
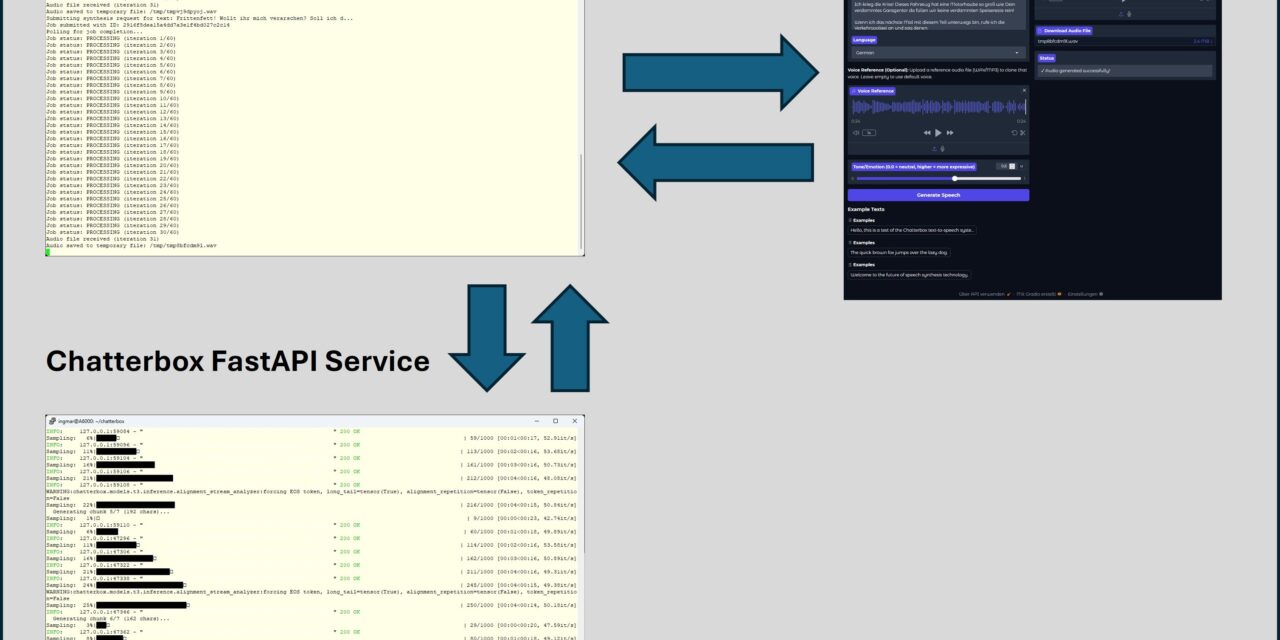
Nach dem im Teil 1 bereits die Lösung im Detail vorgestellt wurde und die Architektur erläutert wurde geht es jetzt im Teil 2 um die Installation und Konfiguration der Lösung.
Installation und Einrichtung der virtuellen Python-Umgebung
Um eine saubere und reproduzierbare Umgebung zu gewährleisten, verwende ich eine dedizierte Python Virtual Environment (venv). Das hat sich bei mir schon mehrfach gelohnt vor allem wenn man noch die richtigen Konfigurationen der Versionen von Bibliotheken finden muss.
Um die Installation des Projektes für euch maximal einfach zu machen habe ich ein kleines Installations-Skript geschrieben das ihr hier auf GitHub findet:
Hinweis: Wenn ihr das install_chatterbox.sh Skript ausführt muss das Python Skript patch_pkuseg.py bereits vorhanden sein. Denn dieses ist für die erfolgreiche Installation notwendig. Sobald die Software einen etwas besseren Entwicklungsstand hat werde ich diese hier veröffentlichen. Aktuell habe ich diese stark mit der Hilfe von Cursor entwickeln lassen und muss mir das Coding noch einmal durchlesen.
https://github.com/custom-build-robots/
Nach dem Ausführen des Skriptes sollte bei euch meine Idee der Umsetzung des Chatterbox-Services bereit sein für die ersten Tests. Das wirklich schöne dabei ist, dass alles in einer isolierten virtuellen Umgebung läuft.
Betrieb der Services
Der eigentliche Betrieb erfordert, dass ihr beide Komponenten also den TTS-Service und den Client (Gradio Web-App) parallel in separaten Sitzungen startet. Ich nutze hierfür zwei separate Terminalfenster, um die Prozesse persistent im Hintergrund auf meinem Server laufen zu lassen.
Start des TTS Service (FastAPI)
Ich aktiviere zuerst die virtuelle Python-Umgebung und starte den TTS-Backend-Service:
source chatterbox_venv/bin/activate
# Start des FastAPI-Services auf Port 8123
python tts_service.py
Der Service initialisiert nun das Chatterbox TTS Modell und ist bereit, API-Anfragen entgegenzunehmen. Bei dem ersten Aufruf wird noch das KI-Modell von Huggingface herunter geladen. Das dauert initial etwsa abhängig von eurer Internetanbindung am Server.
Die Konsole gibt ein paar Informationen aus und zeigt die Bestätigung, dass Uvicorn auf http://0.0.0.0:8123 läuft. Dieser Prozess übernimmt alle GPU-berechneten Aufgaben.
Start des Gradio Frontend
In einem zweiten Terminal, nachdem ich die virtuelle Python-Umgebung erneut aktiviert habe, starte ich das Frontend:
source chatterbox_venv/bin/activate
# Start des Gradio-Frontends auf Port 7123
python gradio_app.py
Das Gradio-Interface ist nun unter http://0.0.0.0:7123 im Browser erreichbar. Es handelt sich um einen reinen Client, der seine gesamte Funktionalität über die HTTP-Verbindung zum FastAPI-Backend auf Port 8123 bezieht.
Praxisbeispiel: Asynchrone API-Nutzung
Die wahre Stärke der entkoppelten Architektur zeigt sich in der direkten Nutzung der RESTful API, die ich hier kurz erläutere.
Job-Initiierung
Ich kann einen TTS-Job direkt per curl initiieren. Hier ist ein einfache Beispiel für die Generierung einer englishen Sprachausgabe da diese der Standard ist wenn nicht übergeben:
Befehl: curl -X POST http://localhost:8123/tts/synthesize -H "Content-Type: application/json" -d '{"text": "Hello, this is a test."}'
Die Antwort des Service enthält sofort die Job-ID und den Status PENDING, da die Synthese im Hintergrund läuft.
{
"chatterbox_id": "91db8acbcf7741439ad0ab0e3653969f",
"status": "PENDING",
"message": "Synthesis job started"
}
Jetzt kommt ein etwas komplexerer Aufruf der auch die Zielsprache übergibt als CURL Beispiel:
Befehl: curl -X POST http://localhost:8123/tts/synthesize -H "Content-Type: application/json" -d '{
"text": "Hello, this is a test of the Chatterbox TTS system.",
"language_id": "en",
"exaggeration": 0.5,
"repetition_penalty": 2.0,
"temperature": 0.8
}'
Statusabfrage und Audio-Download
Mit der erhaltenen chatterbox_id frage ich den Status ab. Ist der Job abgeschlossen, liefert der gleiche Endpunkt die Audio-Datei zurück wenn Du die passende chatterbox_id im Befehl mitgibst:
Befehl: curl http://localhost:8123/tts/status/91db8acbcf7741439ad0ab0e3653969f --output output.wav
Diese API-Struktur ermöglicht eine einfache Integration in andere Workflows, wie zum Beispiel n8n oder ComfyUI, um automatisch generierte Sprache in meine AI-Pipelines einzubinden.
Voice Cloning
In meinem kleinen Gradio Web-Frontend habe ich auch die Option für Voice-Cloning eingebaut. Hier müsst ihr eine kurze Audiodatei idealerweise als WAV Datei von 10 bis 30 Sekunden länge hochladen. Diese wird dann als Stimmenvorlage genutzt für das Voice-Cloning.
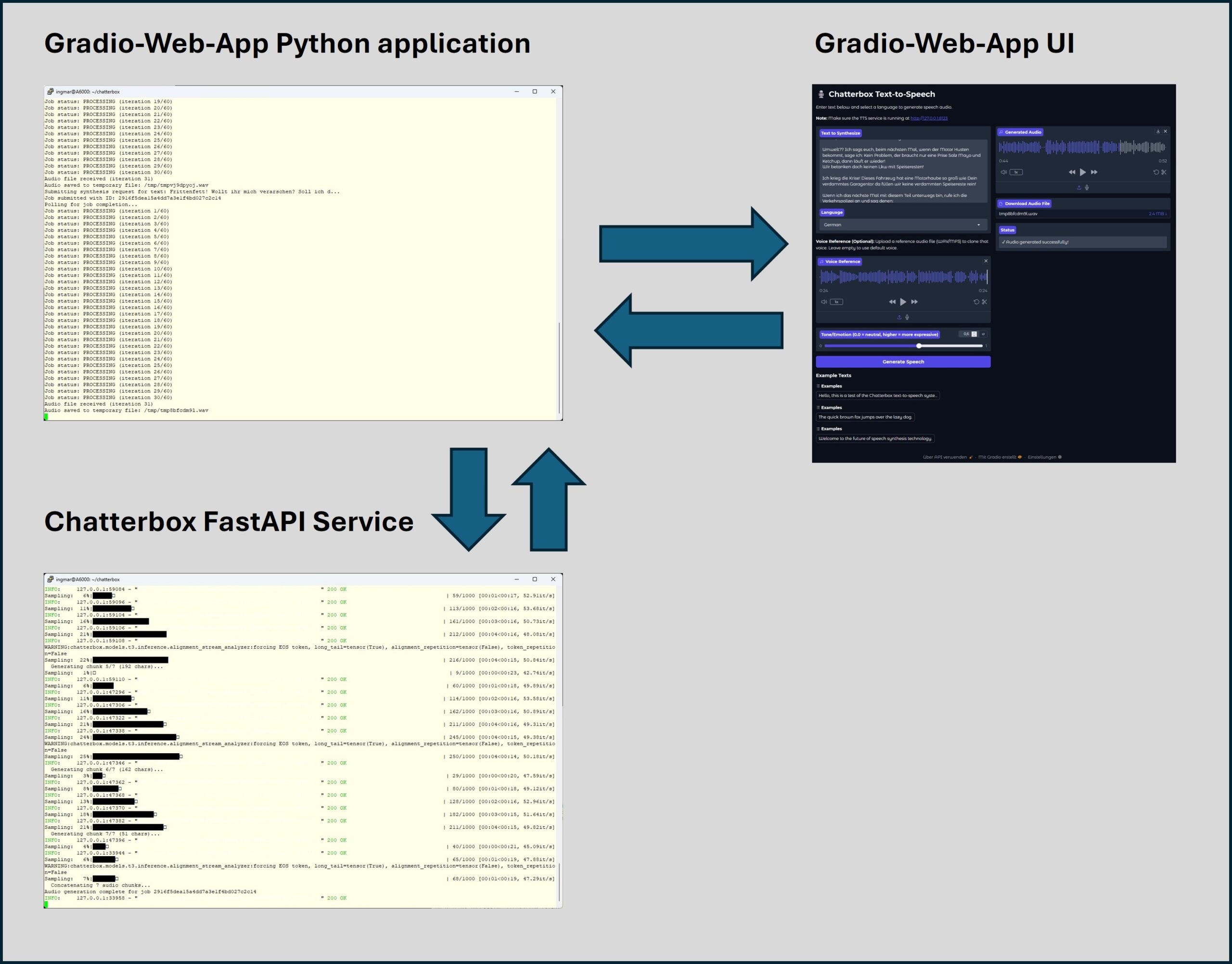
Chatterbox web-app Service Architecture
Zusammenfassung und Fazit
Mit diesem Setup habe ich eine robuste, modulare und leistungsstarke TTS-Lösung auf meinem Ubuntu Server eingerichtet. Durch die strikte Trennung von FastAPI-Backend (Job-Management) und Gradio-Frontend (Client) nutze ich meine NVIDIA GPU effizient und sorge dafür, dass diese Lösung leicht von verschiedenen Clients aufgerufen werden kann.
Die persistente Speicherung der Jobs im Dateisystem gewährleistet, dass keine Ergebnisse verloren gehen, selbst wenn einer der Services neu gestartet werden muss. Das System ist nun bereit, mehrsprachige Sprachausgabe in hoher Qualität zu generieren und kann dank der klaren REST-API in beliebige andere Anwendungen integriert werden.
Hier geht es zu Teil 1 der Beitragsserie zu meiner kleinen Chatterbox Web-Anwendung.








{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…