


NVIDIA hat mit TensorRT Edge-LLM ein C++-only Inferenz-Framework für Embedded-Plattformen veröffentlicht. Diese ist für den Jetson Thor, DRIVE Thor oder auch der MediaTek CX1 Plattform gedacht. Genau auf solchen Plattformen wird in den nächsten Jahren der spannende Teil von Edge-AI passieren: Sprachmodelle, Vision-Language-Modelle und Vision-Language-Aktion-Modelle, die ohne Cloud-Anbindung auf lokaler, sparsamer Hardware laufen. Für jeden, der das Thema Edge Physical AI als auch Souveräne KI ernst nimmt, ist das die nächste logische Stufe nach lokalen Inferenz-Servern mit klassischer GPU.
NVIDIA hat mit TensorRT Edge-LLM ein C++-only Inferenz-Framework für Embedded-Plattformen veröffentlicht. Primär gedacht für die NVIDIA-eigenen Plattformen Jetson Thor und DRIVE AGX Thor diese wird aber bereits von Partnern adaptiert, darunter MediaTek für ihren CX1 SoC, Bosch für den AI-powered Cockpit und ThunderSoft für die AIBOX-Plattform. Genau auf solchen Plattformen wird in den nächsten Jahren der spannende Teil von Edge-AI passieren: Sprachmodelle, Vision-Language-Modelle und Vision-Language-Action-Modelle, die ohne Cloud-Anbindung auf lokaler, sparsamer Hardware laufen. Für jeden, der das Thema Edge Physical AI als auch Souveräne KI ernst nimmt, ist das die nächste logische Stufe nach lokalen Inferenz-Servern mit klassischer GPU.
Das Problem: Ich habe weder einen Jetson Thor noch einen DRIVE Thor. Beide sind teuer, nicht so einfach zu bekommen, und außerhalb der Reichweite eines normalen Heim-Setups. Was ich habe, ist ein NVIDIA RTX A6000 Ada (SM89) in einem Ubuntu-Server. Dort läuft Edge-LLM offiziell nicht denn diskrete GPUs sind in der Support-Matrix als „nicht offiziell, experimentell“ geführt.
Ich habe nur ein paar Jetson Nano der ersten Geneartion mit 4GB RAM aus meinen Roboter-Auto Projekten aus den Jahren 2020 bis 2021.

Donkey Car – Jetson Nano
Statt zu warten, bis sich die Hardware-Frage löst, habe ich beschlossen, das konzeptionell verwandte große Geschwisterprojekt durchzuarbeiten: TensorRT-LLM. Es teilt sich mit Edge-LLM die Architektur fast vollständig, läuft aber auf Datacenter-GPUs und damit auch auf einer professionellen Workstation-Karte wie meiner Ada. So baue ich mir die Skills auf, die später 1:1 auf Jetson Thor übertragbar sind, sobald die Hardware in Reichweite in meiner Hobby-Umgebung verfügbar ist.
Dieser Blog-Post ist Teil 1 einer vierteiligen Serie, in der ich den kompletten Weg dokumentiere: Motivation, Installation, Build-Pipeline mit verschiedenen Quantisierungen, und am Ende die echten Messwerte mit allen Stolpersteinen, die mir unterwegs begegnet sind.
Auf das Thema aufmerksam geworden bin ich über diesen Beitrag von NVIDIA: Accelerating LLM and VLM Inference for Automotive and Robotics with NVIDIA TensorRT Edge-LLM
Warum Edge-LLM überhaupt?
Lokale KI-Inferenz ist heute in einem Zwischenzustand. Tools wie Ollama oder llama.cpp machen es trivial, ein quantisiertes 7B-Modell auf einer mittelklassigen GPU oder sogar CPU laufen zu lassen. Das funktioniert gut für einen Entwickler-Workflow am Schreibtisch . Aber sobald Inferenz deployt werden soll in ein Gerät am Produktionsband, eine Maschine in der Landwirtschaft, einem klassischen Roboter, ein Auto, gelten andere Regeln:
- Power-Budget: 50 Watt statt 300+ Watt
- Thermal: Kompakt geschlossen Lüfterlos oder zumindest sehr leise
- Latenz: Vorhersagbar, nicht „gut im Mittel“
- Statisches Workload: Ein Modell, ein Anwendungsfall, kein dynamisches Hot-Swapping der Modelle
- Kein Update-Zyklus: Was deployt wird, läuft für längere Zeit (stabil)
llama.cpp und Ollama sind für diese Bedinungen und Auflagen nicht gebaut. Sie arbeiten interpretierend: Die GGUF-Datei wird zur Laufzeit gelesen und Layer für Layer mit generischen CUDA-Kernels ausgeführt. Es ist vorab keine modell-spezifische Vorab-Kompilierung auf die vorhandene Hardware erfolgt. Das ist flexibel und portabel, lässt aber Performance liegen.
TensorRT Edge-LLM macht genau das anders: Aus einem sagen wir allgemeinem HuggingFace-Checkpoint wird über einen Python-Export-Schritt ein ONNX-Graph, daraus baut der C++-Engine-Builder eine hardware-spezifische TensorRT-Engine, die nur auf einer bestimmten GPU-Architektur wie diese z. B. im Jetson Thor verbaut ist läuft. Dafür arbeitet dieses so erzeugte Modell dann aber mit maximaler Effizienz auf dieser Hardware. Die Engine ist eine binäre Datei, die zur Laufzeit nur noch geladen werden muss. Kein Python, keine PyTorch-Abhängigkeit, keine Interpretation. Genau das, was man für ein Produktivgerät will.
Die Pipeline, die Edge-LLM verwendet
Im Edge-LLM-Diagramm sieht das so aus:
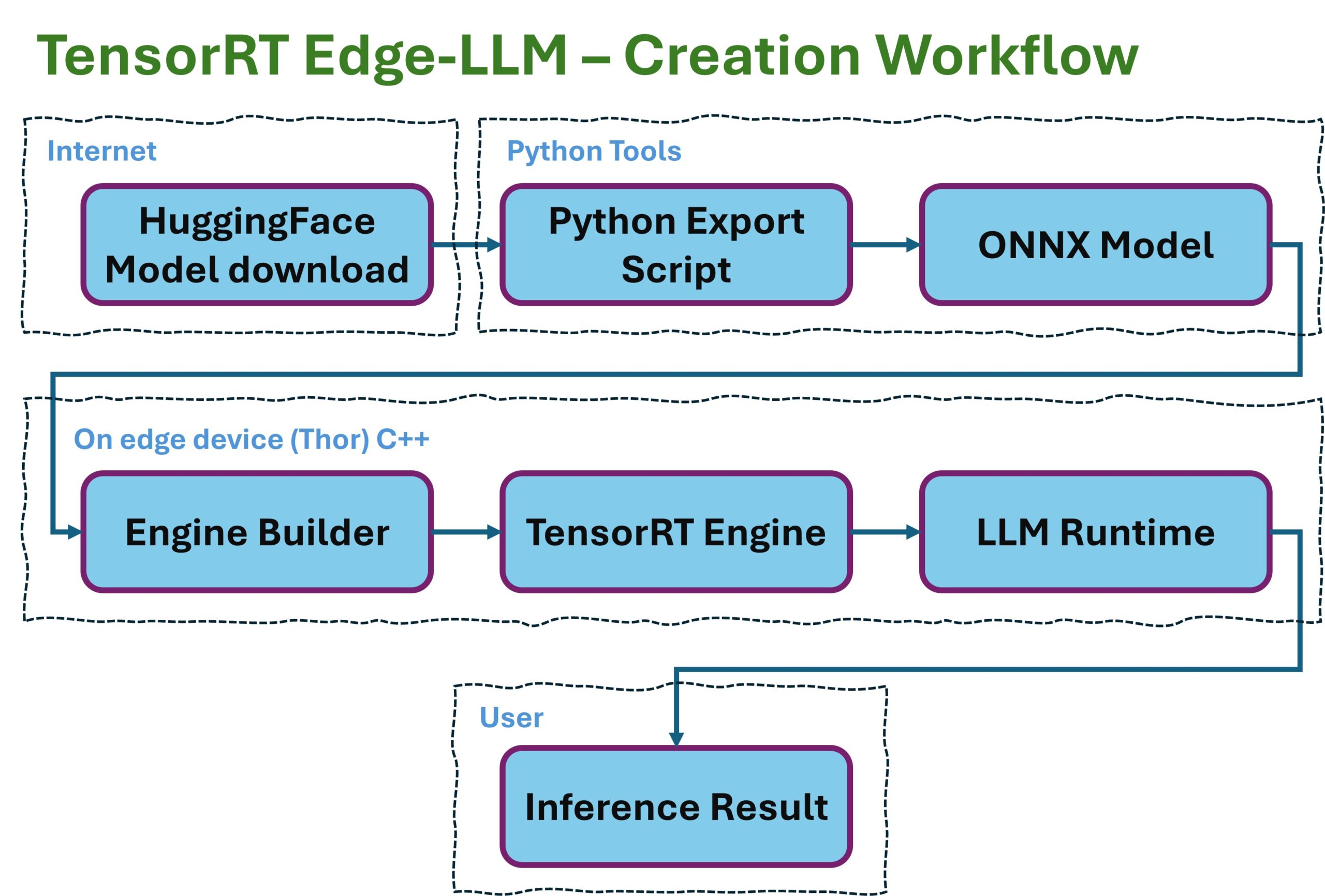
EdgeLLM preparation workflow
Drei Stufen, drei Artefakte. HuggingFace als eines der großten Portale für LLMs ist mit seinen angebotenen LLM-Modellen der portable Input. Genau so wie diese von z. B. der Forschungs-Community oder den großen Playern im Feld veröffentlicht werden. ONNX ist das vendor-neutrale Zwischenformat, das Modell-Struktur und Gewichte beschreibt, aber selbst nichts ausführt. TensorRT Engine ist das hardware-spezifische Endprodukt, das nur noch geladen und ausgeführt wird.
Diese Trennung hat einen wichtigen Grund: Der Engine Builder kann auf jeder x86-Workstation laufen, die das passende CUDA-SDK hat. Die Runtime läuft auf dem Zielgerät (Jetson, DRIVE, oder eben auch RTX). Build und Deploy sind entkoppelt. Das ist exakt das Pattern, das jede Produktions-Pipeline irgendwann braucht.
TensorRT-LLM vs. TensorRT Edge-LLM
Die beiden Projekte sind, vereinfacht gesagt, dieselbe Architektur in zwei Ausführungen. Mit der jetzt folgenden Tabelle versuche ich eine kurze Erläuterung:
| Aspekt | TensorRT-LLM | TensorRT Edge-LLM |
|---|---|---|
| Zielplattform | Datacenter (B200, H200, A100, Ada) | Jetson Thor, DRIVE Thor |
| Runtime | Python + C++ | nur C++ |
| Batching | In-Flight Batching | Single-Stream |
| KV-Cache | Paged, dynamisch | Kompakt, statisch |
| Power-Budget | egal (fast -> Abwärme) | kritisch |
| Modellgröße | bis 405B+ via Tensor-Parallel | typisch 1B–14B |
| Optimierungsziel | Throughput (Tokens/sec über viele User) | Latenz pro Request, vorhersagbar |
| Antwortverhalten | Best-effort, variiert mit Last | Deterministisch, jede Millisekunde zählt |
Edge-LLM ist im Kern „TRT-LLM, dem alles abtrainiert wurde, was auf 50 Watt nicht passt„. Die Pipeline-Konzepte ONNX-Export, Engine-Build, Kernel-Auto-Tuning, KV-Cache-Management, FP8-Quantisierung sind identisch. Wer eines verstanden hat, versteht das andere genau so.
Genau hier setze ich an: Wenn ich mir TRT-LLM auf der A6000 Ada vornehme und die Pipeline einmal vollständig durchspiele, von HuggingFace-Checkpoint bis zur deploybaren .engine-Datei, habe ich die Skills, die ich später für Edge-LLM brauche. Nur die Hardware-Constraints sind anders.
Warum die RTX A6000 Ada eine gute Lernplattform ist
Es ist jetzt nicht so das ich groß eine Wahl gehabt hätte. Denn meine Jetson Nanos die ich noch habe sind jetzt ca. 6 Jahre alt und wie soll ich sagen aus dem Support gelaufen. Also hier drei Gründe warum die RTX A6000 Ada ganz gut passt:
1. Sie ist Ada-Architektur (SM89) und unterstützt Hardware-FP8. Das ist nicht selbstverständlich. Die ältere RTX A6000 (Ampere, SM86) die ich in doppelter Ausführung habe kann das nicht. Auf Ada gibt es die Transformer Engine mit nativen FP8-Tensorkernen was das wichtigste Performance-Feature ist, das man auch von Hopper- und Blackwell-Datacentern kennt. Was ich auf Ada zur FP8-Quantisierung lerne, ist 1:1 auf Jetson Thor übertragbar denn dieser bringt ebenfalls Hardware-FP8 mit.
2. 48 GB VRAM sind genug für sinnvolle Modelle. Ein Qwen-2.5-7B in FP16 frisst ca. 14 GB für die Engine, plus mehrere GB für den KV-Cache. Mit 48 GB habe ich Platz für die Engine, einen großen KV-Cache, und kann sogar parallel nvidia-smi zum Monitoring laufen lassen, ohne dass es eng wird. Das ist auf einer Consumer-Karte mit 24 GB schon deutlich knapper.
3. Sie läuft mit PV-Strom. Meine Inferenz-Server bekommen Solarstrom wenn die Sonne scheint und das ist jetzt ab April fast zu 100% der Fall und in der Nacht kommt der Strom aus dem PV-Akku. Was auf der A6000 Ada an Token generiert wird, kostet mich auch keine Cloud-Gebühren. Ein technisches Detail, aber für mich Teil des größeren Bildes: KI-Infrastruktur, die ich selbst kontrolliere und betreibe, mit Energie, die ich selbst produziere. Das ist die praktische Übersetzung von „Souveränität“ die ich jetzt schon ohne weiteres in Europa erreichen kann.
Was in den nächsten Posts kommt
In den folgenden drei Teilen dieser Serie gehe ich die Implementation Schritt für Schritt durch:
- Teil 2: Installation und Konfiguration: Wie ich TensorRT-LLM in einem Docker-Container auf Ubuntu 24.04 aufgesetzt habe, welche Pfade ich gewählt habe, wie die Helper-Skripte
setup_trtllm.shundstart_trtllm.shaufgebaut sind, und welche Fallstricke ich beim ersten Modell-Test mit TinyLlama umgangen habe. - Teil 3: Die Build-Pipeline und Quantisierungs-Skripte: Wie der zweistufige Workflow
convert_checkpoint.py→trtllm-buildfunktioniert, wie meinebuild_qwen_fp16.shundbuild_qwen_fp8.shSkripte aufgebaut sind, was ModelOpt PTQ macht, und warum ein naiv konfigurierter FP8-KV-Cache mein 7B-Modell zu Token-Salat verwandelt hat. - Teil 4: Messwerte und Lehren: Hier geht es dann um die echten Performance-Zahlen aus meinem Setup (Spoiler: 1.62× Speedup mit FP8, 45 % kleinere Engine), die Erkenntnisse zum Verhältnis zwischen Engine-Build-Zeit und Disk-I/O, und vor allem: Was davon übertrage ich später auf Edge-LLM, was muss ich neu lernen?
Wer mitmachen will, braucht im Minimum eine NVIDIA-GPU mit Ada-Architektur wie z. B. eine RTX 4090 oder neuer (für die FP8-Pfade), CUDA-Treiber ab 545.x, Docker mit NVIDIA Container Toolkit, ein HuggingFace-Konto (für die Modell-Downloads), und etwa 100 GB freien Speicher für Container-Image und Modelle. Mit einer älteren Consumer-Karte funktionieren die FP16-Pfade. Dann muss man den FP8-Teil aber überspringen. Ich habe dem Setup noch eine 16TB Festplatte zur Seite gestellt da ich mehrer Anläufe benötigt habe diese kleine Beitragsserie schreiben zu können.
Im nächsten Teil starten wir mit dem Setup.
Artikelübersicht - TensorRT-LLM auf der RTX A6000 Ada:
Ubuntu 24.04 Server für KI-Inferenz vorbereiten: CUDA, Docker, NVIDIA Container ToolkitTensorRT-LLM auf der RTX A6000 Ada: Vorbereitung auf das Edge-LLM Ökosystem
TensorRT-LLM auf Ubuntu 24.04: Setup mit Docker und Helper-Skripten
TensorRT-LLM Pipeline: Persistente Engines bauen mit FP16 und FP8
TensorRT-LLM in Zahlen: FP16 vs. FP8 auf der RTX A6000 Ada








{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…