

Nachdem ich in meinen vorherigen Beiträgen gezeigt habe, wie ihr Ollama, Open WebUI, LLaMA Factory, vLLM, ComfyUI und das AI Toolkit auf dem Gigabyte AI TOP ATOM installiert, kommt jetzt eine weitere interessante Alternative für alle, die eine benutzerfreundliche GUI-Oberfläche für lokale Large Language Models suchen und eben nicht Ollama verwenden möchten: LM Studio – eine intuitive Desktop-Anwendung mit integrierter Chat-Oberfläche und OpenAI-kompatibler API, die jetzt auch für Linux ARM64 verfügbar ist.
In diesem Beitrag zeige ich euch, wie ich LM Studio auf meinem Gigabyte AI TOP ATOM installiert und so konfiguriert habe, dass es im gesamten Netzwerk als privater LLM-Server erreichbar ist. LM Studio nutzt die GPU-Performance der Blackwell GPU und bietet sowohl eine grafische Benutzeroberfläche als auch eine OpenAI-kompatible API für die Integration in eigene Anwendungen. Da das AI TOP ATOM System von Gigabyte auf der gleichen Plattform wie die NVIDIA DGX Spark basiert, funktionieren die offiziellen Installationsanleitung von LM-Studio hier ebenso.
Hinweis: Für meine Erfahrungsberichte hier auf meinem Blog habe ich den Gigabyte AI TOP ATOM von der Firma MIFCOM ausgeliehen bekommen.
Die Grundidee: Benutzerfreundliche GUI mit integrierter Chat-Oberfläche und API-Server
Bevor ich in die technischen Details einsteige, ein wichtiger Punkt: LM Studio ist eine Desktop-Anwendung, die sowohl eine grafische Benutzeroberfläche für das direkte Chatten mit LLMs bietet als auch einen integrierten API-Server, der über das Netzwerk erreichbar gemacht werden kann. Im Gegensatz zu reinen Kommandozeilen-Tools oder Web-Interfaces bietet LM Studio eine native Desktop-Anwendung, die sich wie eine normale Software-Anwendung anfühlt.
Das Besondere daran: LM Studio unterstützt jetzt Linux ARM64 (aarch64), was bedeutet, dass es direkt auf dem Gigabyte AI TOP ATOM läuft. Die Anwendung nutzt eine neue Variante des llama.cpp-Engines mit CUDA 13-Unterstützung, was perfekt für die Blackwell-Architektur ist. Ihr könnt LM Studio sowohl lokal auf dem AI TOP ATOM nutzen als auch als privaten LLM-Server für euer gesamtes Netzwerk konfigurieren.
Was ihr dafür braucht:
-
Einen Gigabyte AI TOP ATOM, ASUS Ascent, MSI EdgeXpert (oder NVIDIA DGX Spark) der mit dem Netzwerk verbunden ist
-
Einen angeschlossenen Monitor oder Terminal-Zugriff auf den AI TOP ATOM
-
Grundkenntnisse in Terminal-Befehlen
-
Mindestens 20 GB freien Speicherplatz für die AppImage-Datei und Modell-Downloads
-
Eine Internetverbindung zum Download der LM Studio AppImage und von Modellen
-
Optional: Einen Computer im gleichen Netzwerk für API-Tests
Phase 1: System-Voraussetzungen prüfen
Ich gehe jetzt bei meiner weiteren Anleitung davon aus, dass ihr direkt vor dem AI TOP ATOM sitzt und einen Monitor, Keyboard und Maus angeschlossen habt. Zuerst prüfe ich, ob alle notwendigen System-Voraussetzungen erfüllt sind. Dazu öffne ich ein Terminal auf meinem AI TOP ATOM und führe die folgenden Befehle aus.
Der nachfolgende Befehl zeigt euch, ob das CUDA Toolkit installiert ist:
Befehl: nvidia-smi
Ihr solltet jetzt die GPU-Informationen sehen. Falls nicht, müsst ihr zuerst die NVIDIA-Treiber installieren.
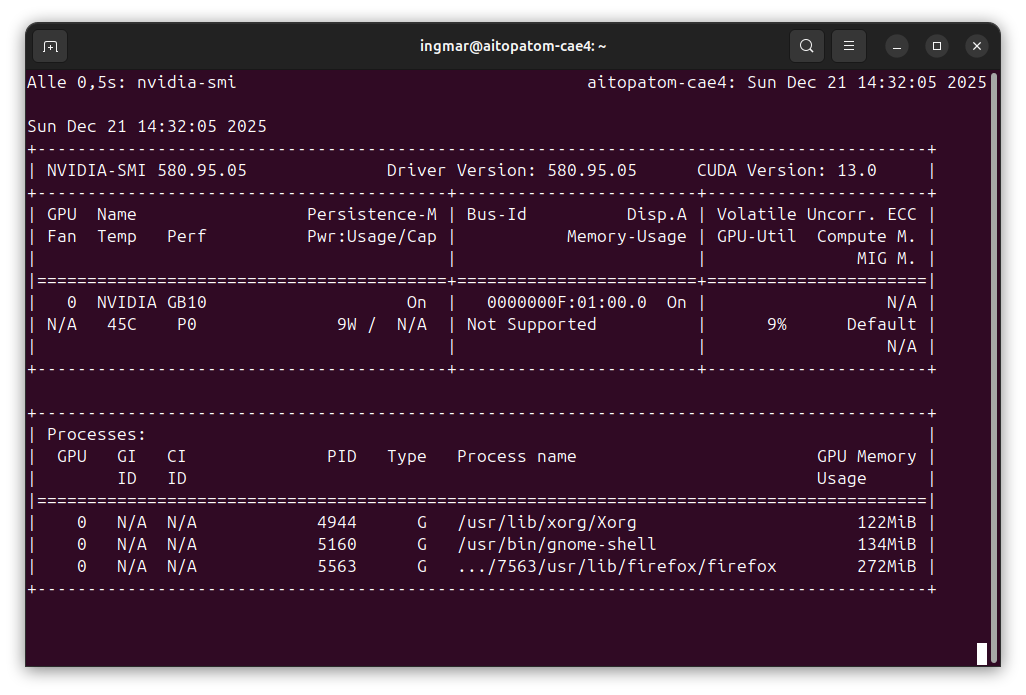
GIGABYTE AI TOP ATOM – NVIDIA-SMI
Phase 2: LM Studio AppImage herunterladen
LM Studio wird als AppImage-Datei für Linux ARM64 bereitgestellt. Eine AppImage ist eine portable Anwendung, die keine Installation benötigt – einfach herunterladen, ausführbar machen und starten. Zuerst erstelle ich ein Verzeichnis für LM Studio:
Befehl: mkdir -p ~/lm-studio
Befehl: cd ~/lm-studio
Jetzt lade ich die LM Studio Linux ARM64 AppImage von der offiziellen Download-Seite herunter:
Befehl: wget https://lmstudio.ai/download/latest/linux/arm64 -O LM_Studio-linux-arm64.AppImage
Hinweis: Falls der direkte Download-Link nicht funktioniert, besucht die offizielle LM Studio Download-Seite und wählt die Linux ARM64 Version manuell aus.
Nach dem Download mache ich die AppImage-Datei ausführbar:
Befehl: chmod +x LM_Studio-linux-arm64.AppImage
Die AppImage-Datei ist jetzt bereit zum Starten. Je nach Internetgeschwindigkeit kann der Download einige Minuten dauern – die Datei ist etwa 200-300 MB groß.
Phase 3: LM Studio starten
Jetzt kann ich LM Studio starten. Da es sich um eine GUI-Anwendung handelt, benötigt ihr einen Desktop-Umgebung also msst vor dem Gigabyte AI TOP ATOM sitzen. Ich musste noch --no-sandbox übergeben da ich eine Fehlermeldung bekommen hatte das spezielle Root-Rechte benötigt werden..
Befehl: ./LM_Studio-linux-arm64.AppImage --no-sandbox
Beim ersten Start kann es einige Sekunden dauern, bis die Anwendung geladen ist. LM Studio öffnet sich dann mit der Hauptoberfläche, die verschiedene Tabs bietet: Chat, Models, Server und Developer.
GIGABYTE AI TOP ATOM – LM-Studio first start
Phase 4: Modell herunterladen
Bevor ihr mit LM Studio chatten könnt, müsst ihr ein Modell herunterladen. LM Studio bietet eine integrierte Modell-Bibliothek, über die ihr Modelle direkt aus der Anwendung heraus herunterladen könnt. Alternativ könnt ihr Modelle auch über die Kommandozeile mit dem LM Studio CLI herunterladen.
Für die Kommandozeile-Installation nutze ich das LM Studio CLI-Tool lms, das mit der AppImage mitgeliefert wird. Zuerst prüfe ich, ob das CLI verfügbar ist:
Befehl: ./LM_Studio-linux-arm64.AppImage --help
Um ein Modell herunterzuladen, habe ich innerhalb LM-Studio nach passenden Modellen gesucht und diese über die Oberfläche herunter geladen. Öffnet den Tab „Models“ in LM Studio, sucht nach einem Modell wie „gpt-oss“ oder „Qwen3 Coder“ und klickt auf „Download“.
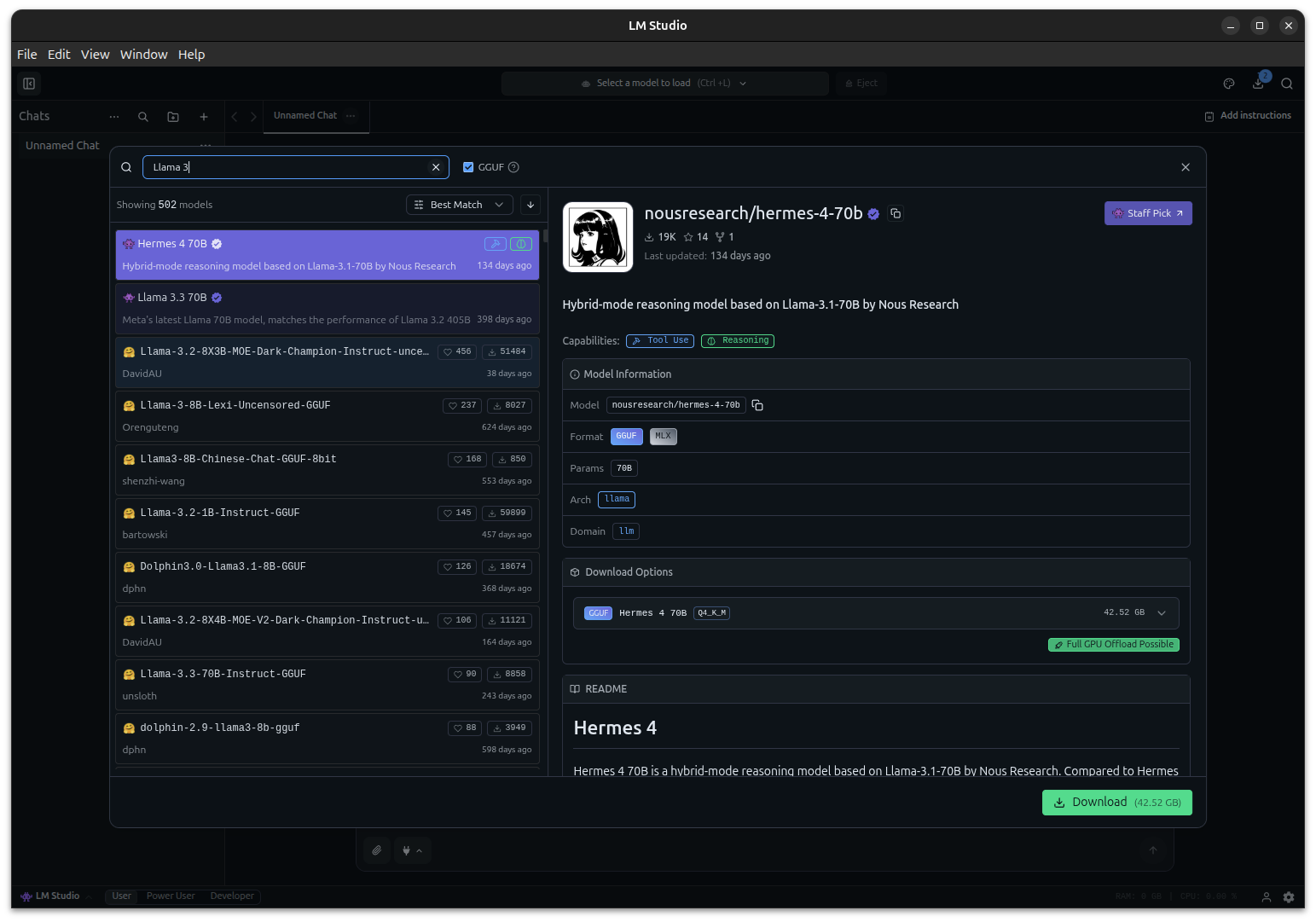
GIGABYTE AI TOP ATOM – LLM Model download
Oder alternativ über die CLI:
Befehl: ./LM_Studio-linux-arm64.AppImage get openai/gpt-oss-20b
Je nach Modellgröße und eurer Internetanbindung kann der Download einige Minuten bis Stunden dauern. Die Modelle werden lokal auf dem AI TOP ATOM gespeichert und müssen nicht bei jedem Start neu heruntergeladen werden.
Empfohlene Modelle für den Einstieg:
-
openai/gpt-oss-20b– Gut ausbalanciertes Modell für allgemeine Aufgaben -
Qwen/Qwen3-Coder– Optimiert für Code-Generierung -
Qwen/Qwen2.5-32B– Sehr leistungsstark, optimiert für Blackwell-GPUs
GIGABYTE AI TOP ATOM – LM-Studio – active download
Nach dem ich dann qwen3-vl-8b herunter geladen hatte konnte ich auch gleich meine Frage an das LLM stellen „Why is the sky blue?“.
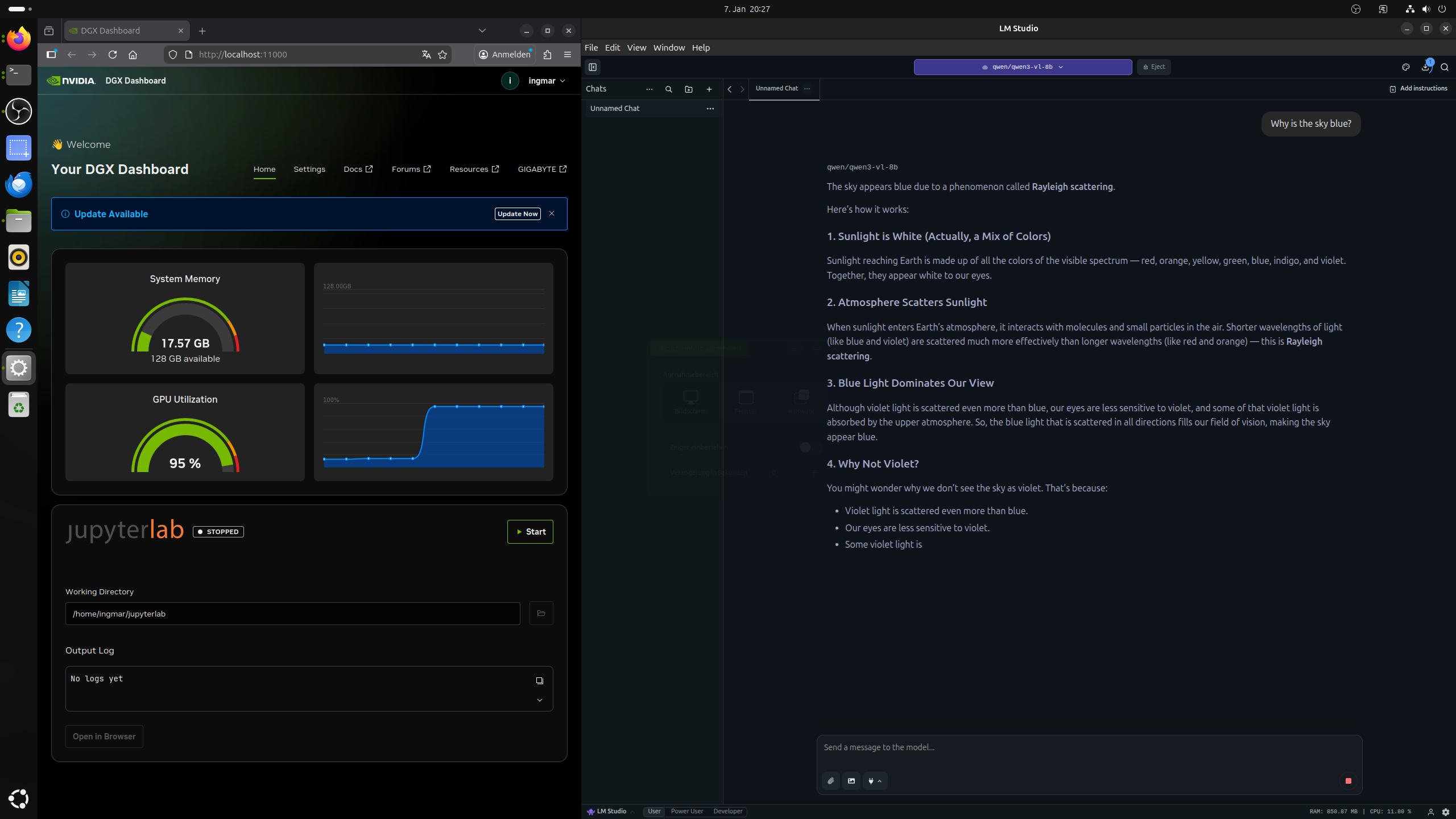
GIGABYTE AI TOP ATOM – LM-Studio
Phase 5: LM-Studio als LLM Server starten (optional)
Jetzt kommt der optionale Schritt bei dem ihr LM-Studio als Server startet: Ich konfiguriere LM Studio so, dass der LLM-Server im gesamten Netzwerk erreichbar ist. Es gibt zwei Möglichkeiten, den Server zu starten:
Option 1: Über die GUI
In der LM Studio GUI öffne ich den Tab „Developer“ und aktiviere in den Server-Einstellungen die Option „Serve on Local Network“. Dies ermöglicht es anderen Geräten im Netzwerk, auf den LLM-Server des AI TOP ATOM zuzugreifen.
In den Server-Einstellungen seht ihr die IP-Adresse und den Port, auf dem der Server läuft. Standardmäßig ist das Port 1234.
Option 2: Über die Kommandozeile
Alternativ könnt ihr den Server auch direkt über die Kommandozeile starten:
Befehl: ./LM_Studio-linux-arm64.AppImage server start
Um einen anderen Port zu verwenden:
Befehl: ./LM_Studio-linux-arm64.AppImage server start --port 1234
Der Server startet jetzt und ist standardmäßig auf allen Netzwerk-Interfaces erreichbar (0.0.0.0).
Wichtiger Hinweis: Falls eine Firewall aktiv ist, müsst ihr Port 1234 freigeben:
Befehl: sudo ufw allow 1234
Phase 6: Netzwerk-Zugriff testen (optional)
Zuerst prüfe ich die IP-Adresse meines AI TOP ATOM im Netzwerk:
Befehl: hostname -I
Ich notiere mir die IP-Adresse (z.B. 192.168.2.100). Jetzt teste ich von einem anderen Computer im Netzwerk, ob der Server erreichbar ist:
Befehl: curl http://<IP-Adresse-AI-TOP-ATOM>:1234/v1/models
Ersetzt dabei <IP-Adresse-AI-TOP-ATOM> mit der IP-Adresse eures AI TOP ATOM. Wenn ihr eine Liste der verfügbaren Modelle zurückbekommt, funktioniert die Netzwerk-Konfiguration korrekt.
Phase 7: API-Zugriff aus dem Netzwerk testen (optional)
Jetzt kann ich von jedem Computer in meinem Netzwerk aus auf die LM Studio API zugreifen. Um zu testen, ob alles funktioniert, führe ich von einem anderen Rechner im Netzwerk folgenden Befehl aus:
curl http://192.168.2.100:1234/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "openai/gpt-oss-20b",
"messages": [{
"role": "user",
"content": "Schreibe mir ein Haiku über GPUs und KI."
}],
"max_tokens": 500
}'Wenn alles korrekt konfiguriert ist, sollte ich eine JSON-Antwort zurückbekommen, die etwa so aussieht:
{
"id": "chatcmpl-...",
"object": "chat.completion",
"created": 1234567890,
"model": "openai/gpt-oss-20b",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "Silizium fließt durch Schaltkreise\nTräume werden Realität\nKI erwacht zum Leben"
},
"finish_reason": "stop"
}]
}Troubleshooting: Häufige Probleme und Lösungen
In meiner Zeit mit LM Studio auf dem AI TOP ATOM bin ich auf einige typische Probleme gestoßen. Hier sind die häufigsten und wie ich sie gelöst habe:
-
AppImage startet nicht: Prüft, ob die Datei ausführbar gemacht wurde mit
chmod +x LM_Studio-linux-arm64.AppImage. Falls die AppImage immer noch nicht startet, prüft, ob FUSE installiert ist:sudo apt install fuse. -
GUI wird nicht angezeigt: Falls ihr über SSH verbunden seid, benötigt ihr X11-Forwarding oder eine Desktop-Umgebung auf dem AI TOP ATOM. Alternativ nutzt die Kommandozeilen-Version des Servers.
-
Server ist nicht im Netzwerk erreichbar: Prüft, ob „Serve on Local Network“ in den Developer-Einstellungen aktiviert ist. Prüft auch die Firewall-Einstellungen und stellt sicher, dass Port 1234 freigegeben ist.
-
Modell-Download schlägt fehl: Prüft die Internetverbindung. Falls ihr Probleme mit dem Download habt, könnt ihr Modelle auch manuell von Hugging Face herunterladen und in das LM Studio Modell-Verzeichnis kopieren.
-
CUDA-Unterstützung nicht verfügbar: LM Studio nutzt CUDA 13. Prüft mit
nvidia-smi, ob die GPU erkannt wird. Falls nicht, installiert die NVIDIA-Treiber. -
Langsame Inferenz: Das Modell könnte zu groß für den verfügbaren GPU-Speicher sein. Probiert ein kleineres Modell oder prüft mit
nvidia-smidie GPU-Auslastung.
LM Studio als Server automatisch starten (optional)
Falls ihr LM Studio als Server automatisch beim Systemstart starten möchtet, könnt ihr einen Systemd-Service erstellen. Zuerst erstelle ich eine Service-Datei:
Befehl: sudo nano /etc/systemd/system/lm-studio.service
Fügt folgenden Inhalt ein (ersetzt dabei /home/benutzername mit eurem tatsächlichen Benutzernamen und dem Pfad zur AppImage):
[Unit]
Description=LM Studio LLM Server
After=network.target
[Service]
Type=simple
User=benutzername
WorkingDirectory=/home/benutzername/lm-studio
ExecStart=/home/benutzername/lm-studio/LM_Studio-linux-arm64.AppImage server start --port 1234
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.targetSpeichert die Datei und aktiviert den Service:
Befehl: sudo systemctl daemon-reload
Befehl: sudo systemctl enable lm-studio
Befehl: sudo systemctl start lm-studio
Der Service startet jetzt automatisch nach jedem Neustart.
Rollback: LM Studio wieder entfernen
Falls ihr LM Studio komplett vom AI TOP ATOM entfernen möchtet, führt auf dem System folgende Befehle aus:
Zuerst stoppt den Server (falls er läuft) mit Ctrl+C oder:
Befehl: sudo systemctl stop lm-studio
Entfernt die AppImage-Datei:
Befehl: rm -rf ~/lm-studio
Falls ihr einen Systemd-Service erstellt habt:
Befehl: sudo systemctl disable lm-studio
Befehl: sudo rm /etc/systemd/system/lm-studio.service
Befehl: sudo systemctl daemon-reload
Wichtiger Hinweis: Diese Befehle entfernen LM Studio, aber nicht die heruntergeladenen Modelle. Die Modelle bleiben im LM Studio Modell-Verzeichnis erhalten, falls ihr sie später wieder verwenden möchtet.
Zusammenfassung & Fazit
Die Installation von LM Studio auf dem Gigabyte AI TOP ATOM ist dank der Kompatibilität mit den NVIDIA DGX Spark Playbooks erstaunlich unkompliziert. In weniger als 15 Minuten habe ich LM Studio eingerichtet und kann jetzt sowohl lokal mit der GUI chatten als auch den LLM-Server im gesamten Netzwerk nutzen.
Was mich besonders begeistert: Die benutzerfreundliche GUI-Oberfläche macht es einfach, Modelle herunterzuladen und direkt zu chatten, ohne komplexe Konfigurationen oder API-Aufrufe. Die OpenAI-kompatible API ermöglicht es, bestehende Anwendungen nahtlos zu integrieren, und die CUDA 13-Unterstützung nutzt die volle Performance der Blackwell-Architektur.
Besonders praktisch finde ich auch, dass LM Studio sowohl als Desktop-Anwendung als auch als Server betrieben werden kann. Die AppImage-Installation ist portabel und einfach zu verwalten – keine komplexen Dependencies oder System-Änderungen nötig.
Für Teams oder alle, die eine intuitive Oberfläche für lokale LLMs suchen, ist das eine perfekte Lösung: Ein zentraler Server mit voller GPU-Power, auf den alle über die OpenAI-kompatible API zugreifen können. Die GUI macht es einfach, Modelle zu verwalten und direkt zu chatten, während die API die Integration in eigene Anwendungen ermöglicht.
Falls ihr Fragen habt oder auf Probleme stoßt, schaut gerne in die offizielle NVIDIA DGX Spark Dokumentation oder in die LM Studio Dokumentation. Die Community ist sehr hilfsbereit, und die meisten Probleme lassen sich schnell lösen.
Nächster Schritt: Modelle ausprobieren und in eigene Anwendungen integrieren
Ihr habt jetzt LM Studio erfolgreich installiert und den Server im Netzwerk exponiert. Die Grundinstallation funktioniert, aber das ist erst der Anfang. Experimentiert mit verschiedenen Modellen und nutzt die OpenAI-kompatible API, um LM Studio in eure eigenen Anwendungen zu integrieren.
Die LM Studio SDKs für Python und JavaScript machen es einfach, den Server in bestehende Projekte einzubinden. Probiert verschiedene Modelle aus und findet heraus, welches am besten zu euren Anforderungen passt.
Viel Erfolg beim Experimentieren mit LM Studio auf eurem Gigabyte AI TOP ATOM. Ich bin gespannt, welche Anwendungen ihr damit entwickelt! Lasst es mich und meine Leser hier in den Kommentaren wissen.



{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…