

Im vorherigen Teil habe ich beschrieben, warum ich mir TensorRT-LLM auf meiner RTX A6000 Ada vornehme: als praktische Vorbereitung auf das Edge-LLM-Ökosystem, mit der ich später auf Jetson Thor und Co. nicht bei Null anfangen muss. In diesem Teil geht es um die konkrete Installation und Konfiguration auf einem Ubuntu-24.04-Server. Also exakt um das Setup was es später ermöglicht die Build-Pipeline aufzubauen.
Wer jetzt das kleine Wochenendeprojekt mitmachen will, sollte folgende Vorbedingungen haben:
- Ubuntu als Betriebssystem
- NVIDIA-Treiber 545.x oder neuer
- Docker, NVIDIA Container Toolkit
- mindestens 100 GB freier Speicher für Container-Image und Modelle.
Ich gehe davon aus, dass das Basis-Setup steht falls nicht, holt mein eigenes server_setup.sh das ich hier (Ubuntu 24.04 Server für KI-Inferenz vorbereiten: CUDA, Docker, NVIDIA Container Toolkit) beschrieben habe und holte die Vorbereitung nn einem Rutsch nach.
Warum der Container-Weg statt nativer Installation
Bevor ich mit der eigentlichen Installation anfange, kurz die Begründung für den Container-Ansatz: TensorRT-LLM hat sehr spezifische Abhängigkeiten an CUDA-Toolkit, cuDNN, TensorRT-Version, PyTorch-Build mit passender ABI. Die wheels auf PyPI sind gegen PyTorch 2.9.1 mit CUDA 13.0 gebaut. Wer das nativ installiert, manövriert sich schnell in einen Versions-Sumpf, in dem ein einziges pip install die ganze Python-Umgebung zerlegt. Mit der Zeit und vielen neuen grauen Haaren habe ich mich für den Weg über die Dontainer entschieden. Es spart einem einfach extrem viele Nerven.
Der NGC Release Container löst das für Dich: NVIDIA paketiert alles, was zusammen funktioniert, in ein 20-GB-Docker-Image. CUDA-Toolkit, cuDNN, TensorRT, PyTorch, TRT-LLM selbst, alle Examples, die trtllm-build-CLI. In diesem Container ist alles drin was wir für dieses Projekt brauchen. Auf dem Host-Rechner von Dir braucht es nur Treiber, Docker, das NVIDIA Container Toolkit und eine GPU idealerweise mit Ada Unterstützung. Die Update-Strategie des Setups wird zu „Image-Tag wechseln“ und es ist so ohne Probleme übertragbar von meinem System auf Dein System wenn Du dieser Anleitung folgst.
Der Befehl lautet dann:
Befehl: docker pull nvcr.io/nvidia/tensorrt-llm/release:1.2.1
Welcher Tag aktuell stabil ist, schaut man unter catalog.ngc.nvidia.com nach. Tags wie 1.3.0rc14 sind Release Candidates. Bei dem Tag rcXX gilt Finger weg für Produktiv-Nutzung. Plain-Tags wie 1.2.1 ohne Suffix sind die offiziellen Releases die wir verwenden möchten.
Sanity Check: Deine GPU ans Tageslicht bringen
Vor dem 20-GB-Pull lohnt sich eine schnelle Prüfung, ob alles bereit ist. Denke hier auch an meinem Blog-Post zum Setup des Servers:
nvidia-smi # GPU + Treiber-Version
docker --version # Docker installiert?
docker run --rm --gpus all ubuntu:24.04 nvidia-smi # GPU im Container sichtbar?
df -h /var/lib/docker # mindestens 50 GB freiDer dritte Befehl ist der wichtige: Er beweist, dass das NVIDIA Container Toolkit korrekt eingerichtet ist und Docker-Container Zugriff auf die GPU haben. Wenn das fehlschlägt passt etwas mit Deinem Setup noch nicht.
Bei mir zeigt das nach dem ersten Befehl NVIDIA RTX 6000 Ada Generation, 49140 MiB die professionelle Ada-Karte mit 48 GB. Treiber-Version sollte mindestens 545.x sein.
Verzeichnis-Layout
Bevor ich den Container starte, lege ich auf dem Host eine saubere Verzeichnis-Struktur an, die ich später ins Container-Inneren mounte. Hier muss jeder für sich entscheiden wo die Daten abgelegt werden. Der Einfachheit halber schreibe ich alles direkt auf die root-Partition auf oberster ebene:
Befehl: sudo mkdir -p /data/trtllm/
Befehl: sudo chown -R $USER:$USER /data/trtllm
Das ich dieses Verzeichnis angelegt habe hat zwei Gründe:
Persistenz. Beim Container-Stopp gehen sonst Modell-Downloads und gebaute Engines verloren. Das wäre besonders ärgerlich bei Modell-Downloads. Denn ein Qwen-7B-Checkpoint ist alleine schon 14 GB groß, ein erneuter Download dauert je nach Anbindung dann wieder extra ein paar Minuten.
Zugänglichkeit vom Host. Wenn die Engines auf dem Host-Filesystem liegen, kann ich diese sehr einfach über das Dateisystem meines Betriebssystems inspizieren, sichern, oder über scp auf einen anderen Server schieben ohne den Container überhaupt zu starten und zu betreten. Das ist genau der Build-vs-Deploy-Pattern, den auch Edge-LLM nutzt.
Der Container bekommt später dieses Mount-Mapping:
/data/trtllm (Host) ⇄ /workspace (Container)
Innerhalb des Containers ist also alles unter /workspace zu finden. Außerhalb auf dem Host also euer Dateisystem unter /data/trtllm. Gleiche Daten, zwei Sichtweisen.
HuggingFace Token einrichten
Für die meisten offenen Modelle (Qwen, Mistral) braucht es keinen Token auf HuggingFace. Für Llama und Llama-Derivate (auch die FP8-Varianten von NVIDIA) muss man auf HuggingFace einmalig die Lizenz des jeweiligen Modell-Anbieters akzeptieren und einen Read-Token erstellen. Bei mir ist das teilweise schon ein paar Jahre und ich hatte zunächst gar nicht mehr daran gedacht bis das HF-Token verlangt wurde.
Hinweis: Wenn Du noch kein Token für die Modelle hast dann einmal bei HF anmelden und unter huggingface.co/settings/tokens anlegen, dann persistent ablegen:
echo 'export HF_TOKEN="hf_xxxxxxxxxxxxxxxxxxxxx"' >> ~/.env_trtllm
chmod 600 ~/.env_trtllmDie separate Datei statt direkt in .bashrc macht es einfacher, den Token später zu rotieren und schützt vor versehentlichem Einchecken in ein Repo. Es ist so einfach der Standard Weg um seine Keys zu verwalten.
Helper-Skripte: setup_trtllm.sh und start_trtllm.sh
Alle jetzt notwendigen Befehle in einer einzigen Befehlsfolge auszuführen, wird schnell unübersichtlich. Deshalb habe ich zwei Helper-Skripte gebaut. Diese habe ich selber auch gebraucht um mich durch die vielen Stolperstellen zu bewegen und die Befehle und deren Reihenfolge immer vor Augen zu haben:
setup_trtllm.sh – Für die einmalige Installation
Das setup_trtllm.sh automatisiert den kompletten First-Run:
- Sanity Check: Treiber-Version, GPU-Erkennung (mit FP8-Hinweis falls Ada/Hopper), Docker, GPU-Passthrough in den Container, Plattenplatz
- HuggingFace-Token-Setup: wenn nicht gesetzt, interaktive Abfrage, speichern in
~/.env_trtllmmitchmod 600 - Verzeichnisse:
/data/trtllm/mit den richtigen Permissions anlegen - Container-Pull:
docker pullmit der konfigurierten Version
Hinweis: Jetzt ist es so, bis ich soweit war habe ich dieses Skript x-Mail ausgeführt. Soll heißen es ist so gebaut das ein mehrfaches Ausführen sicher ist. Wenn das Image schon da ist, wird kein erneuter Pull versucht da das wieder je nach Internetanbindung sehr lange dauern kann. Wenn die Verzeichnisse existieren, werden sie nicht überschrieben.
Jetzt bitte das Skript setup_trtllm.sh herunter laden und ausführen damit Dein Server entsprechend aufgesetzt und vorbereitet wird.
Hier geht es zu dem Skript auf GitHub: tensorrt-llm-prep-script
Ich gehe ab jetzt davon aus, dass alle Skripte die Du im Verlauf dieses Beitrages herunter lädtst in Deinem Arbeitsverzeichnis abgelegt werden das bei mir /data/trtllm/ ist.
Das Skript selber führt ihr wie folgt aus:
Befehl: chmod +x setup_trtllm.sh
Befehl: ./setup_trtllm.sh
start_trtllm.sh – Container-Lifecycle
Das start_trtllm.sh ist für den täglichen Betrieb des Containers gedacht und wird erneut ausgeführt wenn der Container nicht laufen sollte.
Hier geht es zu dem Skript auf GitHub: tensorrt-llm-prep-script
Befehl: chmod +x start_trtllm.sh
Befehl: ./start_trtllm.sh
./start_trtllm.sh # detached starten (default)
./start_trtllm.sh shell # interaktiv (--rm, bash) für Quick-Tests
./start_trtllm.sh exec # in laufenden Container reinspringen
./start_trtllm.sh status # Container-Status + GPU-Auslastung
./start_trtllm.sh logs # docker logs -f
./start_trtllm.sh stop # Container stoppenHinweis: Der Default startet den Container detached mit --restart unless-stopped. Damit überlebt er Server-Neustarts und ich kann einfach ./start_trtllm.sh exec machen um den laufenden Container zu betreten, wenn ich was zu testen habe.
Die Docker-Run-Optionen, die wichtig sind hier kurz erklärt:
docker run -d \
--gpus all \
--ipc=host \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
-p 8000:8000 \
-v /data/trtllm:/workspace \
-e HF_TOKEN="${HF_TOKEN}" \
-e HF_HOME=/workspace/cache \
--name trtllm \
--restart unless-stopped \
nvcr.io/nvidia/tensorrt-llm/release:1.2.1 \
sleep infinity--ipc=host und die --ulimit-Optionen sind für die MPI-Kommunikation zwischen TRT-LLM-Workern wichtig auch bei Single-GPU-Inferenz nutzt TRT-LLM intern MPI. Dazu dann gleich etwas mehr. Der Port -p 8000:8000 ist für später (wenn wir trtllm-serve als OpenAI-kompatiblen Server starten). Der HF_HOME ins Volume macht den Modell-Cache persistent um eben nicht immer wieder die Modelle von HF herunter laden zu müssen.
Erster Modell-Test mit TinyLlama
Nach dem ersten ./setup_trtllm.sh und ./start_trtllm.sh sollte alles laufen. Um den Container zu betreten bitte den folgenden Befehl ausführen:
Befehl: ./start_trtllm.sh exec
python3 -c "import tensorrt_llm; print(tensorrt_llm.__version__)"
# 1.2.1
nvidia-smi
# zeigt die A6000 Ada mit 48 GBIhr solltet jetzt in etwas folgendes in eurem Terminal Fenster sehen.
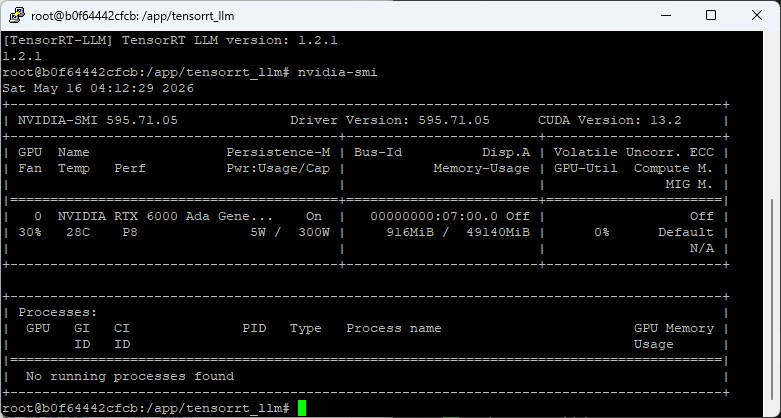
Tensor RT LLM – container test
Als Smoke-Test werden wir jetzt ein winziges Modell nämlich das TinyLlama mit 1.1 Milliarden Parametern im Container ausführen. Dieses ist ungefähr 2 GB groß und muss herunter geladen werden. Damit das ganze klappt musst Du jetzt innerhalb des Containers in das Arbeitsverzeichnis „workspace“ wechseln.
Befehl: cd /workspace
Damit Du den Smoke test ausführen kannst brauchst Du noch das smoke.py Python-Programm. Das gibt es hier.
Download: tensorrt-llm-edge-prep-script
Anschließne die Python Datei smoke.py ausführen.
Befehl: python smoke.py
Beim ersten Start des Skriptes wird das Modell herunter geladen das ca. 2 GB groß ist. Dann dauert es ca. eine Minute für das Modell-Init und dann werden zwei generierte Sätze erzeugt wer sich das Skript angeschaut hat, hat das sicher gesehen. TinyLlama spricht praktisch kein Deutsch. Daher sind die Outputs häufig Nonsense („Peter und bin 25 Jahre alt…“). Das ist okay, der Smoke-Test prüft die Pipeline, nicht die Modell-Qualität. Wir wollten damit nur wissen ob alles funktioniert.
Wenn das Skript erfolgreich durchlaufen wurde gibt es zum Schluss folgende Erfolgsmeldung aus.
=== Smoke Test erfolgreich abgeschlossen ===
Die MPI-Falle: if __name__ == '__main__': ist Pflicht
Ein Stolperstein, an dem ich beim ersten Versuch hängen geblieben bin war, dass TensorRT-LLM intern MPI (Message Passing Interface) für seine Worker-Prozesse nutzt. Das MPI Protokoll wird auch bei Single-GPU-Inferenz angewandt. Das hat entsprechende Auswirkungen auf jedes Python-Script, das die LLM-API direkt verwendet.
Wer den Code so schreibt, wie man es naiv tun würde:
# FALSCH — funktioniert nicht!
from tensorrt_llm import LLM, SamplingParams
llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0")
sp = SamplingParams(max_tokens=64)
# ...…bekommt beim Ausführen einen abrupten Abbruch:
The main script or module attempted to spawn new MPI worker processes.
This probably means that you have forgotten to use the proper idiom...
if __name__ == '__main__':Der Grund: TRT-LLM startet beim Initialisieren des LLM-Objekts Worker-Prozesse mit multiprocessing.spawn. Wenn das Hauptskript nicht durch if __name__ == '__main__': geschützt ist, versuchen die Worker den ganzen Modul-Code (inklusive LLM(...)-Aufruf) noch einmal auszuführen was dann wiederum zu einem Endlos-Spawn führt. Zum Glück erkennen die Python MPI-Bindings dieses Verhalten und brechen dann direkt den Prozess ab.
Der Fix war dann recht schnell gemacht. Den Python für llm… in eine main()-Funktion packen und mit dem Guard starten:
def main():
llm = LLM(...)
# ...
if __name__ == '__main__':
main()Das ist nicht TRT-LLM-spezifisch, sondern Python-Standard für alles, was mit multiprocessing arbeitet. Aber wer wie ich sich das Thema gerade erarbeitet und aus dem Ollama-Stil als Anwender kommt kann hier schnell in ein Problem laufen.
Die zwei Backends in TRT-LLM 1.x
Beim Lesen der Logs ist mir dann noch folgendes aufgefallen was ich etwas genauer nachlesen musste.
[TRT-LLM] [I] Using LLM with PyTorch backendHeißt: TRT-LLM 1.x hat zwei parallele Backends, und die Standard-API verwendet seit 1.x den PyTorch-Backend, der gar keine TensorRT-Engine baut. Stattdessen führt er das Modell mit PyTorch + optimierten Kernels aus ähnlich wie vLLM. Schnell aufgesetzt, gut für Iteration, aber kein deploybares Engine-Artefakt. So habe ich nie eine Datei gefunden die auf .engine endet.
Den klassischen TensorRT-Backend das wir aber brauchen, das auch Edge-LLM nutzt und der auch wirklich eine .engine-Datei erstellt bekommt man durch einen anderen Import:
from tensorrt_llm._tensorrt_engine import LLM # TensorRT Backend# vs.
from tensorrt_llm import LLM # PyTorch Backend (default)Das ist eine architektonische Verzweigung, die mir nicht aufgefallen war und ich wirklich etwas suchen musste. Für mein Ziel das ich mir gesetzt habe die Edge-LLM-äquivalente Pipeline auf der A6000 Ada durchzuspielen ist das TensorRT-Backend genau das richtige. Für schnelle Experimente reicht das PyTorch-Backend.
Skript-Inventur nach Teil 2
Nach diesem Teil solltet ihr wie ich auf eurem Server die folgenden drei Skripte liegen haben und alle auch erfolgreich ausgeführt haben:
/data/trtllm/setup_trtllm.sh— einmaliges Setup/data/trtllm/start_trtllm.sh— Container-Lifecycle/data/trtllm/smoke.py— Validierungs-Test mit TinyLlama
Im Container sind diese Skript dank dem persistenten Mound auf euer lokales Dateisystem sichtbar als /workspace/setup_trtllm.sh, /workspace/start_trtllm.sh, /workspace/smoke.py. Die Skripte sind unter MIT-Lizenz frei verfügbar und auf GitHub hochgeladen.
Im nächsten Teil geht es ans Eingemachte: die zweistufige Build-Pipeline mit convert_checkpoint.py und trtllm-build, eigene Build-Skripte für FP16 und FP8 und die Geschichte, wie meine erste FP8-Engine ein perfekt schnelles, völlig unleserliches Token-Salat-Monster wurde.
Artikelübersicht - TensorRT-LLM auf der RTX A6000 Ada:
Ubuntu 24.04 Server für KI-Inferenz vorbereiten: CUDA, Docker, NVIDIA Container ToolkitTensorRT-LLM auf der RTX A6000 Ada: Vorbereitung auf das Edge-LLM Ökosystem
TensorRT-LLM auf Ubuntu 24.04: Setup mit Docker und Helper-Skripten
TensorRT-LLM Pipeline: Persistente Engines bauen mit FP16 und FP8
TensorRT-LLM in Zahlen: FP16 vs. FP8 auf der RTX A6000 Ada







{kind=link}
Ein toller Guide der leicht zugänglich und verständlich ist. Perfekt für ein kleines Side-Project geeignet. Aktuell half mir noch mein…
Thank you for this great tutorial, could you share n8n workflow and comfyui workflow please?
Hallo Anton, die Meldung besagt das in meinem Beisiel Methoden verwendet werden die veraltet (deprecated) sind. Also müsstest Du die…
Danke für das Tool! Ich habe erst kürzlich angefangen mich mit der Thematik zu beschäftigen und bin für meine Erwartungen…
Hallo, ich habe ihre Anleitung befolgt und bekomme im letzten Schritt leider immer folgende Meldung im Terminal: bash <(wget -qO-…