

Phase 7: Fine-Tuning Training starten
Bevor ich das Training starte, muss ich möglicherweise beim Hugging Face Hub einloggen, falls das Modell gated ist (Zugriffsbeschränkungen hat). Für öffentliche Modelle ist das nicht notwendig:
Befehl: huggingface-cli login
Ihr werdet nach eurem Hugging Face Token gefragt. Diesen findet ihr in euren Hugging Face Account-Einstellungen unter https://huggingface.co/settings/tokens.
Hinweis:
Nach dem ich das hinterlegt hatte und den nachfolgenden Befehl für den Start des Trainings ausgeführt habe kam folgende Fehlermeldung:
Cannot access gated repo for url https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct/resolve/main/config.json.
Access to model meta-llama/Meta-Llama-3-8B-Instruct is restricted and you are not in the authorized list. Visit https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct to ask for access.
Ich bin dann für dieses Beispiel hier auf die folgende Seite gegangen und habe für das Modell Zugriff mit meinem User beantragt und auch direkt erhalten.
URL: https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
Jetzt musste ich mich zunächst einmal etwas in Geduld üben bis ich Zugriff auf das Modell erhalten hatte. Ohne dem Zugriff auf das Modell geht es nicht weiter.
META LLAMA 3 COMMUNITY LICENSE AGREEMENT
Auf der folgenden Seite könnt ihr den Status der Freigabe zu dem Modell für das ihr Zugriff beantragt habt einsehen.
URL: https://huggingface.co/settings/gated-repos
Für das Test-Training ob alles funktioniert werden die folgenden Datensätze als Trainingsdaten geladen:
Datensatz identity.json: https://github.com/hiyouga/LLaMA-Factory/blob/main/data/identity.json
Datensatz alpaca_en_demo.json: https://github.com/hiyouga/LLaMA-Factory/blob/main/data/alpaca_en_demo.json
Jetzt starte ich das Fine-Tuning Training mit der Beispiel-Konfiguration aus dem Repository. Hier geht es jetzt einfach einmal darum ob generell alles funktioniert.
Befehl: llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
Wenn ihr mehr über das Thema Datenaufbereitung für das Training erfahren möchtet dann besucht die folgende Seite.
URL: https://llamafactory.readthedocs.io/en/latest/getting_started/data_preparation.html
Das Training kann je nach Modellgröße und Dataset zwischen 1-7 Stunden dauern. Ihr seht den Fortschritt in Echtzeit, einschließlich der Trainingsmetriken wie Loss-Werte. Die Ausgabe sieht etwa so aus:
***** train metrics *****
epoch = 3.0
total_flos = 22851591GF
train_loss = 0.9113
train_runtime = 0:22:21.99
train_samples_per_second = 2.437
train_steps_per_second = 0.306
Figure saved at: saves/llama3-8b/lora/sft/training_loss.png
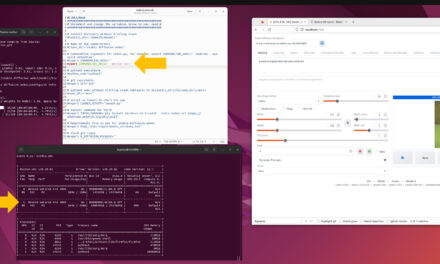
Während des Trainings werden regelmäßig Checkpoints gespeichert, sodass ihr das Training bei Bedarf unterbrechen und später fortsetzen könnt. Bei mir sah das laufende Training im Terminal-Fenster dann wie folgt zusammen mit dem DGX Dashboard dann wie im folgenden Bild gezeigt aus.
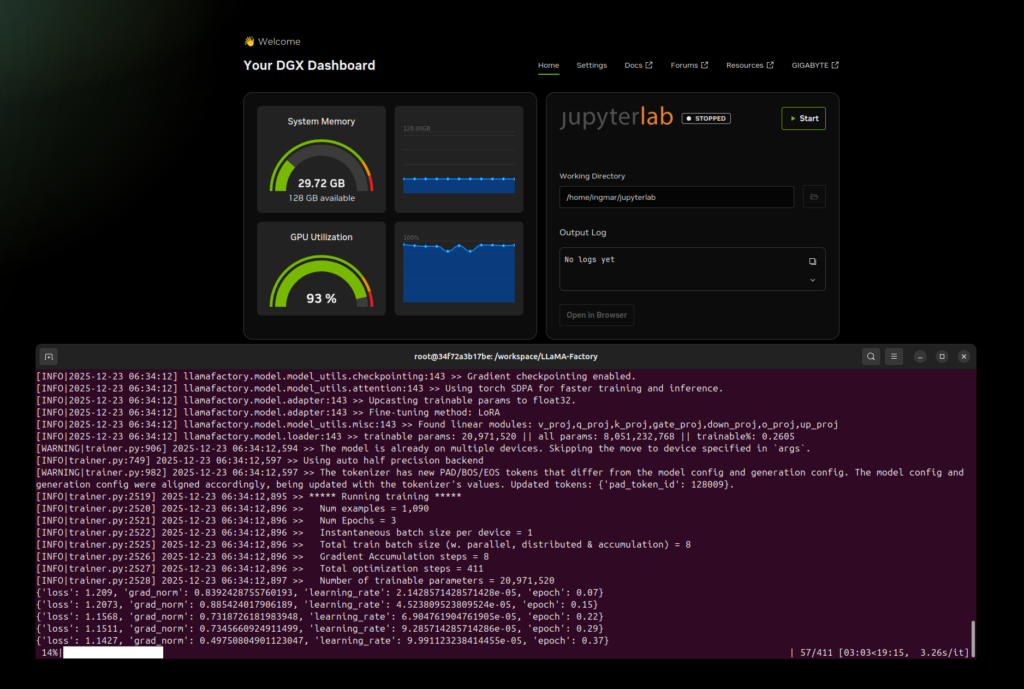
GIGABYTE AI TOP ATOM – LLaMA Factory Docker Container CLI running training
Das Training war nach ca. 40 Minuten erfolgreich beendet. Das ergenis sah dann wie folgt aus:
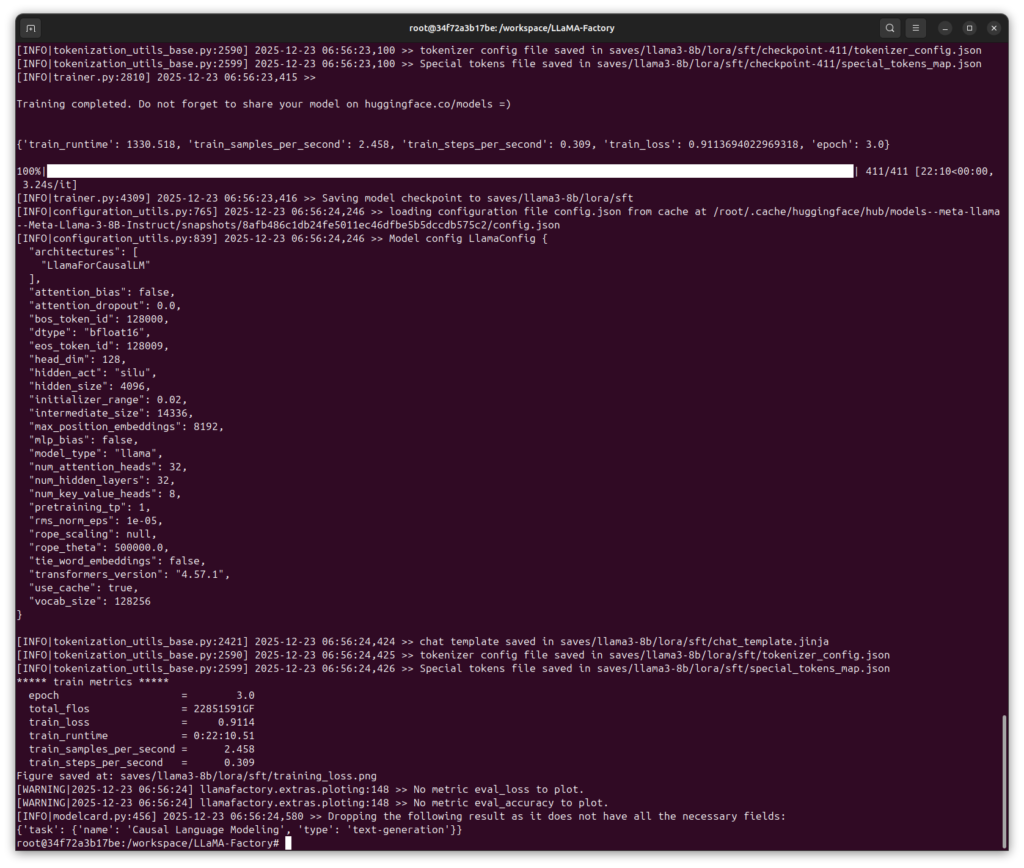
GIGABYTE AI TOP ATOM – LLaMA Factory Docker training completed
Hier in dem nachfolgenden Bild ist gut zu sehen wie das Training mit den Testdaten gelaufen ist.
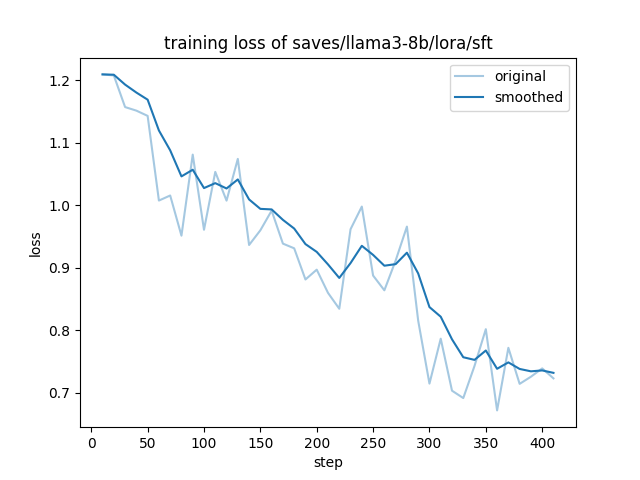
GIGABYTE AI TOP ATOM – LLaMA Factory Docker training loss
Die erzeugten Trainingsdaten findet ihr auf eurem Rechner in dem folgenden Pfad wenn ihr der Anleitung soweit gefolgt seid.
Pfad: /home/<user>/LLaMA-Factory/saves/llama3-8b/lora/sft
Phase 8: Training-Ergebnisse validieren
Nach dem Training prüfe ich, ob alles erfolgreich war und die Checkpoints gespeichert wurden:
Befehl: ls -la saves/llama3-8b/lora/sft/
Ihr solltet sehen:
-
Ein Checkpoint-Verzeichnis (z.B.
checkpoint-21) -
Modell-Konfigurationsdateien (
adapter_config.json) -
Trainingsmetriken mit abnehmenden Loss-Werten
-
Ein Trainings-Loss-Diagramm als PNG-Datei
Die Checkpoints enthalten euer angepasstes Modell und können später für Inference oder Export verwendet werden.
Phase 9: Fine-Tuned Modell testen
Jetzt teste ich das angepasste Modell mit einem eigenen Prompt:
Befehl: llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
Dieser Befehl startet einen interaktiven Chat mit eurem fine-tuned Modell. Ihr könnt jetzt Fragen stellen und seht, wie sich das Modell nach dem Training verhält. Zum Beispiel:
Eingabe: Hello, how can you help me today?
Hier das Ergebnis des kurzen Tests als Bild.
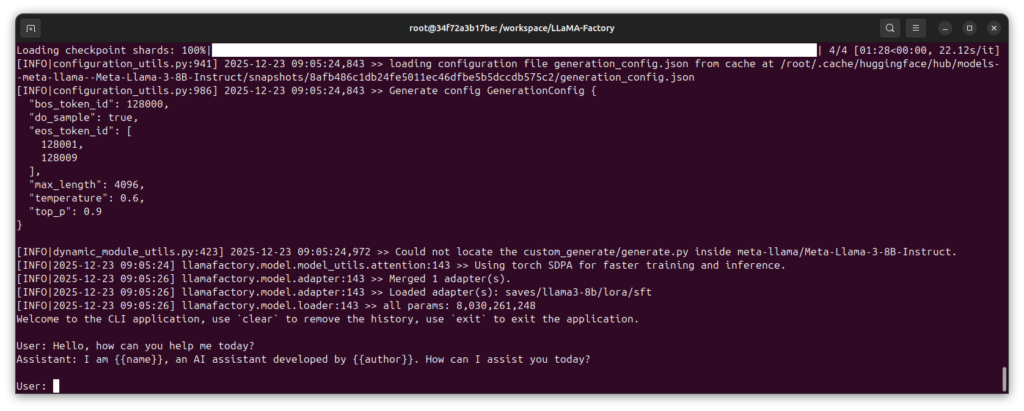
GIGABYTE AI TOP ATOM – LLaMA Factory checkpoint test
Das Modell sollte eine Antwort geben, die das angepasste Verhalten zeigt. Um den Chat zu beenden, drückt Ctrl+C.
Phase 10: LLaMA Factory Web-Interface starten
LLaMA Factory bietet auch ein benutzerfreundliches Web-Interface, das das Training und die Verwaltung von Modellen über den Browser ermöglicht. Um das Web-Interface zu starten:
Befehl: llamafactory-cli webui
Das Web-Interface startet und ist standardmäßig unter http://localhost:7860 erreichbar. Um es auch aus dem Netzwerk erreichbar zu machen, verwendet:
Befehl: llamafactory-cli webui --host 0.0.0.0 --port 7862
Hinweis: Achtet bitte darauf wie der Docker Container gestartet wurde und hier auf den Parameter -p 7862:7860 damit der richtige Port in den Container hinnein umgeleitet wird. In der Ausgabe im Terminal steht zwar noch der Port 7860 aber erreichbar ist LLaMA Factory über den Port 7862.
Jetzt könnt ihr von jedem Computer im Netzwerk auf das Web-Interface zugreifen. Öffnet in eurem Browser http://<IP-Adresse-AI-TOP-ATOM>:7862 (ersetzt dabei <IP-Adresse-AI-TOP-ATOM> mit der IP-Adresse eures AI TOP ATOM).
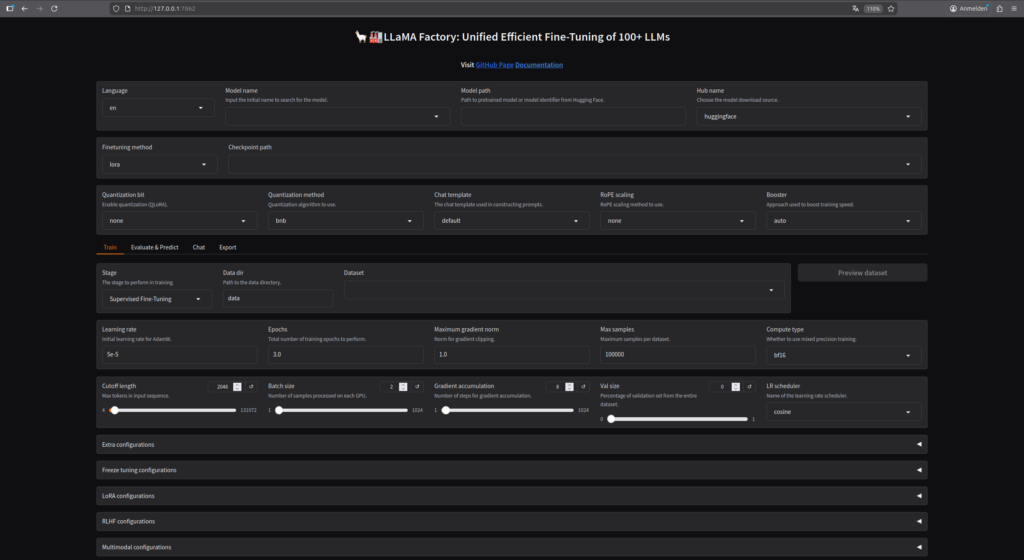
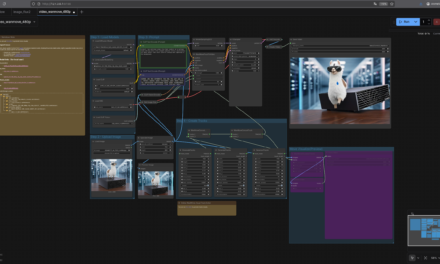
GIGABYTE AI TOP ATOM – LLaMA Factory Web-Interface
Falls eine Firewall aktiv ist, müsst ihr Port 7862 freigeben:
Befehl: sudo ufw allow 7862
Im Web-Interface könnt ihr:
-
Modelle trainieren und fine-tunen
-
Datasets hochladen und verwalten
-
Training-Progress überwachen
-
Modelle testen und exportieren
Phase 11: Automatischen Neustart des Web-UI konfigurieren (Reboot-fest machen)
Um sicherzustellen, dass LLaMA Factory nach einem Systemneustart automatisch und ohne manuelles Eingreifen startet, könnt ihr eine Docker Restart Policy konfigurieren und einen kombinierten Startbefehl verwenden. Dies macht euren AI TOP ATOM zu einem zuverlässigen Server. Zuerst stoppt und entfernt ihr den vorhandenen Container:
Befehl: docker stop llama-factory
Befehl: docker rm llama-factory
Startet den Container nun mit der Richtlinie --restart unless-stopped neu. Wir verwenden außerdem einen Bash-Befehl, um sicherzustellen, dass die LLaMA Factory-Abhängigkeiten registriert werden, bevor die Web-UI startet:
Befehl: docker run --gpus all --ipc=host --ulimit memlock=-1 -d --ulimit stack=67108864 --name llama-factory --restart unless-stopped -p 7862:7860 -v "$PWD":/workspace -w /workspace/LLaMA-Factory nvcr.io/nvidia/pytorch:25.11-py3 bash -c "pip install -e '.[metrics]' && llamafactory-cli webui --host 0.0.0.0 --port 7860"
Der Parameter -d (detached) lässt den Container im Hintergrund laufen. Ihr könnt die Logs jederzeit einsehen, um den Startvorgang oder den Trainingsfortschritt zu überwachen:
Befehl: docker logs -f llama-factory
Mit diesem Setup ist das Web-Interface bei jedem Einschalten eures Gigabyte AI TOP ATOM automatisch unter http://<IP-Adresse>:7862 erreichbar.
Phase 12: Modell für Production exportieren
Für den produktiven Einsatz könnt ihr euer fine-tuned Modell exportieren. Dieses kombiniert das Basis-Modell mit den LoRA-Adaptern zu einem einzigen Modell. Dazu führt ihr den folgenden Befehl im Docker Container aus.:
Befehl: llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
Das exportierte Modell kann dann in anderen Anwendungen wie Ollama oder vLLM verwendet werden. Der Export-Prozess kann einige Minuten dauern, je nach Modellgröße.
Troubleshooting: Häufige Probleme und Lösungen
In meiner Zeit mit LLaMA Factory auf dem AI TOP ATOM bin ich auf einige typische Probleme gestoßen. Hier sind die häufigsten und wie ich sie gelöst habe:
-
CUDA out of memory während des Trainings: Die Batch-Größe ist zu groß für den verfügbaren GPU-Speicher. Reduziert
per_device_train_batch_sizein der Konfigurationsdatei oder erhöhtgradient_accumulation_steps. -
Zugriff auf gated Repository nicht möglich: Bestimmte Hugging Face Modelle haben Zugriffsbeschränkungen. Generiert euren Hugging Face Token neu und beantragt Zugriff auf das gated Modell im Browser.
-
Modell-Download schlägt fehl oder ist langsam: Prüft die Internetverbindung. Falls ihr bereits gecachte Modelle habt, könnt ihr
HF_HUB_OFFLINE=1verwenden. -
Training Loss nimmt nicht ab: Die Learning Rate könnte zu hoch oder zu niedrig sein. Passt den
learning_rateParameter an oder prüft die Qualität eures Datasets. -
Docker Container startet nicht: Prüft, ob Docker korrekt installiert ist und ob
--gpus allunterstützt wird. Bei manchen Systemen muss die Docker-Gruppe konfiguriert werden. -
Speicherprobleme trotz ausreichendem RAM: Bei der DGX Spark Plattform mit Unified Memory Architecture könnt ihr bei Speicherproblemen den Buffer-Cache manuell leeren:
sudo sh -c 'sync; echo 3 > /proc/sys/vm/drop_caches'
Container verlassen und wieder starten
Falls ihr den Container verlassen möchtet (z.B. um Ressourcen freizugeben), könnt ihr einfach exit eingeben. Der Container bleibt erhalten, da wir keinen --rm Parameter verwendet haben. Eure Daten im gemounteten Workspace-Verzeichnis bleiben ebenfalls erhalten.
Um später wieder in den Container zu kommen, gibt es mehrere Möglichkeiten:
-
Container ist gestoppt: Startet ihn mit
docker start -ai llama-factory. Das startet den Container und verbindet euch direkt mit der interaktiven Session. -
Container läuft bereits: Verbindet euch mit
docker exec -it llama-factory bash. Das öffnet eine neue Bash-Session im laufenden Container. -
Nach einem Neustart: Prüft zuerst den Status mit
docker ps -a | grep llama-factory. Falls der Container gestoppt ist, startet ihn mitdocker start -ai llama-factory.
Um den Status aller Container zu prüfen:
Befehl: docker ps -a
Um den Container zu stoppen (ohne ihn zu löschen):
Befehl: docker stop llama-factory
Um den Container komplett zu entfernen (alle Daten im Container gehen verloren, aber nicht im gemounteten Workspace):
Befehl: docker rm llama-factory
Falls ihr den Container nach dem Entfernen neu erstellen möchtet, verwendet einfach den Befehl aus Phase 2 erneut.
Rollback: LLaMA Factory wieder entfernen
Falls ihr LLaMA Factory komplett vom AI TOP ATOM entfernen möchtet, führt auf dem System folgende Befehle aus:
Zuerst verlasst ihr den Container (falls ihr noch drin seid):
Befehl: exit
Stoppt den Container (falls er noch läuft):
Befehl: docker stop llama-factory
Entfernt den Container:
Befehl: docker rm llama-factory
Dann entfernt ihr das Workspace-Verzeichnis:
Befehl: rm -rf ~/llama-factory-workspace
Um auch nicht verwendete Docker-Container und Images zu entfernen:
Befehl: docker system prune -f
Um nur Container zu entfernen (Images bleiben erhalten):
Befehl: docker container prune -f
Wichtiger Hinweis: Diese Befehle entfernen alle Trainingsdaten, Checkpoints und Modelle. Stellt sicher, dass ihr wirklich alles entfernen möchtet, bevor ihr diese Befehle ausführt. Die Checkpoints enthalten euer angepasstes Modell und können nicht einfach wiederhergestellt werden.
Zusammenfassung & Fazit
Die Installation von LLaMA Factory auf dem Gigabyte AI TOP ATOM ist dank der Kompatibilität mit den NVIDIA DGX Spark Playbooks erstaunlich unkompliziert. In etwa 30-60 Minuten habe ich LLaMA Factory eingerichtet und kann jetzt eigene Sprachmodelle für spezielle Aufgaben anpassen.
Was mich besonders begeistert: Die Performance der Blackwell-GPU wird voll ausgenutzt, und die Docker-basierte Installation macht das Setup deutlich einfacher als eine manuelle Installation. LLaMA Factory bietet eine einheitliche Oberfläche für verschiedene Fine-Tuning-Methoden, sodass ihr schnell zwischen LoRA, QLoRA und Full Fine-Tuning wechseln könnt.
Besonders praktisch finde ich auch, dass die Trainings-Checkpoints automatisch gespeichert werden. Das ermöglicht es, das Training bei Bedarf zu unterbrechen und später fortzusetzen. Die Trainingsmetriken werden ebenfalls gespeichert, sodass ihr den Fortschritt genau verfolgen könnt.
Für Teams oder Entwickler, die ihre eigenen Sprachmodelle anpassen möchten, ist das eine perfekte Lösung: Ein zentraler Server mit voller GPU-Power, auf dem ihr Modelle für spezielle Domänen trainieren könnt. Die exportierten Modelle können dann in anderen Anwendungen wie Ollama oder vLLM verwendet werden.
Falls ihr Fragen habt oder auf Probleme stoßt, schaut gerne in die offizielle NVIDIA DGX Spark Dokumentation, die LLaMA Factory Dokumentation oder in die LLaMA Factory ReadTheDocs. Die Community ist sehr hilfsbereit, und die meisten Probleme lassen sich schnell lösen.
Nächster Schritt: Eigene Datasets vorbereiten und Modelle anpassen
Ihr habt jetzt LLaMA Factory erfolgreich installiert und ein erstes Training durchgeführt. Die Grundinstallation funktioniert, aber das ist erst der Anfang. Der nächste Schritt ist die Vorbereitung eurer eigenen Datasets für spezielle Anwendungsfälle.
LLaMA Factory unterstützt verschiedene Dataset-Formate, einschließlich JSON-Dateien für Instruction Tuning. Ihr könnt eure Modelle für Code-Generierung, medizinische Anwendungen, Unternehmenswissen oder andere spezielle Domänen anpassen. Die Dokumentation zeigt euch, wie ihr eure Daten im richtigen Format vorbereitet.
Viel Erfolg beim Experimentieren mit LLaMA Factory auf eurem Gigabyte AI TOP ATOM. Ich bin gespannt, welche angepassten Modelle ihr damit entwickelt! Lasst es mich und meine Leser hier in den Kommentaren wissen.

{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…