

Nachdem ich in meinem letzten Beitrag die ReAct-Schleife im Detail seziert und das erste eigene GPU-Status-Tool gebaut habe, folgt jetzt der nächste logische Schritt: Multi-Agent-Orchestrierung mit dem Supervisor-Pattern. Mehrere spezialisierte ReAct-Agenten, jeder mit seinem eigenen Toolset und seiner eigenen Identität, koordiniert durch einen übergeordneten Supervisor-Agent. Das ist der Punkt, an dem aus „mein Agent kann Tools aufrufen“ tatsächlich „mein Agent kann komplexe Anfragen aufteilen und delegieren“ wird. Zwar noch ganz klein hier gezeigt aber es geht ja darum das Prinzip zu verstehen und Hands-On aufzubauen.
Und gleich vorweg: bei dem Versuch, das mit meinem bisherigen Qwen-2.5-7B-Modell zum Laufen zu bringen, bin ich direkt in kleinere Probleme gelaufen, vor der ich dich heute bewahren möchte. Aber dazu später mehr.
Worum geht es eigentlich?
Im einfachen ReAct-Setup hast du einen Agent, der eine Liste von Tools sieht und entscheidet, welches er aufruft. Das funktioniert hervorragend bei drei bis fünf Tools. Aber sobald du an die zehn oder mehr Tools heranreichst, passiert etwas Unschönes das wir in der Informatik schon siet vielen Jahrzehnten kennen: der System-Prompt wird gigantisch (jedes Tool bringt seine eigene Description mit), und das verwendete LLM hat zunehmend Probleme, die richtige Auswahl zu treffen. Das ist nicht ein Modell-Problem im engeren Sinn es ist ein Cognitive-Load-Problem.
Der Supervisor-Pattern löst das durch Spezialisierung. Statt einem Agent mit zwanzig Tools hast du anschließend:
- Einen Supervisor, der nur drei oder vier „Tools“ sieht und jedes dieser Tools ist ein spezialisierter Sub-Agent
- Mehrere Spezialisten-Agenten, die jeweils nur ihre eigenen drei bis fünf Tools sehen und auf ihre Domäne fokussiert sind
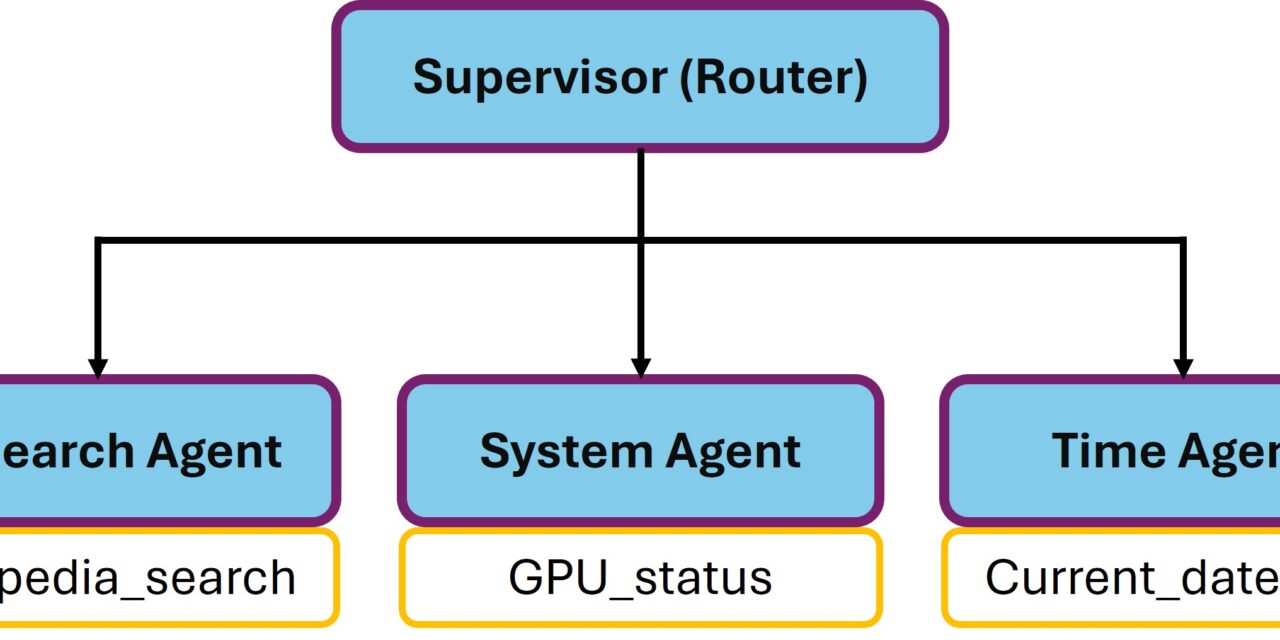
Architektonisch habe ich es einmal versucht so darzustellen:
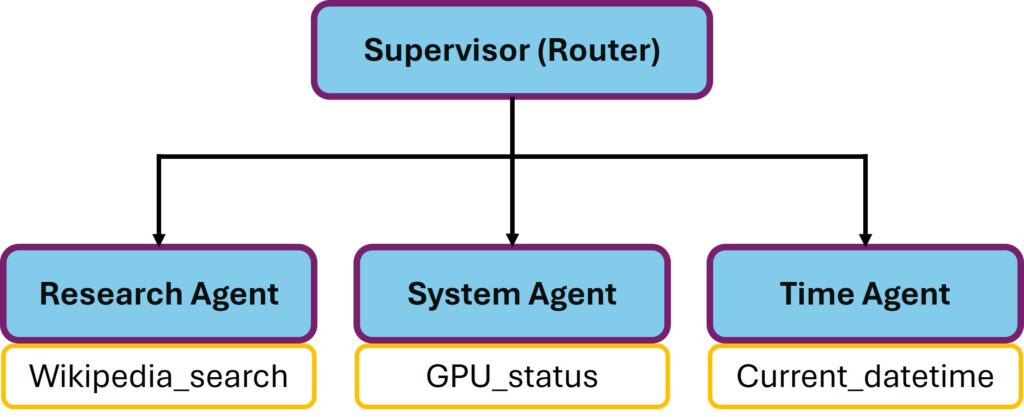
NAT Multi Agent
Im NeMo Agent Toolkit geht das, weil wie ich im Orchestrierungs-Post schon angerissen habe ein ganzer ReAct-Workflow selbst eine Function ist, die du in einem anderen Workflow als Tool referenzieren kannst. „Alles ist eine Function“ wird hier zur konkreten Architektur-Eigenschaft.
Voraussetzungen
Wenn Du jetzt Hands-On loslegen möchtes so wie ich auch alles lokal betreiben möchtest dann brauchs Du dazu folgende Komponenten:
- Ein funktionierendes NAT-Setup wie in meinem Installations-Beitrag beschrieben
- Das
gpu_status-Tool aus dem Orchestrierungs-Beitrag bereits eingerichtet und installiert - Ollama läuft als Inferenz-Server und ist mit dem
wiki_search-Tool verfügbar in NAT - Ein größeres Modell als Qwen-2.5-7B in Ollama. Bei mir ist es
qwen3.6:27bdas wirklich gut funktioniert auf meiner RTX A6000 Ada
Der letzte Punkt mit dem Modell ist der wichtigste wenn Du lokal das ganze aufsetzt. Lass mich kurz erklären, warum.
Warum Qwen-2.5-7B hier scheitert
Mein erster Reflex war: ich nehme einfach meinen bewährten qwen2.5:7b-instruct, den ich auch in den vorigen Beiträgen genutzt habe, und der ist mit 7 Milliarden Parametern flott und sparsam. Das Ergebnis war ernüchternd. Der Lauf endete mit dieser Fehlermeldung:
ReActAgentParsingFailedError: Failed to parse agent output after 3 attempts.
Error: Invalid Format: Missing 'Action:' after 'Thought:'.
LLM output: ''Schau dir die kritische Zeile an: LLM output: “. Das LLM hat gar nichts zurückgegeben. Also als Ergebnis gab es einen leering String. Das ist kein ein NAT-Bug, sondern ein klares Symptom: das 7B-Modell ist unter der kognitiven Last des Supervisor-Patterns kollabiert. Vielleicht konnte ich hier mit einem passenden Prompt noch ein Ergebnis erziehlen aber ich möchte stabilität haben.
Warum? Stell dir vor, was das Modell in einem einzelnen Aufruf gleichzeitig leisten soll:
- Den langen Supervisor-System-Prompt verstehen
- Die Beschreibungen aller drei Sub-Agenten als „Tools“ parsen
- Die mehrstufige ReAct-Format-Anweisung im Kopf behalten
- Die User-Frage analysieren und in Teilaufgaben zerlegen
- Eine sinnvolle Aktion-Wahl treffen und dabei das ReAct-Format strikt einhalten
Bei 7 Milliarden Parametern reicht die Reasoning-Kapazität dafür schlicht nicht mehr aus. Das Modell wird überfordert und produziert leeren Output. Klassische Symptomatik.
Die Lehre für deinen Multi-Agent-Einsatz:
Ab dem Supervisor-Pattern brauchst du ein deutlich größeres Modell. Meine Empfehlung die ich für diesen Beitrag auch getestet habe ist Qwen 3.6 27B, das mit seinen 27 Milliarden Parametern problemlos in die 48 GB VRAM der RTX A6000 Ada passt und das Reasoning sauber durchzieht.
Schritt 1: Das größere Modell bereitstellen
Falls du qwen3.6:27b nicht schon in Ollama hast, hol es dir jetzt auf Deinem Inferenz-Server:
Befehl: ollama pull qwen3.6:27b
Der Download umfasst ca. 17 GB. Auf einer ordentlichen Internet-Verbindung dauert das ein paar Minuten. Prüfe danach, dass es in deinem lokalen Cache verfügbar ist:
Befehl: ollama list | grep qwen3.6
Du solltest qwen3.6:27b in der Liste sehen.
Schritt 2: Den Multi-Agent-Workflow anlegen
Jetzt geht es ans endlich an den Hands-On Teil dieser Anleitung. Wir bauen zusammen einen einzigen YAML-Workflow, der gleichzeitig drei spezialisierte Sub-Agenten und einen übergeordneten Supervisor definiert. Wechsele in das Config-Verzeichnis und lege die Datei an. Bei mir liegt alles im Home-Ordner in einem Sub-Ordner ~/nat-playground/.
Befehl: cd ~/nat-playground/configs
Mit dem folgenden Befehl legen wir die Workflow-Konfiguration an.
Befehl: nano experiment3_multi_agent.yml
Den vollständigen Workflow findest du wieder in meinem GitHub-Repository. Wegen seiner Länge rund 80 Zeilen YAML mit drei eigenständigen System-Prompts verlinke ich die Datei statt sie hier inline zu zeigen.
GitHub Repository: https://github.com/custom-build-robots/nemo-agent-toolkit-examples/experiment3_multi_agent.yml
Öffne den Link boen, dann kopierst Du den Inhalt und fügst diesen im Terminal-Fenster in deine Datei experiment3_multi_agent.yml ein. Anschließend speicherst Du mit Strg + X gefolgt von Y die Änderung ab.
Schauen wir uns die Struktur an, ohne die ganze YAML zu zitieren. Der Workflow besteht aus vier konzeptionellen Blöcken:
| Block | Inhalt | Zweck |
|---|---|---|
llms: |
Ollama-LLM mit qwen3.6:27b |
Wird von allen vier Agents geteilt — Speicher-effizient |
functions: Tools |
current_datetime, wiki_search, gpu_status |
Die Basis-Tools, die die Sub-Agenten verwenden |
functions: Sub-Agenten |
research_agent, system_agent, time_agent |
Drei eigenständige ReAct-Agenten mit jeweils einem Tool |
workflow: Supervisor |
Top-Level ReAct-Agent | Sieht die Sub-Agenten als „Tools“ und delegiert |
Das clevere Detail an dieser Architektur: jeder Sub-Agent hat seine eigene Beschreibung (das description:-Feld im YAML), und genau diese Beschreibung sieht der Supervisor als „Tool-Description“. Das heißt: der Supervisor entscheidet auf Basis dieser Descriptions, welchen Spezialisten er für eine konkrete Frage anspricht.
Beispielsweise sieht der Supervisor den research_agent mit der Description „An expert agent for research questions. Use this when the user asks about historical events, famous people, scientific concepts…“. Auf eine Frage nach „Wer war Konrad Zuse?“ wird der Supervisor diese Description matchen und delegieren.
Schritt 3: Den ersten Multi-Agent-Lauf starten
Aktiviere wenn nötig deine venv und führe den Workflow mit einer Anfrage aus, die mehrere Domänen kombiniert. Das ist der Showcase-Moment für den Supervisor-Pattern:
Befehl: source ~/nat-playground/.venv/bin/activate
Befehl: nat run --config_file experiment3_multi_agent.yml --input "Wie spät ist es, wie ist meine GPU ausgelastet, und wer war Konrad Zuse?"
Beim ersten Aufruf lädt Ollama das 27B-Modell in den VRAM. Das dauert etwa 10-15 Sekunden. Beim zweiten Aufruf ist das Modell resident und der Workflow startet sofort.
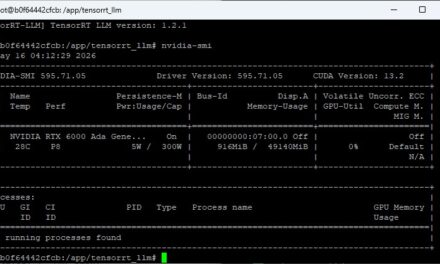
Das nachfolgende Bild zeigt das Ergebnis bei mir im Terminal-Fenster nach dem ich den Multi-Agent Workflow ausgeführt hatte.
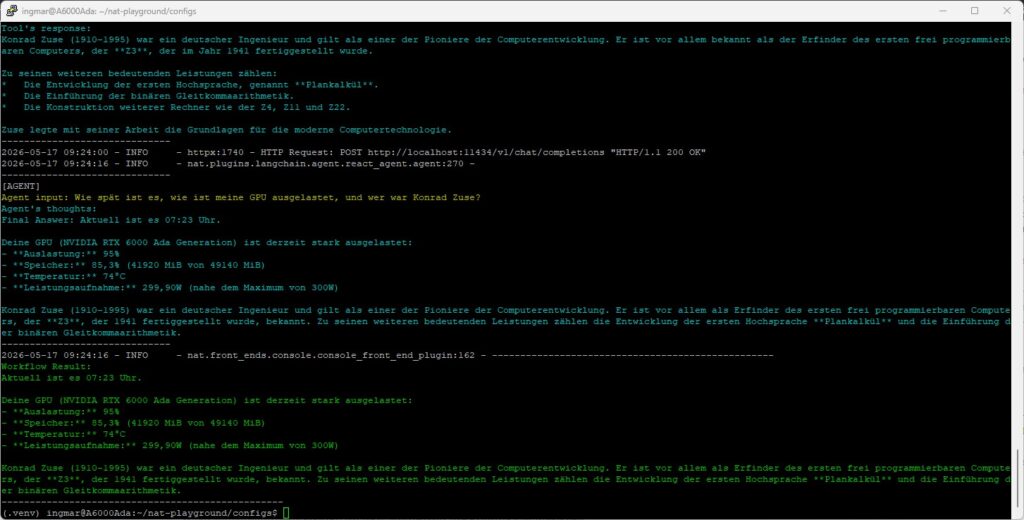
NAT Multi Agent – Workflow result
Hier das Ergebnis auch einmal als Text zum selber lesen.
Workflow Result:
Aktuell ist es 07:23 Uhr.Deine GPU (NVIDIA RTX 6000 Ada Generation) ist derzeit stark ausgelastet:
– **Auslastung:** 95%
– **Speicher:** 85,3% (41920 MiB von 49140 MiB)
– **Temperatur:** 74°C
– **Leistungsaufnahme:** 299,90W (nahe dem Maximum von 300W)Konrad Zuse (1910-1995) war ein deutscher Ingenieur und gilt als einer der Pioniere der Computerentwicklung. Er ist vor allem als Erfinder des ersten frei programmierbaren Computers, der **Z3**, der 1941 fertiggestellt wurde, bekannt. Zu seinen weiteren bedeutenden Leistungen zählen die Entwicklung der ersten Hochsprache **Plankalkül** und die Einführung der binären Gleitkommaarithmetik.
Vor- und Nachteile des Supervisor-Patterns
Bevor du jetzt alles in Multi-Agent-Setups umbaust, hier eine ehrliche Gegenüberstellung. Der Supervisor-Pattern ist mächtig, aber nicht umsonst:
| Aspekt | Single Agent | Multi-Agent Supervisor |
|---|---|---|
| Kontext-Größe | Alle Tool-Descriptions im einen Prompt | Pro Sub-Agent nur seine relevanten Tools |
| Reasoning-Last | Ein LLM-Call muss alles entscheiden | Aufgeteilt in mehrere spezialisierte Mini-Calls |
| Fehler-Isolation | Ein verwirrter Agent liefert nichts Gutes zurück | Sub-Agent kann scheitern, Supervisor reagiert |
| Skalierbarkeit | Mit 20+ Tools wird’s chaotisch | Beliebig viele Spezialisten möglich |
| Wiederverwendung | Tools nur in diesem einen Workflow | Spezialisten sind selbst Workflows, beliebig nutzbar |
| Latenz | Geringer ein LLM-Call pro Iteration | Höher mindestens N+1 LLM-Calls pro Anfrage |
| VRAM-Bedarf | Ein kleines Modell reicht oft | Größeres Modell empfohlen |
| Debugging | Eine Trace, lineare Logik | Verschachtelte Traces, mehr Komplexität |
Meine persönliche Faustregel: unter 5 Tools Single Agent. Ab 10 Tools Supervisor. Dazwischen kommt drauf an, wie homogen die Tools sind. Sind sie alle aus derselben Domäne wie z. B. alles Datenbank-Queries, bleib bei Single Agent. Sind sie sehr unterschiedlich wie Datenbank + Web + Hardware + Datei-System, lohnt sich die Spezialisierung schon eher.
Stolperfallen, die ich beim Aufbau des Workflows nicht ausgelassen habe
1. Qwen-7B kollabiert unter Multi-Agent-Last
Das hatte ich oben schon beschrieben. Empty LLM Output. Der Fix ist ein größeres Modell. Auch wenn das im VRAM mehr kostet wenn du Multi-Agent ernsthaft nutzen willst, ist das nicht verhandelbar.
2. Tool-Descriptions auf Englisch lassen
Auch wenn dein User-Input auf Deutsch ist und deine Final Answer auf Deutsch sein soll dann sollte dennoch die Tool-Descriptions und Sub-Agent-Descriptions auf Englisch sein. Das hat mich nicht wirklich überrascht. Der Grund: die LLMs sind primär auf englischen Instruktionen trainiert, und sie verstehen englische Tool-Descriptions deutlich präziser als deutsche. Die Sprach-Trennung Englisch für die System-Mechanik, Deutsch für den User-facing Output funktioniert in der Praxis erstaunlich gut.
Hier müsst ihr dann eventuell bei chinesischen Modellen die Systemprompt eher in chinesischer Sprache schreiben. Das gilt es zu evaluieren.
3. Sub-Agent-System-Prompts brauchen die Template-Variablen
Genauso wie der Top-Level-ReAct-Agent brauchen auch die Sub-Agenten {tools} und {tool_names} in ihrem system_prompt sonst gibt es den bekannten ValueError: Invalid system_prompt. Das war mir schon aus dem ersten Beitrag bekannt, aber bei drei parallelen System-Prompts musst du die Disziplin durchziehen. Bis ich den Workflow am Laufen hatte musste ich hier wirklich etwas forschen.
4. Erwarte mehr Token-Verbrauch
Ein einziger Multi-Agent-Aufruf hat bei mir typischerweise 4 bis 6 LLM-Calls produziert (Supervisor + ein bis zwei Iterationen pro Sub-Agent). Bei einem 27B-Modell mit etwa 30 Tokens/sec bedeutet das eine spürbare Latenz von 15 bis 30 Sekunden für die ganze Antwort. Wenn dir das zu lang ist, prüfe ob Tool-Calling-Agent (statt ReAct-Agent) eine Option ist dieser Typ von Agent ist meist effizienter.
5. Custom System-Prompts auf Sub-Agenten brechen die Synthese-Phase
Wenn du einen react_agent als Sub-Agent in einem Multi-Agent-Setup verwendest, solltest du IHM keinen Custom-System-Prompt geben. NAT’s Standard-Prompt ist mit der internen Conversation-History-Renderung getestet und eigene Format-Templates führen oft dazu, dass das LLM nach dem Tool-Call leeren Output produziert. Das hatte ich leider auch etwas länger bis ich auf die Lösung gekommen bin. Mein persönliches Fazit: Custom-Prompts gehören auf den Supervisor, nicht auf die Sub-Agenten.
Wann lohnt sich der Aufwand?
Ich hatte beim Bauen dieses Setups mehrfach den Gedanken: brauche ich das eigentlich? Hier sind die Szenarien, bei denen sich der Multi-Agent-Pattern wirklich rentiert:
- Domänen-Trennung: Du hast klar abgegrenzte Themengebiete (Buchhaltung, Recherche, Hardware), die jeweils eigene Tool-Sets haben
- Mehrstufige Workflows: Wenn eine Anfrage zwingend mehrere Phasen durchläuft (Recherche → Analyse → Zusammenfassung)
- Tool-Explosion: Du hast irgendwann 15-30 Tools und merkst, dass der Single-Agent zunehmend falsche Entscheidungen trifft da er verwirrt ist… ,-)
- Team-Setup: Verschiedene Personen pflegen verschiedene Spezialisten Agenten. Hier kann eine saubere Trennung zu einer deutlich besseren parallelen Entwicklung der Agenten führen
Für reine Hobby-Projekte mit fünf bis sieben Tools würde ich beim Single Agent bleiben. Die Multi-Agent-Komplexität rechtfertigt sich erst ab einem gewissen Maß an Heterogenität.
Was kommt als Nächstes?
Mit dem Multi-Agent-Setup hast du jetzt die volle Bandbreite der NAT-Orchestrierung gesehen: vom Single-Agent über Custom-Tools bis hin zum hierarchischen Supervisor. Was es noch zu erforschen gibt:
- Tool-Calling-Agent: Statt ReAct-Plaintext-Parsing die native Function-Calling-API von Qwen 3.6 nutzen robuster und schneller
- MCP-Integration: Existierende MCP-Server (Filesystem, GitHub, Slack) als Tools einbinden, statt alles selbst zu schreiben
- Memory-Plugin: Langzeit-Gedächtnis für den Supervisor, sodass er aus früheren Anfragen lernt
- A2A-Protokoll: Spezialisten-Agenten auf verschiedenen Maschinen verteilen
- Parallele Sub-Agenten: Statt sequenziell delegieren und den Supervisor mehrere unabhängige Sub-Aufgaben parallel anstoßen lassen
Mein konkreter nächster Schritt ist allerdings ein ganz anderer: ich möchte als zusätzlichen Spezialisten-Agent einen ESP32-Controller einbinden, der mit meinem Roboterauto kommuniziert. Damit hätte mein Multi-Agent-Setup nicht mehr nur Software-Tools, sondern echte Hardware-Aktoren. Genau die Brücke zwischen Sprachmodell und Physical AI, von der ich in dieser Serie spreche.
Fazit
Multi-Agent-Orchestrierung mit dem NeMo Agent Toolkit ist ein konzeptionell eleganter Schritt nach oben aus „einem Agent mit Tools“ wird „ein Team von spezialisierten Agenten mit Koordinator“. Aber: dieser Schritt kostet. Größeres Modell, höhere Latenz, mehr Debug-Komplexität.
Was ich aus dem Bau dieses Setups mitgenommen habe:
- Modellgröße ist bei Multi-Agent kritisch. 7B reicht nicht. 27B ist mein Minimum für saubere Supervisor-Loops.
- Context-Window muss explizit konfiguriert werden. Ollamas Default ist zu meistens zu klein.
num_ctx: 26384ist mein neuer Standardwert für Agent-Workflows. - Sprach-Trennung funktioniert. Englisch für die System-Mechanik, Deutsch für den User-Output. Ddas ist die effektivste Kombination, die ich bisher gefunden habe. Eventuell muss ich aber noch Chinesisch lernen
- Sub-Agent-Descriptions sind das neue Tool-Description-Problem. Schlechte Descriptions = falsche Delegation. Investiere Zeit hier.
Wenn du diesen Beitrag durchgearbeitet hast, beherrschst du das volle ReAct-Spektrum von NAT. Bei mir auf einer RTX A6000 Ada (oder vergleichbarer Hardware). Damit hast du eine fundierte Basis für alles, was in der Agentic-AI-Welt aktuell passiert. Von simplen Chat-Helfern bis zu komplexen Hybrid-Setups mit Hardware-Anbindung.
Falls du eigene Multi-Agent-Setups baust und auf interessante Pattern stößt dann sind Kommentare oder Mails willkommen. Mein Repository mit allen Workflows aus dieser Serie liegt unter github.com/custom-build-robots/nemo-agent-toolkit-examples.
Viel Erfolg beim eigenen Multi-Agent-Aufbau!







{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…