]
Description=Ollama Service (GPU 1 - Port 11435)
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Type=simple
Restart=always
RestartSec=3
# WICHTIG: Neuer Port und zweite GPU
Environment="OLLAMA_HOST=0.0.0.0:11435"
Environment="CUDA_VISIBLE_DEVICES=1"
# WICHTIG: Nutze denselben Modell-Pfad wie Instanz 1!
# So müssen Modelle nur einmal heruntergeladen werden.
Environment="OLLAMA_MODELS=/mnt/dein/pfad/zu/modellen"
# Optional: Path Variable (falls nötig)
Environment="PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
[Install]
WantedBy=default.target
Hinweis: Achte darauf, dass der Pfad bei OLLAMA_MODELS in beiden Services identisch ist, damit sich die Instanzen den Speicherplatz teilen.
Ollama second instance set variables
Schritt 4: Aktivierung
Jetzt müssen wir Systemd neu laden und die Dienste starten.
# Systemd Configs neu einlesen
sudo systemctl daemon-reload
# Erste Instanz neustarten (damit sie GPU 1 freigibt)
sudo systemctl restart ollama
# Zweite Instanz aktivieren (Autostart) und starten
sudo systemctl enable ollama-2
sudo systemctl start ollama-2
Schritt 5: Der Test der beiden Ollama Instanzen
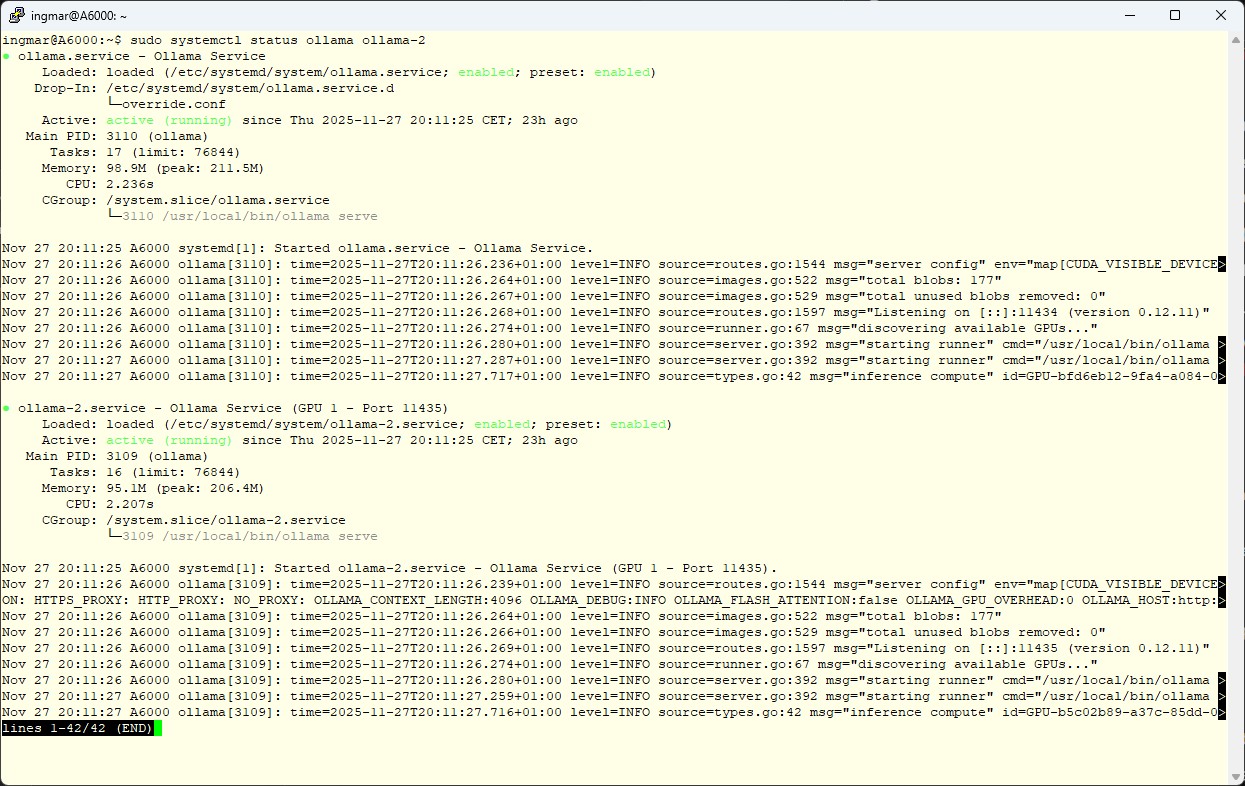
Laufen beide Instanzen?
Befehl: sudo systemctl status ollama ollama-2
Wenn beide grün (active) sind, kannst du sie testen.
Ollama check if all instances are running
Instanz 1 ansprechen (GPU 0): Ganz normal über den Standard-Befehl:
Befehl: ollama run llama3
Instanz 2 ansprechen (GPU 1): Hier geben wir den Host/Port mit:
Befehl: OLLAMA_HOST=127.0.0.1:11435 ollama run llama3
Profi-Tipp zur Überprüfung
Öffne ein zweites Terminal und starte watch -n 0.5 nvidia-smi. Wenn du nun Anfragen an die unterschiedlichen Ports schickst, wirst du sehen, wie sich der VRAM und die GPU-Last exakt auf die Karte verteilt, die du angesprochen hast.
Fazit
Mit wenigen Zeilen Konfiguration hast du deinen Server in ein paralleles Inferenz-Cluster verwandelt. Du kannst nun Agenten, RAG-Pipelines oder Trainings-Jobs sauber getrennt voneinander laufen lassen, ohne dass sie sich gegenseitig blockieren. Ein weiterer Vorteil ist das Du jetzt gezielt die Last auf die beiden oder mehr GPUs in Deinem System verteilen kannst.
Viel Erfolg beim Setup!


{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…